GPU 가속 컬럼형 데이터 처리로 콜라이더 분석 속도 혁신
초록
본 논문은 HEP(고에너지 물리) 실험에서 발생하는 수십억 건의 이벤트 데이터를 컬럼형 메모리‑매핑 스파스 배열로 변환하고, Numba 기반의 CPU·GPU 커널을 이용해 연산을 병렬화함으로써 단일 서버에서 초당 백만 건 수준의 처리 속도를 달성한 사례를 제시한다. 핵심은 소수의 범용 커널만으로 복잡한 탑쿼크 쌍 분석을 구현하고, GPU 가속 시 20‑30배의 속도 향상을 얻은 점이다.
상세 분석
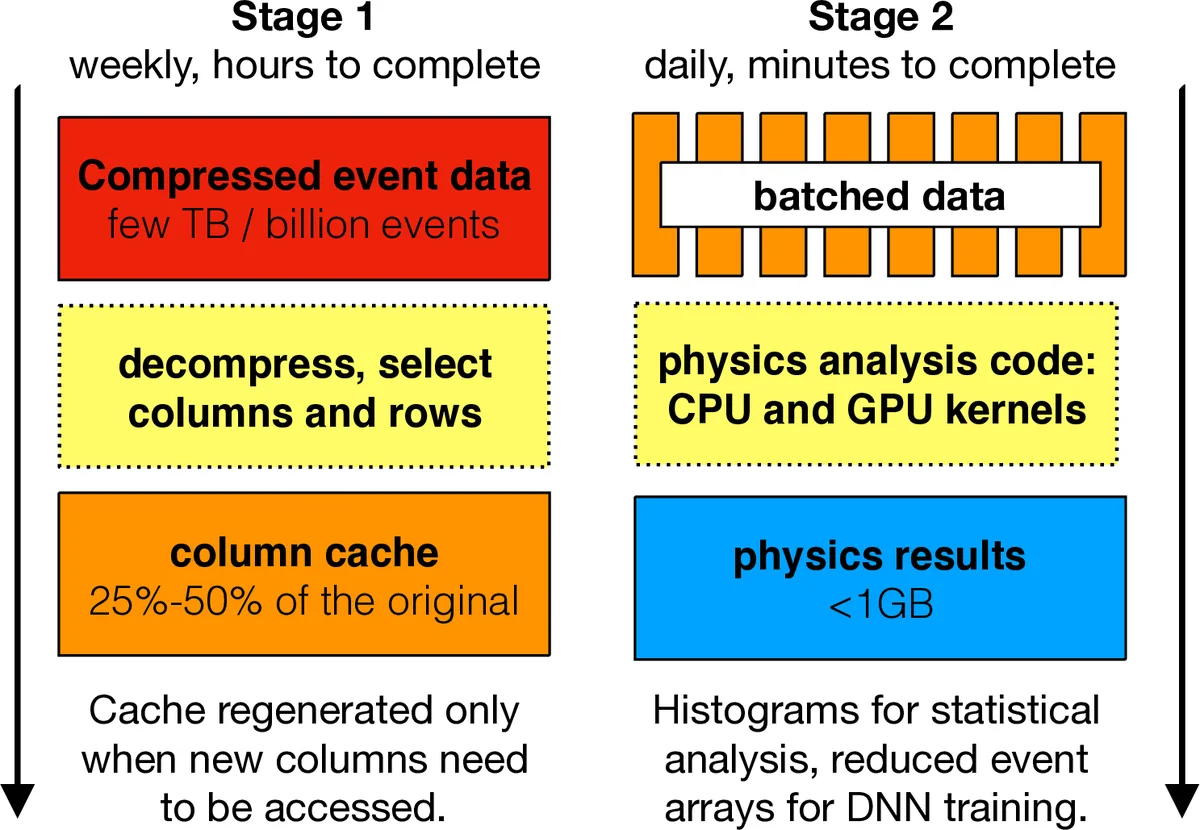
이 연구는 전통적인 HEP 데이터 처리 방식이 ROOT 파일을 기반으로 이벤트당 객체를 순차적으로 탐색하고, 다단계 배치 작업으로 전체 데이터를 축소한다는 점을 문제점으로 지적한다. 저자들은 이러한 흐름을 깨고, 이벤트‑레벨 데이터를 ‘열(column)’ 단위로 평탄화하고, 각 열을 1‑차원 연속 메모리 블록에 저장한 뒤, 이벤트 경계는 오프셋 배열(offset array)로 관리하는 스파스(또는 ‘jagged’) 구조를 채택한다. 이 접근법은 uproot·awkward‑array가 제시한 아이디어를 그대로 차용하면서도, 메모리‑맵 파일을 이용해 압축된 ROOT 파일을 부분적으로 해제하고 자주 사용하는 열만 캐시함으로써 I/O 오버헤드를 최소화한다.
핵심 연산은 ‘커널(kernel)’이라는 함수 형태로 정의된다. 저자들은 Numba의 prange와 CUDA JIT를 활용해 파이썬 수준에서 멀티스레드 CPU와 GPU 코드를 자동으로 생성한다. 예를 들어, 모든 입자의 transverse momentum(pT)을 합산해 HT를 계산하는 sum_ht 커널은 이벤트 오프셋을 기준으로 각 이벤트 구간을 독립적으로 처리한다. 마스크 배열을 이용해 선택된 입자와 이벤트만을 대상으로 연산을 제한함으로써 불필요한 메모리 복사를 방지하고, 연산 파이프라인 전체에 걸쳐 동일한 마스크를 재사용할 수 있다.
제시된 기본 커널 집합은 다음과 같다: get_in_offsets, set_in_offsets, sum_in_offsets, max_in_offsets, min_in_offsets, fill_histogram, get_bin_contents. 이들은 대부분 “오프셋 안에서의 축소(reduction)” 혹은 “오프셋 안에서의 인덱스 접근”이라는 패턴을 공유한다. 추가적으로, 물리학적 특수 연산인 ΔR 매칭이나 반대 전하 뮤온 선택과 같은 비정형 작업도 단일 패스 커널로 구현하였다. 이러한 설계는 커널 수를 최소화하면서도 복잡한 분석 흐름을 충분히 표현한다는 점에서 큰 장점을 가진다.
성능 평가에서는 약 1,100만 이벤트(총 입자 수 수십 억)를 사전 로드한 상태에서 다양한 커널을 실행하였다. CPU에서는 스레드 수를 늘릴수록 서브리니어하게 성능이 향상되었으며, 24코어 환경에서 단일 스레드 대비 최대 8배 정도의 가속을 기록했다. 반면 GPU(GeForce Titan X)에서는 동일 커널이 20‑30배의 속도 향상을 보였으며, 특히 ΔR 마스킹 커널은 CPU 단일 스레드 기준 7 MHz 처리율을 GPU에서는 약 14배 가속한 100 MHz 수준에 달했다. 전체 분석 파이프라인을 종합하면, 압축 해제·캐시 로드·커널 실행·히스토그램 집계까지 모든 단계가 단일 서버에서 초당 백만 이벤트 수준으로 처리되어, 기존 배치 작업에 비해 수십 배 빠른 결과를 얻었다.
이러한 결과는 몇 가지 중요한 시사점을 제공한다. 첫째, HEP 데이터가 본질적으로 ‘열 기반’이며, 스파스 구조를 활용하면 메모리 효율과 연산 효율을 동시에 개선할 수 있다. 둘째, 복잡한 물리 분석 로직도 몇 개의 범용 커널로 추상화할 수 있기에, 코드 유지보수와 확장성이 크게 향상된다. 셋째, Python‑Numba 조합은 프로토타이핑 단계에서 높은 생산성을 제공하면서도, JIT 컴파일을 통해 실험 수준의 성능을 확보한다는 점에서 실용적이다. 마지막으로, GPU 가속은 현재의 CPU‑중심 워크플로우를 보완하거나 대체할 수 있는 현실적인 옵션이며, 특히 히스토그램 기반 재가중치나 머신러닝 전처리와 같은 대규모 행렬 연산에 유리하다. 향후 연구에서는 압축 포맷 최적화, 다중 GPU 스케일링, 그리고 실시간 데이터 스트리밍과의 연계 등을 통해 전체 분석 사이클을 더욱 단축시킬 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기