자동 벵골어 질문응답 시스템을 위한 의미유사도 기반 새로운 접근법
초록
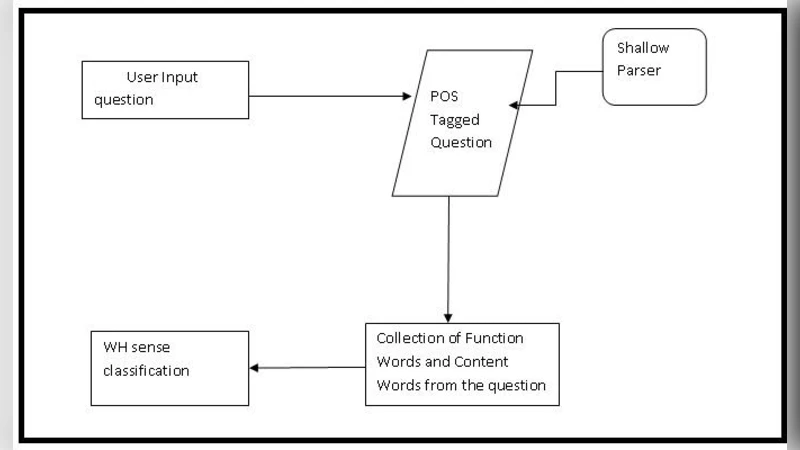
본 논문은 벵골어 질문에 대해 의미적으로 가장 적합한 답을 찾기 위해 통계적 파라미터와 엔트로피·유사도 계산을 결합한 두 단계 알고리즘을 제안한다. 275 000문장 데이터베이스를 이용해 실험했으며, 실제 정답이 1위에 오르는 비율이 82.3%, 상위 5위 안에 포함되는 비율이 90.0%에 달한다. 정확도 97.32%, 정밀도 98.14%를 기록했으며, 구현에 사용된 POS 태거는 IIIT Hyderabad의 LTRC shallow parser이다.
상세 분석
이 연구는 벵골어와 같이 형태소 분석이 복잡하고 어휘 자원이 제한적인 언어에 대한 질문응답(QA) 시스템 구축의 실용적 해결책을 제시한다. 첫 번째 단계에서는 질문과 후보 답변 사이의 통계적 매칭을 수행한다. 여기에는 단어 빈도, 인덱스, 품사(POS) 정보가 포함되며, 이는 전통적인 키워드 기반 검색이 놓치는 의미적 연결 고리를 보완한다. 두 번째 단계에서는 엔트로피와 유사도 점수를 각각 별도의 모듈에서 계산한다. 엔트로피는 문장 내 정보량을 정량화해 답변 후보의 ‘예측 불확실성’을 평가하고, 유사도 모듈은 의미적 거리(예: 코사인 유사도 혹은 시멘틱 벡터 기반 거리)를 측정한다. 두 점수를 결합해 최종 ‘sense score’를 산출함으로써 답변을 순위화한다.
데이터셋은 정부 지원 TDIL 프로젝트에서 제공된 275 000문장으로, 규모는 충분히 크지만 도메인 다양성에 대한 언급이 부족하다. 이는 특정 분야에 편향된 성능을 초래할 가능성을 내포한다. 또한 POS 태깅에 사용된 shallow parser는 정확도가 높은 편이지만, 벵골어의 복합어와 어미 변형을 완전히 포착하지 못할 수 있다. 따라서 오류 전파(error propagation) 문제가 존재할 가능성이 있다.
평가 지표로는 정확도와 정밀도 외에 혼동 행렬 기반의 세부 수치를 제시했지만, 재현율(recall)이나 F1-score와 같은 균형 잡힌 지표는 누락되었다. 실제 정답이 1위에 오르는 비율(82.3%)은 인상적이지만, 상위 5위 내 포함률(90.0%)과 전체 정확도(97.32%) 사이의 차이를 보면, 다중 정답 상황에서의 성능 평가가 필요함을 시사한다.
알고리즘 복잡도 측면에서 두 단계의 연산이 순차적으로 진행되므로 실시간 응답에는 제한이 있을 수 있다. 특히 엔트로피와 유사도 계산이 대규모 후보 집합에 대해 수행될 경우, 효율적인 인덱싱이나 차원 축소 기법이 요구된다.
마지막으로, 논문은 현재 시스템이 겪는 ‘도전 과제와 함정’을 기술했지만, 구체적인 오류 사례나 개선 방향에 대한 심층 분석이 부족하다. 향후 연구에서는 딥러닝 기반 임베딩(예: BERT multilingual)과의 비교, 도메인 적응(adaptation) 기법, 그리고 사용자 피드백을 활용한 순위 재학습 등을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기