TPU GPU CPU 딥러닝 성능 비교와 설계 교훈
본 논문은 파라미터화된 벤치마크 Suite인 ParaDnn을 이용해 FC, CNN, RNN 모델을 포괄적으로 생성하고, Google Cloud TPU v2/v3, NVIDIA V100 GPU, Intel Skylake CPU 세 플랫폼을 대상으로 학습 성능을 정량화한다. TPU는 메모리 대역폭과 인터칩 통신에서 병목이 발생하지만 대규모 배치와 큰 CNN·RNN에 강점이 있다. GPU는 메모리 대역폭이 풍부해 중소형 FC 모델에 유리하고, CPU…
저자: Yu Emma Wang, Gu-Yeon Wei, David Brooks
이 논문은 딥러닝 학습에 필요한 연산량이 급증함에 따라 하드웨어 특화가 필수적인 현상을 배경으로, 다양한 모델 유형을 포괄하는 파라미터화된 벤치마크 Suite인 ParaDnn을 제안한다. ParaDnn은 Fully‑Connected(FC), Convolutional(CNN), Recurrent(RNN) 네트워크를 각각 수천 가지 변형으로 생성해 모델 깊이, 폭, 배치 크기, 임베딩 길이, 입력·출력 차원 등을 자유롭게 조절한다. 이를 통해 기존 MLPerf·Fathom 등 실세계 모델 중심 벤치마크가 놓치는 ‘연속적인 설계 공간’ 탐색이 가능해진다. 논문은 또한 실제 산업 현장에서 널리 사용되는 여섯 개의 대표 모델(Transformer, ResNet‑50, RetinaNet, DenseNet, MobileNet, SqueezeNet)을 포함해 전체 14개의 워크로드를 평가 대상으로 삼았다.
하드웨어 플랫폼은 Google Cloud TPU v2/v3, NVIDIA V100 GPU(DGX‑1), Intel Skylake 기반 CPU(n1‑standard‑32) 세 가지를 선정했다. TPU v2는 4개의 패키지(8코어)로 구성돼 180 TFLOPS 피크, 8 GB/코어 HBM, 2400 GB/s 메모리 대역폭을 제공한다. v3는 MXU 수와 HBM 용량을 1.5 ~ 2배 확대해 420 TFLOPS 피크와 3600 GB/s 대역폭을 달성한다. V100 GPU는 125 TFLOPS 피크와 16 GB HBM2, 900 GB/s 대역폭을 갖추었으며, CPU는 2 TFLOPS 피크와 120 GB DDR4 메모리를 보유한다.
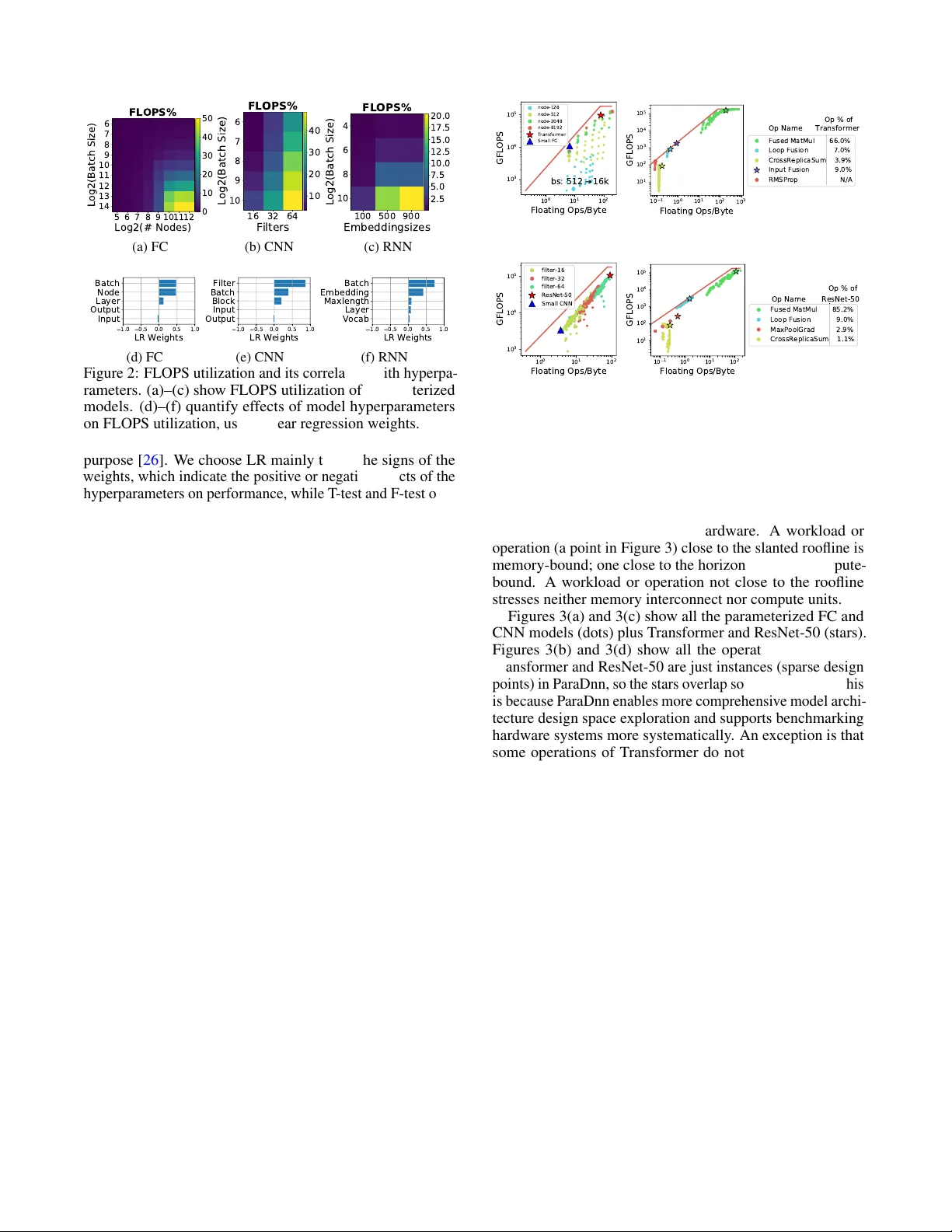
실험 결과는 다음과 같다. 첫째, TPU는 배치와 모델 폭에 의해 노출되는 병렬성을 잘 활용하지만, 레이어 수에 따른 깊이 병렬성은 활용도가 낮아 모델 파이프라인화가 필요하다(Observation 1). 둘째, 대부분의 FC·CNN 연산이 메모리 대역폭에 의해 제한돼, 특히 4K 노드 이상의 대규모 FC와 중간 규모 CNN에서 메모리 병목이 두드러졌다(Observation 2). 셋째, TPU 코어 간 인터칩 통신 오버헤드가 10 ~ 20 % 수준으로, 다중 패키지 사용 시 확장성이 제한된다(Observation 3). 넷째, 배치 크기가 클수록 TPU의 systolic array가 효율적으로 작동해 2 ~ 3배 이상의 FLOPS 활용도를 보였으며, 대규모 배치가 가능한 모델에서는 GPU보다 월등히 높은 처리량을 기록했다(Observation 8, 9). 반면, 작은 배치·중소형 FC 모델에서는 GPU의 warp 스케줄링이 유연해 더 높은 성능을 유지한다(Observation 10). 다섯째, 메모리 용량 제한으로 가장 큰 FC 모델은 CPU에서만 학습 가능했으며, 이는 메모리 용량이 연산 성능과 동등하게 중요한 설계 요소임을 시사한다(Observation 6).
소프트웨어 스택 최적화 측면에서는, TensorFlow/XLA와 CUDA/cuDNN의 지속적인 업데이트가 각각 2.5 ~ 9.7배의 성능 향상을 가져왔으며, 16‑bit 양자화는 메모리 트래픽을 절반 이하로 감소시켜 전체 처리량을 크게 끌어올렸다(Observation 13, 14). 이러한 개선은 하드웨어가 출시된 이후에도 소프트웨어 최적화가 성능을 크게 좌우한다는 중요한 교훈을 제공한다.
마지막으로, 논문은 연구 범위의 제한점도 명시한다. 멀티‑GPU·멀티‑TPU 확장성, 추론(Inference) 워크로드, 그리고 실제 시스템 레벨 최적화(예: 모델 병렬화, 파이프라인 스케줄링) 등은 향후 연구 과제로 남겨두었다. 전체적으로, 이 연구는 딥러닝 가속기 설계 시 연산·메모리·통신 균형을 맞추고, 소프트웨어 스택과 양자화 기법을 적극 활용해야 함을 실증적으로 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기