지역 가우시안 분포 기반 효율적 클러스터링 알고리즘
초록
**
본 논문은 데이터 포인트를 K‑차원 R‑트리에 색인하고, 사용자 정의 거리 (d_s) 로 초기 중심을 격자식으로 배치한 뒤, 지역 가우시안 모델을 이용해 중심과 공분산을 반복적으로 업데이트한다. 중심 간 충돌을 검출해 중복을 제거하고, 최종적으로 각 포인트를 가장 높은 가우시안 확률을 가진 클러스터에 할당한다. 전체 복잡도는 최악 (O(T,N\log N)) 로, 기존 GMM·DBSCAN 대비 빠른 수행을 목표로 한다.
**
상세 분석
**
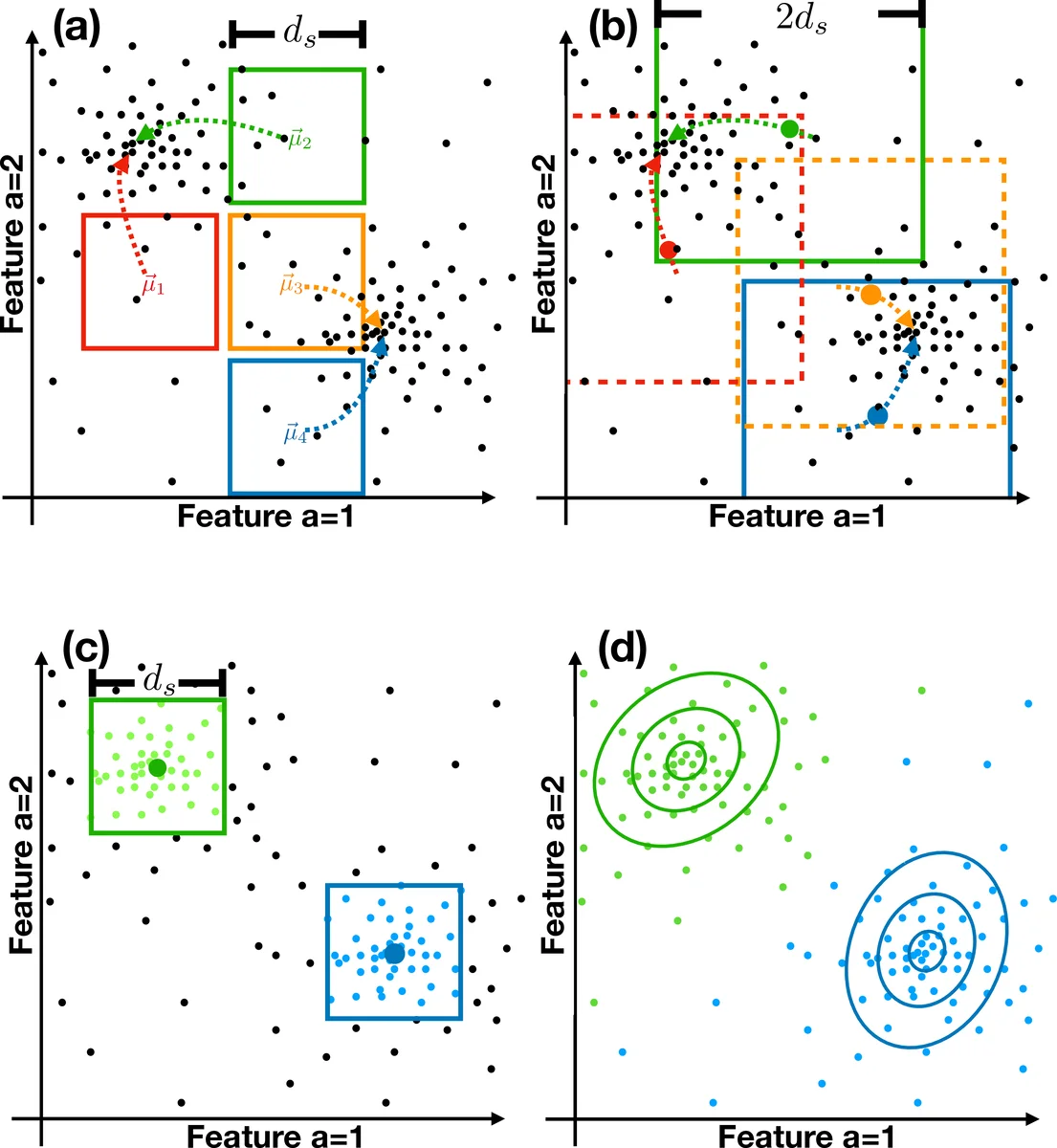
이 알고리즘은 크게 다섯 단계로 구성된다. 첫 번째는 모든 샘플을 K‑차원 R‑트리에 삽입해 평균 (O(N\log N)) 시간에 범위 탐색을 가능하게 한다. 두 번째 단계에서는 사용자 지정 파라미터 (d_s) 에 따라 격자 간격을 정하고, 각 격자 셀의 중심을 잠재적 클러스터 중심(시드)으로 설정한다. 여기서 각 시드에 대해 (d_s) 반경의 하이퍼큐브 안에 포함된 포인트 수 (N_c) 를 계산하고, 사전 정의된 최소 카운트 (L) 미만이면 폐기한다.
세 번째 단계는 시드들의 위치를 지역 평균으로 이동시키는 반복 과정이다. 수렴 기준 (|\mu^{t+1}_c-\mu^{t}_c|<\epsilon) 를 만족하면 멈추며, 두 시드가 (d_c=2d_s) 이내에 겹치면 카운트가 작은 시드를 삭제한다. 이는 중심 간 최소 거리 (d_s) 보장을 위한 핵심 메커니즘이며, 클러스터 수를 자동으로 결정한다는 장점을 제공한다.
네 번째 단계에서는 각 최종 중심에 대해 가중치 (w_{i,c}=P(x_i|\mu_c)/\sum_{j\in c}P(x_j|\mu_c)) 를 이용해 공분산 행렬 (\Sigma_c) 를 추정한다. 원식 (\Sigma_{mn}=\frac{1}{N_c}\sum (x_{mi}-\mu_{m})(x_{ni}-\mu_{n})) 에 가중치와 작은 정규화 파라미터 (\eta) 를 도입해 지역 데이터만으로도 안정적인 추정을 목표로 한다. 이때 평균장(mean‑field) 방식으로 (\Sigma) 를 반복 업데이트하며, 수렴 기준 (\max| \Sigma^{t+1}-\Sigma^{\text{input}}|<\epsilon) 을 사용한다.
마지막 단계는 각 데이터 포인트를 (P(x_i|\mu_c)) 값이 가장 큰 클러스터에 할당하는 간단한 라벨링이다. 이후 논문은 (L_p), (L%), (L_s) 와 같은 후처리 기준을 제시해 낮은 확률값이나 클러스터 간 구분이 약한 포인트를 제거하도록 설계하였다.
알고리즘의 시간 복잡도는 대부분 (O(N\log N)) 에 머물지만, 중심 수 (M) 와 반복 횟수 (T) 에 따라 (O(T,N\log N)) 으로 증가한다. 특히 단계 c와 d가 병목이 될 수 있다. 저자는 실험적으로 (T_{\max}<20) 이라 가정하고 복잡도를 제시한다.
비판적으로 보면, 논문은 실험 결과가 부족하고, 고차원(>10) 데이터에서 R‑트리의 성능 저하와 공분산 행렬 계산 비용을 충분히 논의하지 않는다. 또한 (d_s) 와 (L) 의 선택 가이드라인이 경험적이며, 자동 튜닝 메커니즘이 부재하다. 가중치 (w_{i,c}) 의 정의가 순환적이며, 실제 구현 시 수치적 불안정성을 야기할 가능성이 있다. 그럼에도 불구하고, 지역 기반 가우시안 모델을 이용해 클러스터 수를 자동 결정하고, 기존 GMM·DBSCAN 대비 선형에 가까운 복잡도를 달성한다는 점은 흥미롭다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기