적응형 템플릿 시스템을 이용한 지속성 다이어그램 기반 특징 선택
본 논문은 지속성 다이어그램에서 데이터를 기반으로 템플릿 함수를 자동으로 생성하는 적응형 템플릿 시스템을 제안한다. CDER, GMM, HDBSCAN 세 가지 클러스터링·밀도 추정 기법을 이용해 특징 영역을 탐색하고, 이를 통해 얻은 템플릿을 이용해 분류·회귀 작업에서 경쟁력 있는 성능을 달성한다. 실험 결과 CDER가 가장 안정적이며, 특히 단백질 분류에서 82%에서 98%까지 정확도를 크게 향상시킨다.
저자: Luis Polanco, Jose A. Perea
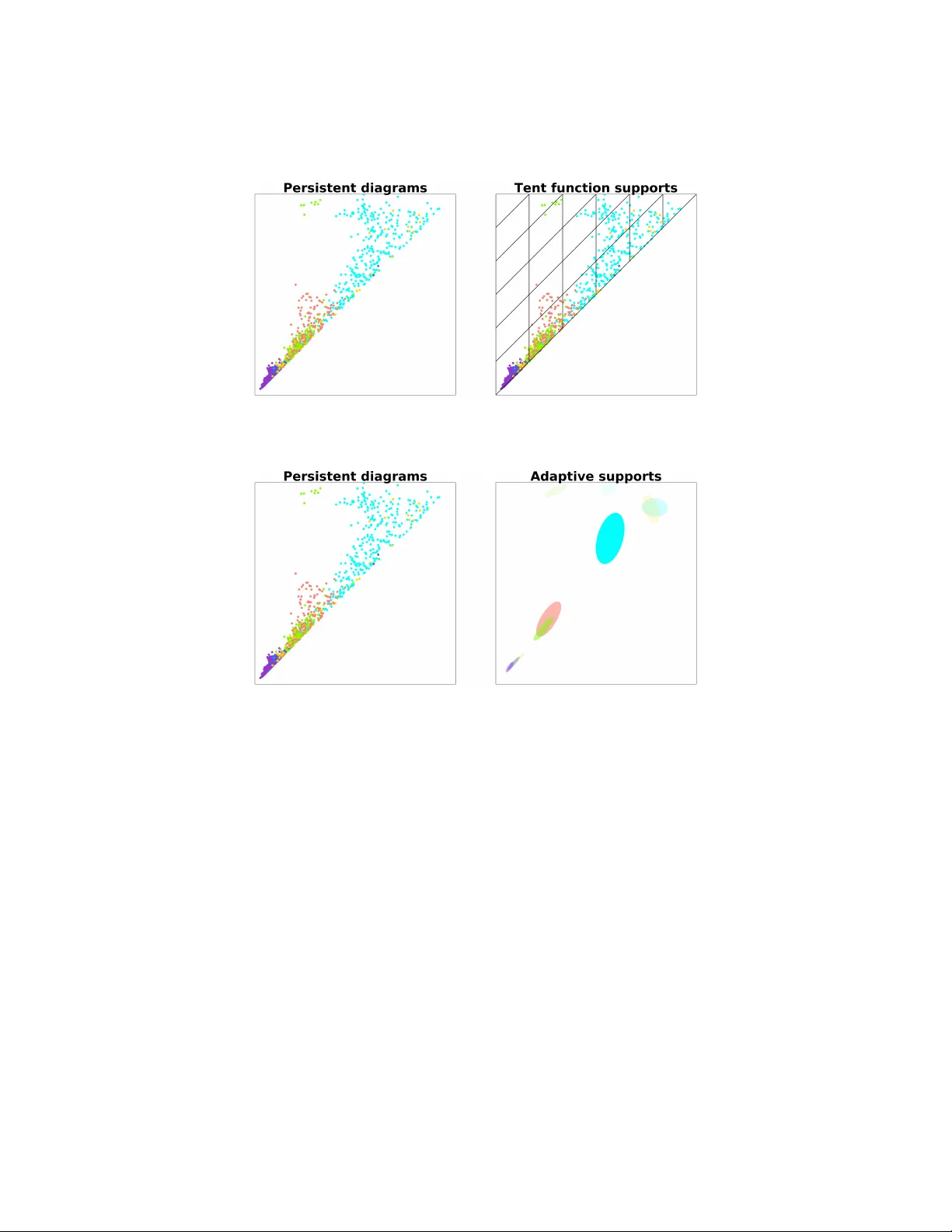
본 논문은 지속성 다이어그램을 머신러닝 모델에 효과적으로 활용하기 위한 적응형 템플릿 시스템을 제안한다. 위상 데이터 분석(TDA)에서 지속성 다이어그램은 데이터의 다중 스케일 토폴로지 정보를 압축한 형태이지만, 이를 직접적인 피처로 사용하기 위해서는 적절한 함수 변환이 필요하다. 기존 연구에서는 고정된 템플릿(예: 텐트 함수, 보간 다항식)을 사용해 다이어그램을 실수값 함수 공간 C(D,ℝ)에 매핑했으며, Theorem 2.8에 의해 이러한 템플릿 집합이 조밀하면 임의의 연속 함수를 근사할 수 있음을 보였다. 그러나 고정 템플릿은 학습 과제와 무관하게 사전에 정의된 격자나 메쉬를 사용하므로, 많은 템플릿이 실제로는 정보량이 적은 영역을 차지하게 된다. 이는 차원 폭발과 과적합 위험을 초래한다.
이를 해결하고자 저자들은 데이터‑드리븐 방식으로 템플릿의 지원 영역을 자동으로 선택하는 적응형 템플릿 시스템을 설계하였다. 핵심 아이디어는 라벨이 부여된 지속성 다이어그램 집합을 포인트 클라우드로 간주하고, 클러스터링·밀도 추정 기법을 적용해 클래스별로 특징적인 고밀도 영역을 찾아내는 것이다. 찾은 영역을 타원 형태로 근사하고, 해당 타원 내부에서 정의되는 부드러운 함수 f_A(z)=1−(z−x)ᵀA(z−x) (내부에서는 0≤…<1, 외부에서는 0) 를 템플릿 함수로 채택한다. 이렇게 정의된 템플릿은 지속성 다이어그램 D에 대해 ν_f(D)=∑_{(x,m)∈D} f_A(x) 로 계산되며, 이는 각 다이어그램을 고정 차원의 피처 벡터로 변환한다.
세 가지 적응형 템플릿 생성 방법을 제안한다.
1. **Cover‑Tree Entropy Reduction (CDER)**: 라벨이 부여된 포인트 클라우드에 대해 커버 트리를 구축하고, 각 노드(볼/타원)의 라벨 분포 엔트로피를 계산한다. 엔트로피가 최소인 영역은 특정 클래스에 특화된 정보를 많이 포함하므로, 이를 템플릿 지원으로 선택한다. CDER는 트리 구조 덕분에 O(N log N)의 시간 복잡도로 대규모 데이터에도 적용 가능하며, 엔트로피 기반 선택이 클래스 구분에 직관적으로 연결된다.
2. **Gaussian Mixture Models (GMM)**: EM 알고리즘을 이용해 다이어그램 점들의 확률 밀도를 K개의 가우시안 컴포넌트로 근사한다. 각 컴포넌트의 평균과 공분산을 타원 형태로 변환해 템플릿 지원으로 사용한다. GMM은 데이터가 다중 정규분포를 따를 때 효과적이며, 컴포넌트 수 K를 조절해 템플릿 수를 제어할 수 있다. 다만 초기 파라미터와 K 선택에 민감하고, 복잡한 비정규 형태에는 부적합할 수 있다.
3. **Hierarchical Density‑Based Spatial Clustering of Applications with Noise (HDBSCAN)**: 밀도 기반 클러스터링을 계층적으로 수행해 노이즈를 자동 제거하고, 각 클러스터의 핵심 영역을 타원으로 근사한다. HDBSCAN은 비선형 형태와 잡음에 강하지만, 클러스터 경계가 불규칙할 경우 타원 근사가 과도한 근사 오차를 발생시킬 수 있다.
템플릿 시스템을 구축한 뒤, 각 다이어그램에 대해 ν_f₁,…,ν_f_N을 계산하고, 이를 입력으로 다항식 회귀·분류 모델(예: 커널 리지 회귀, SVM 등)을 학습한다. Theorem 2.8에 의해 이러한 피처 조합은 연속 함수 공간에서 조밀하므로, 목표 함수(예: 클래스 확률)를 임의의 정밀도로 근사할 수 있다.
**실험**은 세 가지 도메인에서 수행되었다.
- **매니폴드 분류**: 6가지 서로 다른 매니폴드(annulus, cube, 3‑cluster, 3‑cluster‑of‑3‑cluster, sphere, torus)에서 200점씩 샘플링한 포인트 클라우드에 대해 지속성 다이어그램을 생성하고, 33%를 테스트, 67%를 훈련에 사용해 커널 리지 회귀 모델을 학습했다. CDER 기반 템플릿은 평균 정확도에서 기존 텐트 템플릿보다 2‑3% 향상하고, 표준편차를 절반 이하로 감소시켰다. 또한, 샘플 수를 늘릴수록 정확도가 점진적으로 상승했으며, CDER는 가장 일관된 성능을 보였다.
- **SHREC 2014 인간 형태**: 15개의 클래스(성별·연령·포즈)로 구성된 3D 메쉬 데이터에 대해 히트 커널 서명 하위 레벨 집합을 이용해 지속성 다이어그램을 만들었다. 10가지 커널 파라미터에 대해 각각 분류 실험을 수행했으며, CDER 템플릿은 GMM·HDBSCAN 대비 평균 4‑5% 높은 정확도(≈ 92%)와 낮은 변동성을 기록했다. 특히 6번째 커널 파라미터에서는 CDER가 기존 최고 성능과 동등하거나 약간 앞섰다.
- **단백질 분류 (PCB00019)**: 1 357개의 단백질을 55개의 라벨로 분류하는 과제에서, 기존 연구(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기