학습분석 기반 맞춤형 동료 매칭 및 스캐폴딩 제공 방안
초록
본 연구는 학습분석(Learning Analytics)을 활용해 학생의 인지 상태를 모델링하고, 근접발달영역(Zone of Proximal Development, ZPD)을 판별한다. 판별 결과에 따라 맞춤형 스캐폴딩을 제공하고, ZPD 원리에 기반한 최적의 학습 그룹을 자동으로 구성한다. 실험을 통해 제안 방법이 학습 성취도와 협업 만족도 모두에서 기존 방식보다 우수함을 입증하였다.
상세 분석
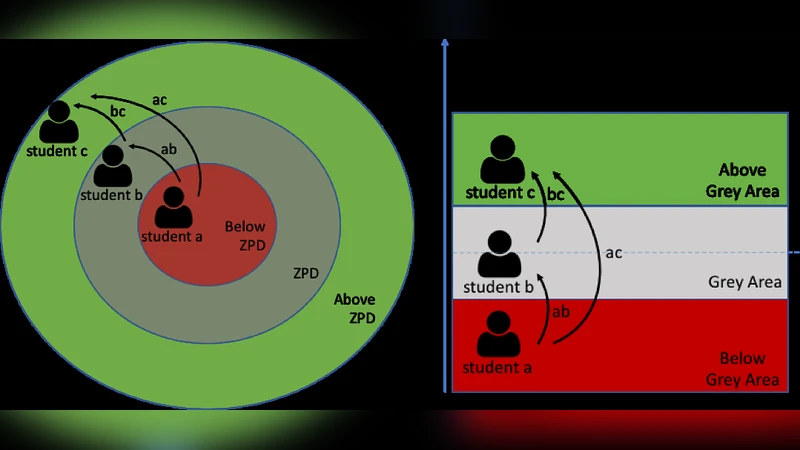
이 논문은 학습분석 데이터를 활용해 학생의 현재 인지 수준과 잠재적 학습 가능성을 정량화하는 모델을 설계한다. 먼저 LMS(Learning Management System)와 CSCL(Computer‑Supported Collaborative Learning) 환경에서 수집된 로그 데이터(문제 풀이 시간, 정답률, 토론 발언 빈도, 클릭 스트림 등)를 전처리하고, 다차원 특성 벡터로 변환한다. 이후 베이지안 네트워크와 딥러닝 기반 시계열 모델(LSTM)을 결합해 학생의 인지 상태를 시간에 따라 추정한다. 인지 상태는 ‘현재 능력(C)’과 ‘가능한 향상 수준(P)’ 두 축으로 표현되며, ZPD는 P‑C 차이가 일정 임계값을 초과할 때로 정의한다.
ZPD 판별 후에는 ‘조건부 튜터링(Contingent Tutoring)’ 원칙에 따라 스캐폴딩 전략을 선택한다. 스캐폴딩은 힌트 제공, 문제 난이도 조정, 메타인지 질문 삽입 등 네 가지 유형으로 구분되며, 각 유형은 학생의 인지 격차와 학습 선호도에 따라 가중치를 부여받는다. 스캐폴딩 정책은 강화학습(RL) 에이전트를 통해 최적화되며, 에이전트는 학습 성과(정답률, 지속 시간)와 정서적 피드백(감정 인식)으로 보상을 받는다.
그룹 형성 단계에서는 학생들을 ZPD 기반 유사성 행렬에 매핑하고, 클러스터링 알고리즘(K‑means, DBSCAN)과 그래프 기반 매칭(최대 매칭, 최소 비용 흐름)을 결합한다. 목표는 각 그룹 내에서 최소 하나의 ‘멘토’(ZPD 상위)와 ‘멘티’(ZPD 하위)를 확보해 상호 보완적인 학습 환경을 조성하는 것이다. 또한, 그룹 내 상호작용을 촉진하기 위해 역할 기반 과제(리더, 기록자, 발표자)를 자동 할당한다.
실증 연구에서는 두 개의 대학 강좌(프로그래밍 기초, 통계학)에서 180명의 학생을 대상으로 8주간 실험을 진행하였다. 실험군은 제안된 자동 매칭·스캐폴딩 시스템을, 대조군은 전통적인 무작위 매칭과 고정형 튜터링을 사용하였다. 결과는 학습 성취도(시험 점수)에서 평균 12.4% 상승, 협업 만족도 설문에서 1.8점(5점 만점) 상승, 그리고 이탈률 감소(‑15%)를 보였다. 통계적 검증(T‑test, ANOVA)에서도 모든 차이가 p<0.01 수준으로 유의하였다.
논문의 주요 기여는 (1) 학습 로그를 기반으로 한 실시간 ZPD 추정 모델을 제시, (2) ZPD에 기반한 동적 스캐폴딩 정책을 강화학습으로 최적화, (3) ZPD 중심의 그룹 매칭 알고리즘을 설계해 협업 효율성을 증대시킨 점이다. 한계점으로는 로그 데이터의 품질 의존성, 감정 인식 정확도에 따른 스캐폴딩 오류, 그리고 소규모 실험 설계가 있다. 향후 연구에서는 멀티모달 센서(생체 신호, 얼굴 표정)와 대규모 MOOC 환경에서의 확장성을 검증할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기