딕셔너리 학습 기반 광장 최적화로 고스트 이미징 품질 향상
본 논문은 고스트 이미징(GI)에서 사용되는 샘플링 행렬을 딕셔너리 학습으로 얻은 과잉완전 사전(Over‑complete dictionary)을 기반으로 최적화한다. 상호코히런스 최소화를 목표로 한 Frobenius‑norm 문제를 풀어 폐쇄형 해를 도출하고, 비음수 제약을 만족하도록 상수 보정(NN‑lifting)을 적용한다. 제안 방법은 기존 최적화 기법보다 낮은 샘플링 비율에서도 PSNR·SSIM이 크게 개선되며, 행을 추가하는 방식으로 …
저자: Chenyu Hu, Zhisheng Tong, Zhentao Liu
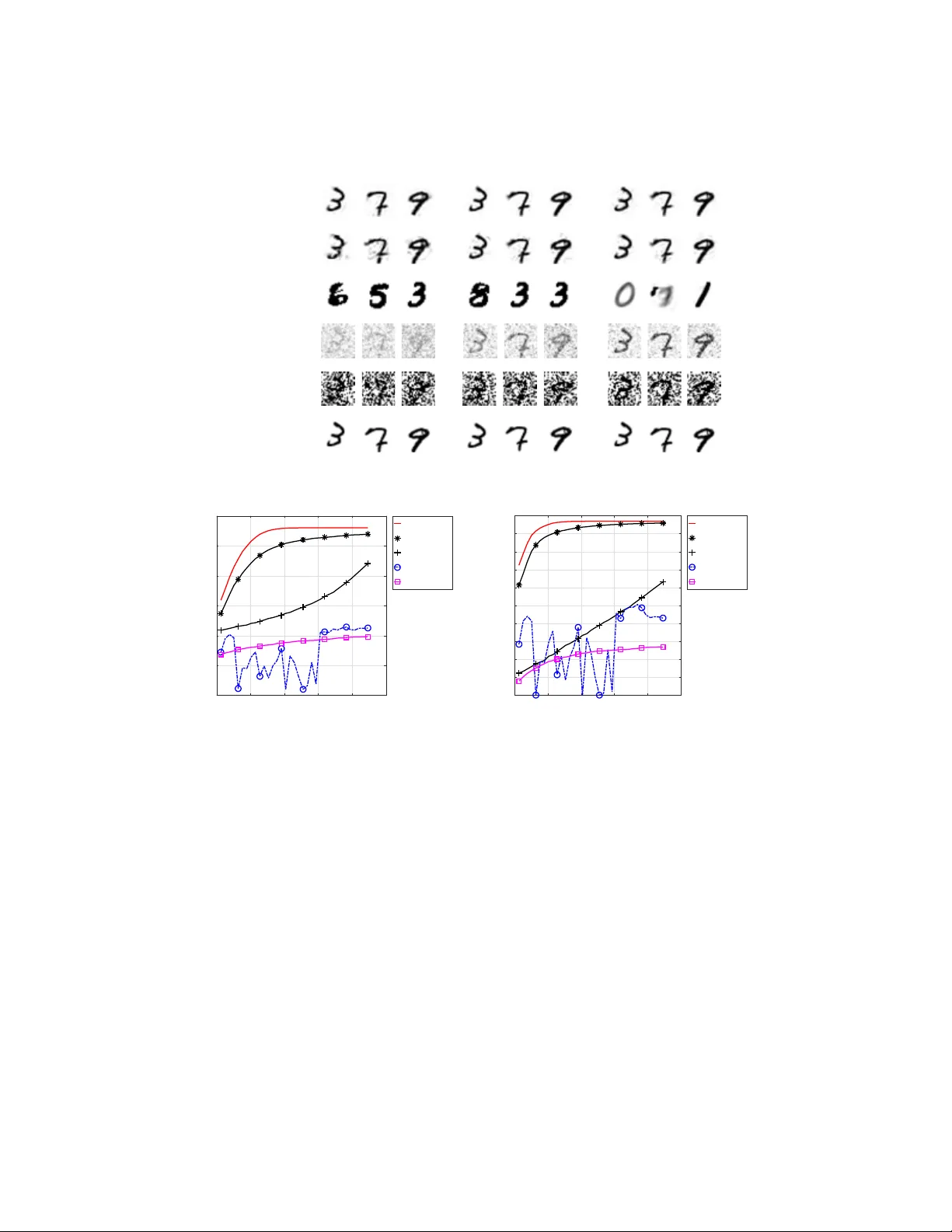
고스트 이미징(Ghost Imaging, GI)은 물체 빔과 레퍼런스 빔 사이의 두 번째 차량 상관을 이용해 이미지를 복원하는 혁신적인 광학 기술이다. 이론적으로는 무한히 많은 샘플링이 필요하지만, 실제 실험에서는 샘플 수가 제한적이어서 재구성된 이미지의 신호‑대‑노이즈 비(SNR)가 낮아지는 문제가 있다. 기존에는 복원 알고리즘을 개선하거나, 직교 변환(예: DCT) 기반의 샘플링 행렬을 최적화하는 방법이 제안되었지만, 직교 변환은 다양한 이미지에 대한 희소성을 충분히 포착하지 못한다는 한계가 있다.
본 논문은 이러한 한계를 딕셔너리 학습을 통해 극복하고자 한다. 먼저, 대규모 이미지 집합(MNIST 손글씨 20,000장)을 이용해 K‑SVD 알고리즘으로 과잉완전 사전 Ψ∈ℝ^{N×K}를 학습한다. Ψ의 첫 번째 열은 모든 원소가 동일하도록 고정(N−1/2)하고, 나머지 열은 평균이 0이 되도록 제약한다. 이는 GI에서 빛 강도가 비음수이며, 첫 열이 전체 평균을 담당하도록 설계된 것이다.
GI의 측정 모델은 y = Φx + n (Φ∈ℝ^{M×N}, x∈ℝ^{N})이며, x = Ψz 로 표현하면 y = D z + n (D = ΦΨ) 가 된다. 압축 센싱 이론에 따르면, D가 희소 벡터 z의 정보를 충분히 보존하려면 열 간 상호코히런스 μ(D) = max_{i≠j} |⟨d_i,d_j⟩|/ (‖d_i‖‖d_j‖) 가 작아야 한다. 저자는 μ(D) 최소화를 Frobenius‑norm 형태로 변형하고, ΨΨᵀ = VΛVᵀ (V는 직교 행렬, Λ는 대각 행렬) 로 고유분해한다. 최적화 문제는 결국 ‖Λ^{1/2}W WᵀΛ^{1/2} − Λ‖_F^2 를 최소화하는 형태가 되며, 여기서 W = Λ Vᵀ Φᵀ이다. 해는 W = Λ^{1/2} 의 첫 M열을 선택하는 것이 최적임을 보이고, 이를 Φ에 역변환하면 폐쇄형 해 Φ* = V₁ᵀ (V₁은 V의 앞 M열) 를 얻는다.
이 해의 중요한 특징은 “연속 샘플링”이 가능하다는 점이다. 초기 M개의 샘플링을 위해 V₁만 사용하고, 추가 샘플링이 필요하면 V의 다음 행을 추가해 V_{M+Δ}를 구성하면 된다. 따라서 전체 최적화를 다시 수행할 필요가 없으며, 실시간 시스템에 적합하다.
GI에서 빛 강도는 비음수이어야 하므로, Φ*에 최소값 보정 상수 c를 더해 비음수 행렬 D̂ = Φ* + c·1_{M×N} 로 변환한다(NN‑lifting). 이 과정은 첫 열에만 영향을 주어 μ(D̂)에는 거의 변화를 주지 않는다.
실험에서는 28×28 MNIST 숫자를 대상으로 사전 Ψ를 학습하고, 제안된 Φ*에 NN‑lifting을 적용해 샘플링 행렬을 만든다. 비교 대상은 (1) 무작위 Gaussian 행렬, (2) Duarte
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기