마지막 반복에서도 선형 수렴 미니맥스 최적화 새로운 지평
이 논문은 기존 평균‑반복 수렴에 한계가 있던 미니맥스 문제에서, Hamiltonian Gradient Descent(HGD)와 Consensus Optimization(CO) 알고리즘이 “충분히 선형(bilinear)” 조건을 만족할 때 마지막 반복에 대해 선형 수렴을 보장한다는 것을 증명한다. 특히, 강한 볼록‑볼록이 아닌 일반적인 convex‑concave 설정에서도 전역적인 비점근적 수렴률을 제공한다.
저자: Jacob Abernethy, Kevin A. Lai, Andre Wibisono
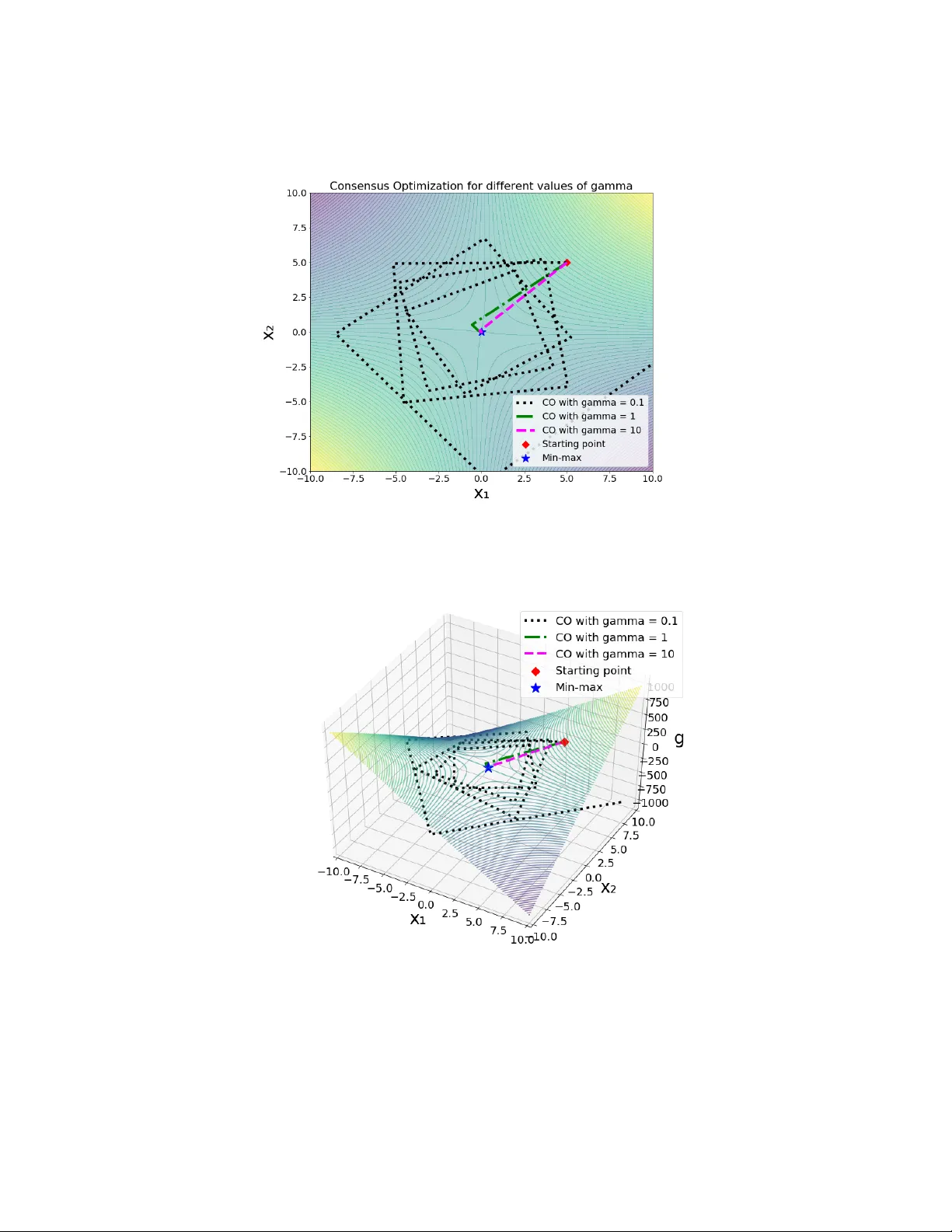
본 논문은 최근 머신러닝에서 GAN과 같은 비볼록(min‑max) 게임이 널리 사용되면서, 전통적인 평균‑반복 수렴 방식이 한계에 봉착한 상황을 배경으로 한다. 기존의 No‑Regret 기반 알고리즘, 특히 Simultaneous Gradient Descent/Ascent(SGDA)는 단순한 bilinear 게임에서도 순환하거나 발산하는 문제가 알려져 있어, 마지막 반복에 대한 수렴 보장이 절실히 요구된다.
저자들은 이러한 문제를 해결하기 위해 Hamiltonian Gradient Descent(HGD)라는 알고리즘을 제안한다. HGD는 목적 함수 g(x₁,x₂)의 signed gradient vector ξ = (∂g/∂x₁, −∂g/∂x₂) 를 이용해 Hamiltonian H(x)=½‖ξ(x)‖² 을 정의하고, H에 대해 표준 경사 하강을 수행한다. HGD의 업데이트는
x^{(k+1)} = x^{(k)} − η ∇H(x^{(k)}) = x^{(k)} − η J(x^{(k)})ᵀ ξ(x^{(k)})
이며, 여기서 J 는 ξ 의 Jacobian이다. 이 업데이트는 Hessian‑vector product를 필요로 하지만, 자동 미분 프레임워크에서는 두 번의 역전파만으로 효율적으로 구현 가능하다.
논문은 먼저 기본적인 가정들을 정리한다. g는 충분히 매끄럽고, 모든 임계점이 전역적인 saddle point(즉, min‑max 해)임을 가정한다(Assumption 2.6). 또한, g는 (L₁,L₂,L₃)‑Lipschitz 조건을 만족하고, 이를 통해 H의 Lipschitz 상수 L_H = L₁L₃ + L₂² 를 정의한다.
주요 이론적 결과는 세 가지 경우로 나뉜다.
1. **강하게 볼록‑강하게 오목 경우**(Theorem 3.2)
g가 x₁에 대해 c‑strongly convex, x₂에 대해 c‑strongly concave이면, η=1/L_H 로 설정한 HGD는
‖ξ(x^{(k)})‖ ≤ (1−c²/L_H)^{k/2} ‖ξ(x^{(0)})‖
를 만족한다. 이는 기존 결과와 일치하지만, HGD가 동일한 수렴률을 보임을 확인한다.
2. **한 변수 선형, 교차 미분 전역 전순위(full rank) 경우**(Theorem 3.3)
g가 x₂에 대해 선형이고, 교차 Hessian ∇²₁₂g 의 최소 특잇값이 γ>0이면,
‖ξ(x^{(k)})‖ ≤ (1−γ⁴/((2γ²+L²)L_H))^{k/2} ‖ξ(x^{(0)})‖
로 선형 수렴한다. 여기서 L은 x₁에 대한 L‑smooth 상수이다.
3. **충분히 bilinear 조건을 만족하는 일반 convex‑concave 경우**(Theorem 3.4)
g가 양쪽 변수에 대해 L‑smooth하고, 각 변수의 Hessian(∇²₁₁g, ∇²₂₂g)의 최소 고윳값을 각각 ρ², μ²라 정의한다. 교차 Hessian ∇²₁₂g 는 특잇값이 γ≤σ≤Γ 범위에 존재한다. 이때 다음 부등식이 성립하면
(γ²+ρ²)(μ²+γ²) − 4L²Γ² > 0,
HGD는 η=1/L_H 로 설정했을 때
‖ξ(x^{(k)})‖ ≤ (1−c)^{k/2} ‖ξ(x^{(0)})‖
형태의 선형 수렴을 보인다. 이 부등식은 기존의 PL 조건이나 순수 bilinear 가정과는 다른 새로운 충분조건이며, 교차 곡률이 충분히 강하고 동시에 각 플레이어의 자체 곡률이 너무 약하지 않을 때 만족한다.
위 세 결과는 모두 “마지막 반복”에 대한 전역적인 비점근적 수렴률을 제공한다는 점에서 기존 평균‑반복 기반 이론과 차별화된다.
또한, 논문은 Consensus Optimization(CO) 알고리즘을 HGD의 변형으로 해석한다. CO는 H에 정규화 항 λ‖ξ‖² 를 추가한 형태이며, λ가 충분히 작을 경우 HGD와 동일한 수렴 구간을 갖는다. 이는 CO가 실제 GAN 훈련에서 좋은 성능을 보이는 이유를 이론적으로 설명한다.
확률적 설정에 대해서는 Stochastic HGD를 제안한다. H가 PL 조건을 만족한다는 사실을 이용해, 잡음이 있는 경우에도 마지막 반복에 대해 O(1/√k) 속도의 수렴을 보인다. 이는 미니배치 기반 학습에서도 적용 가능함을 의미한다.
실험 부분에서는 HGD와 CO가 bilinear, convex‑concave, 그리고 비선형 GAN 손실에 대해 SGDA와 비교했을 때 빠르게 수렴하고, 특히 마지막 반복에서의 오차가 크게 감소함을 시각적으로 보여준다.
결론적으로, 이 논문은 “gradient‑norm 최소화”라는 새로운 관점을 통해, 기존 알고리즘이 실패하던 convex‑concave 영역 전반에 걸쳐 전역적인 마지막 반복 선형 수렴을 보장한다는 중요한 이론적 기여를 한다. 또한, CO와의 연결 고리를 통해 실용적인 GAN 훈련에도 바로 적용할 수 있는 실용적 가치를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기