K‑스텝 평균 SGD의 비볼록 최적화 수렴 특성
초록
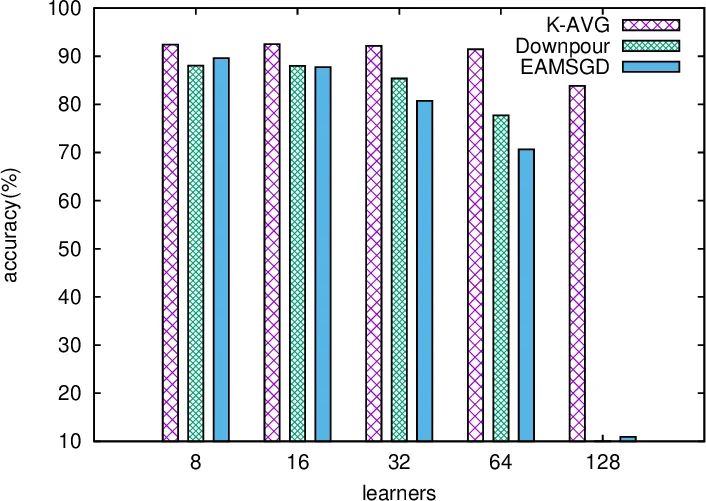
본 논문은 동기식 K‑step 평균 SGD(K‑AVG) 알고리즘을 제안하고, 비볼록 목적함수에 대해 수렴 이론을 정립한다. K‑step 지연이 기존 동기식 SGD(K=1)보다 통신 비용을 줄이며 더 큰 학습률을 허용하고, 프로세서 수가 증가할 때 ASGD보다 확장성이 우수함을 보인다. CIFAR‑10 실험에서 128 GPU 환경에서 K‑AVG가 ASGD 대비 학습 속도와 정확도 모두 개선됨을 확인하였다.
상세 분석
논문은 먼저 비볼록 최적화 문제를 다루기 위해 네 가지 표준 가정을 설정한다. 목적함수 F는 L‑Lipschitz 연속 gradient를 가지며, stochastic gradient는 편향이 없고 제한된 분산 M을 가진다. 이러한 전제 하에 K‑step 평균 SGD 알고리즘을 정의한다. 각 프로세서는 K번의 로컬 SGD 업데이트를 수행한 뒤 전역 평균을 계산하고, 이를 모든 프로세스에 동기화한다. K=1이면 기존의 하드‑싱크 SGD와 동일하고, K>1이면 통신 주기가 늘어나면서 연산과 통신이 보다 효율적으로 배분된다.
수렴 분석에서는 고정 학습률과 고정 배치 크기 경우에 대한 기대 평균 제곱 그래디언트 노름의 상한을 도출한다(정리 3.1). 결과식은 초기 손실 차이, 학습률 γ, 배치 크기 B, 프로세서 수 P, 그리고 K에 대한 함수로 구성된다. 특히 두 번째 항은 1/P와 1/B에 비례해 감소하므로, 프로세서 수가 늘어날수록 변동성이 감소한다는 점을 강조한다. 그러나 K가 너무 작으면 통신 오버헤드가 커져 전체 효율이 떨어질 수 있다.
정리 3.2에서는 감소하는 학습률과 증가하는 배치 크기를 적용했을 때 기대 제곱 그래디언트가 0으로 수렴함을 보인다. 이는 비볼록 문제에서도 전통적인 SGD와 동일한 O(N⁻¹/²) 수렴 속도를 유지하면서, K‑step 지연으로 인한 통신 절감 효과를 얻을 수 있음을 의미한다.
ASGD와의 비교에서는 스테일니스(gradient staleness)가 프로세서 수 P에 의해 제한된다는 점을 이용해, ASGD의 수렴 상한이 O(1/P²)로 감소하는 반면 K‑AVG는 O(1/P) 스케일링을 보인다(정리 3.3). 따라서 대규모 GPU 클러스터에서 K‑AVG가 더 좋은 확장성을 가진다.
마지막으로 최적 K값에 대한 논의(정리 3.4)에서는 전체 처리된 샘플 수 NK가 일정할 때 K를 크게 잡을수록 통신 비용이 크게 감소하지만, 너무 큰 K는 전역 파라미터 업데이트 빈도를 낮춰 수렴 속도를 저하시킬 수 있다. 실험 결과는 K가 1보다 큰 경우에도 오히려 더 빠른 수렴과 높은 최종 정확도를 달성함을 보여, “더 자주 평균한다=더 빠른 수렴”이라는 일반적인 믿음에 반한다.
전반적으로 논문은 K‑step 평균 SGD가 비볼록 최적화에서 이론적 수렴 보장을 제공하면서, 실무적인 통신 효율과 학습률 선택 폭을 넓혀 ASGD보다 실질적인 성능 향상을 가능하게 함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기