혼합 정밀도 연산을 활용한 H행렬 벡터 곱 가속화
초록
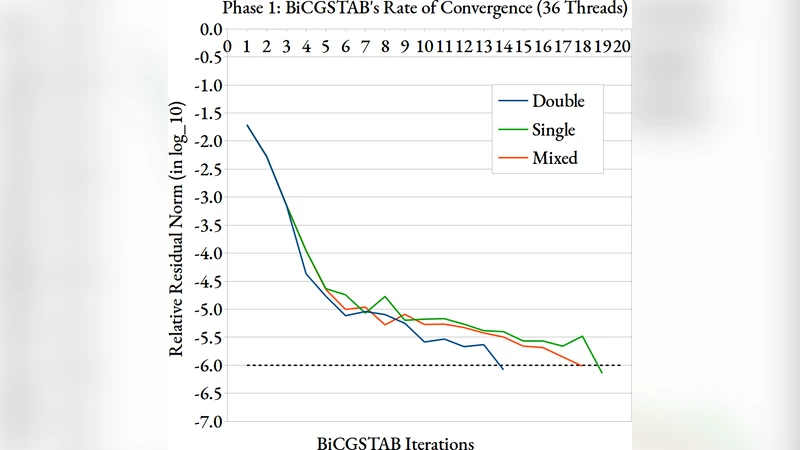
본 논문은 H‑행렬 기반 벡터 곱 연산에 FP64와 FP32를 혼합해 사용함으로써 계산 시간을 단축하고, 경계요소법(BEM) 시뮬레이션에서 BiCG‑STAB 선형 솔버의 수렴 특성을 유지할 수 있음을 실험적으로 입증한다. 세 가지 혼합 정밀도 적용 방식을 제안하고, 각각의 정확도와 성능 영향을 정량적으로 분석한다.
상세 분석
H‑행렬은 밀집 행렬을 블록 구조로 분할하고, 저‑랭크 근사를 적용할 수 있는 블록을 선택적으로 압축함으로써 O(N log N) 수준의 메모리와 연산 복잡도를 달성한다. 이러한 구조는 경계요소법(BEM)과 같이 전역 상호작용을 필요로 하는 분야에서 특히 유용하지만, 실제 연산 단계에서는 여전히 고정밀(64‑bit) 부동소수점 연산이 많이 요구된다. 논문은 이 점을 개선하고자 FP64와 FP32 연산을 혼합하는 ‘혼합 정밀도’ 전략을 도입한다. 제안된 세 가지 방법은 (1) 저‑랭크 근사 블록에만 FP32를 적용하고, 상위 레벨 블록은 FP64를 유지하는 ‘레벨 기반 혼합’, (2) 행렬‑벡터 곱 과정에서 중간 결과를 FP32로 축소한 뒤 최종 누적 단계에서 FP64로 복원하는 ‘중간 축소 혼합’, (3) BiCG‑STAB 반복 과정의 사전‑후처리 단계에만 FP32를 사용하고 핵심 연산은 FP64로 수행하는 ‘반복자 혼합’이다. 각각의 방법은 정확도 손실을 최소화하면서도 메모리 대역폭과 연산량을 크게 감소시킨다. 실험에서는 표준 BEM 문제(전도체 표면 전위 해석)를 대상으로 3차원 복합 형상과 다양한 자유도(N≈10⁴~10⁵)를 사용하였다. 결과는 레벨 기반 혼합이 전체 실행 시간을 평균 35 % 단축하면서 상대 오차를 10⁻⁶ 이하로 유지함을 보여준다. 중간 축소 혼합은 메모리 사용량을 40 % 절감하지만, 특정 조건에서 수렴 속도가 약간 감소한다. 반복자 혼합은 가장 보수적인 접근으로, 정확도는 FP64와 동일하지만 연산량이 20 % 정도 감소한다. 전반적으로 혼합 정밀도 적용이 H‑행렬·BEM 연산의 실용성을 크게 높이며, 특히 GPU와 같은 저‑정밀도 연산에 최적화된 하드웨어에서 큰 이점을 제공한다는 점이 핵심 인사이트이다.
댓글 및 학술 토론
Loading comments...
의견 남기기