Lombard 효과를 고려한 딥러닝 기반 시청각 음성 향상
초록
본 연구는 배경소음 속에서 발생하는 Lombard 효과가 오디오·비디오 결합 음성 향상(A‑V‑SE) 시스템에 미치는 영향을 분석한다. 54명의 화자를 대상으로 한 Lombard GRID 코퍼스를 이용해, Lombard 음성으로 학습한 모델이 저신호대잡음비(SNR) 환경에서 비음성·시각 정보 모두를 활용할 때 음성 품질과 인식 가능성을 크게 향상시킴을 확인하였다. 남·여 화자 간의 Lombard 특성 차이도 성별별 성능 차이로 나타났다.
상세 분석
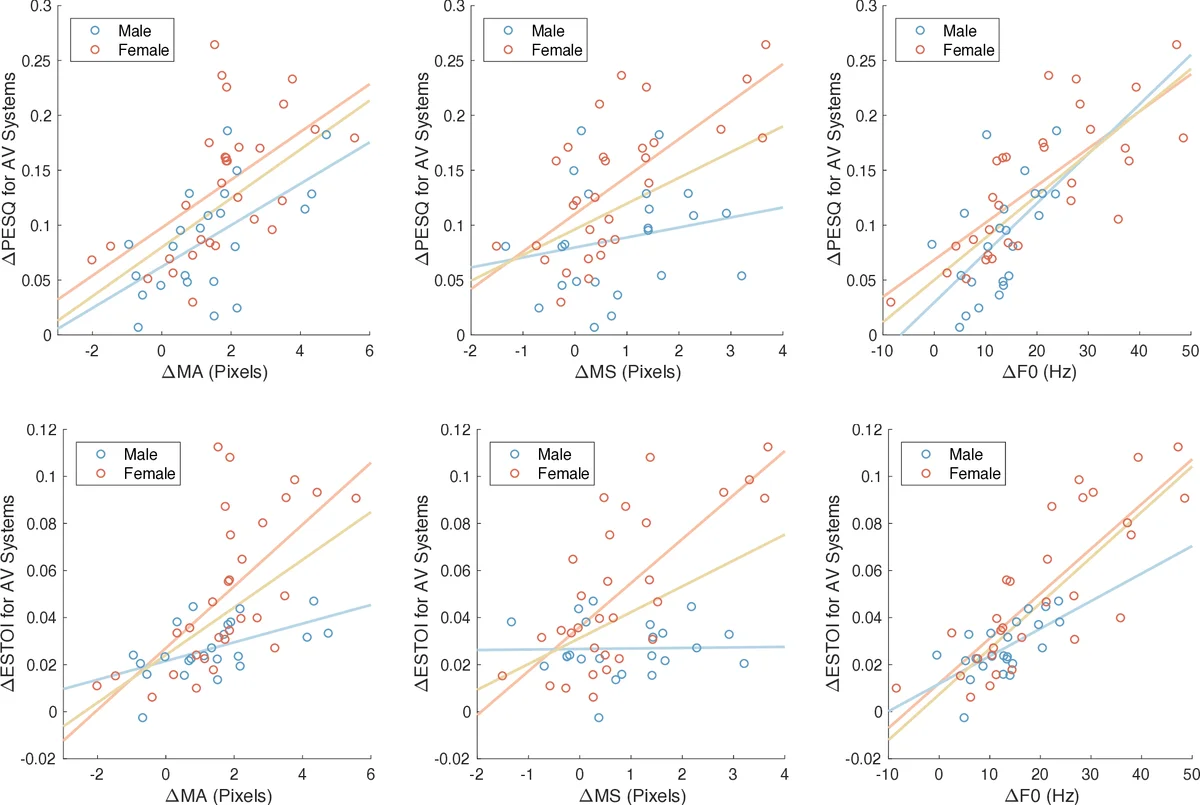
이 논문은 기존 음성 향상 연구가 대부분 조용한 환경에서 녹음된 음성을 사용하고, 인공적으로 잡음을 추가하는 방식에 의존해 왔다는 점을 비판한다. 실제 대화 상황에서는 화자가 자동으로 Lombard 효과를 보이며, 특히 고음역대 에너지 증가와 입술·턱 움직임 확대가 특징이다. 이러한 변화를 무시하면 학습된 모델이 실제 사용 환경에서 최적의 성능을 발휘하지 못한다는 것이 저자들의 가설이다.
데이터셋은 Lombard GRID 코퍼스로, 25명의 남성 및 30명의 여성 화자가 각각 50개의 비Lombard(NL)와 50개의 Lombard(L) 문장을 녹음하였다. Lombard 조건은 80 dB SPL의 Speech Shaped Noise(SSN)를 청취자와 함께 제공함으로써 자연스러운 대화 상황을 재현하였다. 오디오 샘플링 레이트는 16 kHz, 비디오 해상도는 720×480 픽셀, 프레임 레이트는 약 24 FPS이며, 전면 카메라 영상을 사용해 입술 영역(128×128 픽셀)만을 추출하였다.
모델 구조는 기존 연구(Gabbay et al., 2018)를 그대로 채택했으며, 오디오와 비디오 각각 6계층의 컨볼루션 인코더와, 두 인코더 출력을 결합하는 3계층 완전연결 서브네트워크, 그리고 6계층 전치 컨볼루션 디코더로 구성된다. 입력은 5프레임(200 ms) 비디오와 20프레임(200 ms) 오디오 스펙트럼이며, 마스크 추정 방식은 이상 진폭 마스크(IAM)를 목표로 하는 L2 손실 함수를 사용한다. 학습은 Adam 옵티마이저(초기 학습률 4×10⁻⁴)와 early‑stopping을 적용했으며, 마스크 값은
댓글 및 학술 토론
Loading comments...
의견 남기기