신경망 손실 지형의 지역 기하학이 드러내는 네 가지 놀라운 현상
이 논문은 분류 문제에서 관찰되는 네 가지 지역 기하학적 특성(클래스 수와 일치하는 고양성 곡률 방향, 그라디언트가 해당 저차원 서브스페이스에 집중, 학습 과정 중 곡률의 비단조적 변화, 그리고 고차원 파라미터 공간의 무작위 저차원 초평면에서도 성공적인 학습 가능)을 단일 확률 모델로 설명한다. 핵심 가정은 로그잇 곡률이 약하고, 로그잇 그라디언트가 클래스별로 강하게 클러스터링되며, 클래스 확률이 학습 전후로 거의 고정된다는 점이다. 이를 통해…
저자: Stanislav Fort, Surya Ganguli
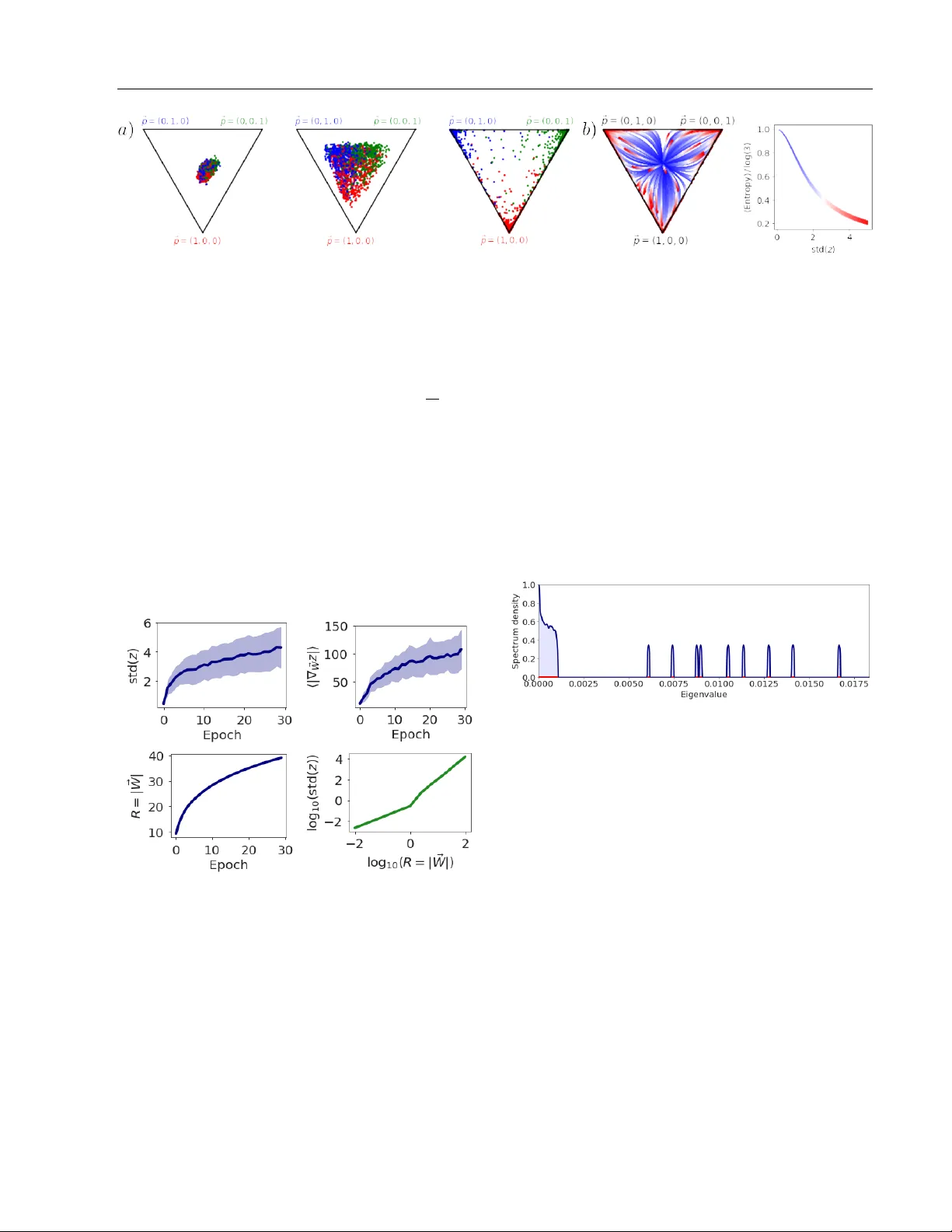
본 연구는 딥러닝에서 손실 함수의 지역 기하학이 학습 역학과 일반화에 미치는 영향을 탐구한다. 특히 분류 문제에 대해 최근 문헌에서 보고된 네 가지 현상—(1) Hessian 스펙트럼이 bulk와 정확히 C개의 outlier(클래스 수와 일치)로 구성, (2) 그라디언트가 이 C개의 top eigenvector가 형성하는 저차원 서브스페이스에 거의 전적으로 존재, (3) 학습 과정 중 top eigenvalue이 초기 상승 후 점차 감소하는 비단조적 변화, (4) 무작위 저차원 affine hyperplane에서도 초기 가중치가 “Goldilocks zone”(평균보다 높은 양의 곡률 영역)과 교차하면 성공적인 학습이 가능—을 하나의 통합 모델로 설명하고자 한다.
논문의 핵심 접근은 손실 함수 L(W)의 1차·2차 미분인 그라디언트 g와 Hessian H를 명시적으로 전개한 뒤, 몇 가지 실험적으로 타당한 근사화를 적용해 간단한 확률 모델을 도출하는 것이다. 손실은 softmax cross‑entropy이며, 로그잇 z_μk = F_W(x_μ) 로 정의된다. 그라디언트와 Hessian은 각각
g_α = (1/N) Σ_μ Σ_k (y_μk−p_μk) ∂z_μk/∂W_α
H_αβ = (1/N) Σ_μ Σ_k,l ∂z_μk/∂W_α p_μk(δ_kl−p_μl) ∂z_μl/∂W_β + (1/N) Σ_μ Σ_k (y_μk−p_μk) ∂²z_μk/∂W_α∂W_β
와 같이 두 항(G‑term, H‑term)으로 분리된다.
**주요 가정**
1. **로그잇 곡률 약함**: ∂²z/∂W²가 매우 작아 H‑term을 무시한다. 이는 NTK 가정과 일치하며, 실험적으로 H‑term이 bulk 스펙트럼을 담당한다는 증거를 제시한다.
2. **로그잇 그라디언트 클러스터링**: ∂z_μk/∂W는 클래스 k에 대해 강하게 클러스터링한다. 이를 수학적으로는 ∂z_μk/∂W = c_k + ε_μk 로 분해하고, c_k는 클래스별 평균 방향, ε_μk는 잔차(무작위)라고 가정한다. 클러스터링 정도는 코사인 유사도 지표 q_SLSC, q_SL, q_DL 로 측정했으며, q_SLSC와 q_SL이 q_DL보다 현저히 높았다.
3. **클래스 확률 고정**: 학습 전후로 softmax 확률 p_μk가 크게 변하지 않는다. 따라서 (y_μk−p_μk) 가 거의 일정한 값으로 남아, g와 H가 모두 c_k에 의해 좌우된다.
위 가정들을 적용하면 Hessian은
H ≈ (1/N) Σ_μ Σ_k,l p_μk(δ_kl−p_μl) c_k c_l^T
라는 형태가 된다. 여기서 c_k는 C개의 벡터만 존재하므로, H는 최대 C개의 비영 고유값을 가진 저랭크 매트릭스가 된다. 이는 관찰된 “C개의 고양성 곡률 방향”을 직접 설명한다. 또한 그라디언트는
g = (1/N) Σ_μ Σ_k (y_μk−p_μk) c_k
이므로, g 역시 동일한 C차원 서브스페이스에 완전히 포함된다. 따라서 (2)번 현상이 자연스럽게 설명된다.
학습 과정에서 초기에는 p_μk가 불균형하게 분포해 G‑term의 스케일이 크게 나타나 top eigenvalue이 상승한다. 시간이 흐르면서 p_μk가 점차 균등해지고, G‑term의 크기가 감소해 top eigenvalue이 감소한다. 이는 (3)번 비단조적 변화와 일치한다.
마지막으로, 파라미터를 무작위 저차원 초평면에 제한하는 경우를 생각한다. 초평면이 c_k가 형성하는 저차원 서브스페이스와 충분히 겹치면 (즉, Goldilocks zone에 위치하면) G‑term이 유지되어 손실의 양의 곡률이 충분히 커서 학습이 가능하다. 이는 (4)번 현상을 설명한다.
**실험 검증**
- 다양한 아키텍처(ResNet‑18/50, VGG‑16, MLP)와 데이터셋(CIFAR‑10/100, ImageNet, MNIST)에서 로그잇 그라디언트 클러스터링을 측정했다. q_SLSC와 q_SL은 0.6~0.8 수준으로 높았으며, q_DL은 0.1 이하로 거의 무작위 수준이었다.
- Hessian 스펙트럼을 직접 계산해 G‑term만 사용했을 때와 전체 Hessian을 사용했을 때를 비교했다. G‑term만으로도 outlier C개를 정확히 재현했고, H‑term은 bulk을 형성했다.
- 저차원 초평면 실험에서는 초기 가중치 분산 σ²를 조절해 Goldilocks zone을 탐색했다. σ²가 적절히 중간값일 때 Trace(H)/‖H‖가 크게 증가하고, 학습 성공률이 90% 이상으로 급상승했다. 반대로 너무 작거나 크게 하면 곡률이 낮아 학습이 실패했다.
**이론적 연계**
- **Neural Tangent Kernel**: 로그잇이 선형적으로 가중치에 의존한다는 가정은 NTK 무한폭 제한과 일치한다.
- **BBP 전이**: G‑term(저랭크)과 H‑term(랜덤) 사이의 스케일 비율이 BBP 전이 조건을 만족하면 outlier가 나타난다.
- **Derrida 랜덤 에너지 모델**: 손실을 고차원 랜덤 에너지와 유사하게 바라보면서, 저차원 구조가 전체 에너지 풍경을 지배한다는 점에서 연관성을 제시한다.
**결론 및 의의**
본 논문은 복잡한 신경망 손실 지형을 “저랭크 + 랜덤 매트릭스” 모델로 단순화함으로써, 네 가지 관찰된 현상을 통합적으로 설명한다. 이는 손실 곡률이 학습 역학을 어떻게 형성하는지에 대한 직관을 제공하고, 파라미터 차원 축소, 효율적인 초기화 설계, 그리고 일반화 이론 발전에 새로운 시각을 제시한다. 향후 연구에서는 이 모델을 이용해 일반화와 최적화 사이의 정량적 관계를 규명하거나, 비정규화된 데이터·비선형 활성화 함수에 대한 확장 가능성을 탐구할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기