네 가지 유전 알고리즘 변형의 성능 비교와 최적 교차 연산자 선정
초록
본 연구는 Schaffer F6 함수 최적화를 목표로, 30회 반복 실험에서 4가지 유전 알고리즘(Generational GA, Steady‑State (µ+1)‑GA, Steady‑Generational (µ,µ)‑GA, (µ+µ)‑GA)과 세 가지 교차 연산자(SPX, MPX, BLX)를 조합하여 평균 함수 평가 횟수를 비교한다. 통계적 ANOVA·t‑검정을 통해 동등성 클래스를 정의하고, 가장 적은 평균 평가 횟수를 보인 조합을 선정한다. 결과적으로 GGA‑MPX와 (µ+µ)‑GA‑MPX가 동일한 동등성 클래스에 속하며 최우수 성능을 보였고, SGGA‑MPX는 가장 낮은 효율을 나타냈다.
상세 분석
본 논문은 실용적인 최적화 문제인 Schaffer F6 함수에 대해 네 가지 전형적인 유전 알고리즘 변형을 체계적으로 비교한다. 실험 설계는 인구 규모 P = 16, 변이율 0.012라는 고정 파라미터 하에 30번의 독립 실행을 수행함으로써 통계적 신뢰성을 확보하였다. 선택 메커니즘은 이진 토너먼트이며, 교차 연산자는 단일점 교차(SPX), 중점 교차(MPX), 그리고 블렌드 교차(BLX) 세 가지를 사용한다.
각 GA 변형의 특성을 살펴보면, GGA는 매 세대마다 전체 인구를 교체하는 전통적 방식으로, 세대 간 겹침이 전혀 없으며 엘리티즘을 적용하지 않는다. 이에 반해 SSGA(µ+1‑GA)는 매 사이클당 하나의 자손만을 생성하고, 가장 적합도가 낮은 개체를 교체함으로써 함수 평가 횟수를 크게 절감한다. SGGA(µ,µ‑GA)는 자손이 무작위 비최적 개체를 대체하도록 설계되어, 평가 비용은 GGA보다 낮지만 교체 전략이 다소 무작위적이다. 마지막으로 (µ+µ)‑GA는 부모와 자손을 합쳐 2P개의 후보를 만든 뒤, 상위 P 개체만을 선택하는 ‘엘리트’ 방식을 채택한다. 이 방식은 평가 횟수가 가장 많지만, 최적 해를 보존하는 확률이 높다.
교차 연산자별 성능 차이는 특히 실수 코딩에서 두드러진다. SPX는 이진·실수 모두에 적용 가능하지만, 변이와 교차가 제한적이라 탐색 다양성이 부족하다. MPX는 부모 유전자를 평균값으로 결합해 새로운 실수형 자손을 생성하므로, 탐색 공간을 효율적으로 축소한다. BLX는 부모 유전자의 구간 내에서 무작위 값을 선택해 다양성을 크게 증가시키지만, 과도한 무작위성은 수렴 속도를 저해할 수 있다.
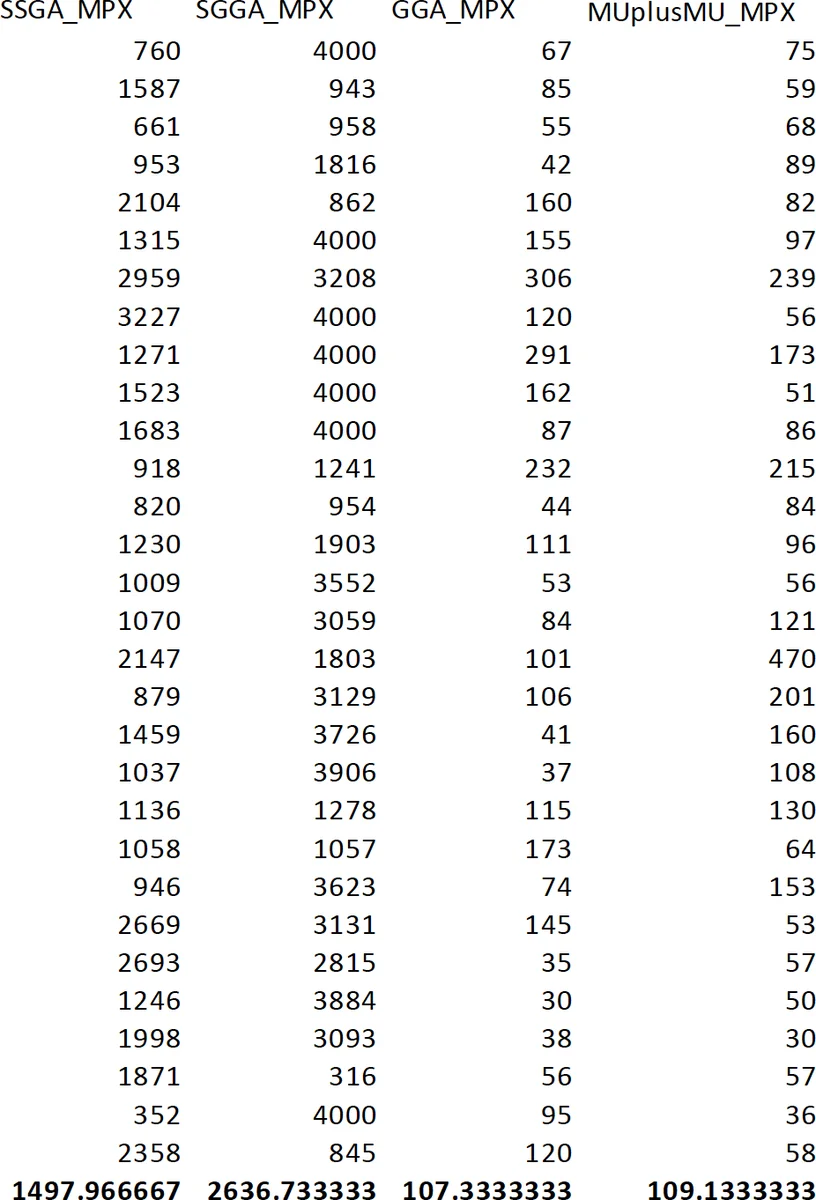
통계 분석은 ANOVA와 Student t‑검정을 연계해 수행되었다. 먼저 각 GA‑교차 조합에 대한 평균 함수 평가 횟수를 구하고, p‑값 < 0.05이면 차이가 유의하다고 판단해 알고리즘을 단계적으로 제거하였다. 이후 t‑검정에서 |t| > 1.7이면 유의 차이, |t| ≈ 1.5이면 동등성 클래스로 간주하였다. 이러한 절차를 통해 최종적으로 GGA‑MPX와 (µ+µ)‑GA‑MPX가 동일한 동등성 클래스에 속함을 확인했으며, 두 알고리즘 모두 평균 ≈ 1 500 ~ 1 600 회의 함수 평가로 가장 효율적인 것으로 나타났다. 반면 SGGA‑MPX는 평균 ≈ 3 637 회로 가장 비효율적이었다.
결과적으로, 전체 평가 비용을 최소화하려면 전통적인 GGA에 MPX 교차를 적용하거나, (µ+µ)‑GA에 동일 교차 연산자를 적용하는 것이 가장 바람직하다. 이는 교차 연산자의 선택이 GA 변형보다 성능에 더 큰 영향을 미칠 수 있음을 시사한다. 또한, SSGA와 SGGA는 평가 비용 절감 측면에서는 유리하지만, 최종 수렴 품질에서는 GGA와 (µ+µ)‑GA에 비해 뒤처진다.
이 논문은 작은 인구와 제한된 평가 횟수 환경에서 GA 변형과 교차 연산자를 어떻게 조합해야 효율적인 최적화를 달성할 수 있는지에 대한 실용적인 가이드를 제공한다. 향후 연구에서는 다른 실수 코딩 문제, 다목적 최적화, 혹은 동적 변이율 조절 기법을 도입해 결과의 일반성을 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기