이기종 3D NoC 설계를 위한 학습 기반 애플리케이션 불감형 최적화
초록
본 논문은 CPU·GPU·가속기 등 이기종 코어가 공존하는 3차원(3D) 많은 코어 시스템을 위해, 지연, 처리량, 에너지, 온도 네 가지 목표를 동시에 고려하는 다목적 최적화 프레임워크(MOO‑STAGE)를 제안한다. 트래픽 분석을 통해 대부분의 통신이 LLC(Last‑Level Cache) 중심의 ‘many‑to‑few’ 패턴임을 확인하고, 이를 기반으로 특정 애플리케이션에 종속되지 않은 일반화된 NoC 구조를 설계한다. 실험 결과, 온도 조건을 동일하게 유지하면서 평균 9.6% 향상된 Energy‑Delay Product(EDP)를 달성했으며, 36‑tile·64‑tile 시스템에서 애플리케이션‑특화 NoC 대비 각각 1.8%·1.1% 수준의 성능 손실만을 보였다.
상세 분석
이 논문은 이기종 3D many‑core 시스템에서 발생하는 상충되는 통신 요구사항을 체계적으로 해결하고자 한다. 먼저, CPU와 GPU가 각각 낮은 메모리 지연과 높은 대역폭을 요구한다는 점을 지적하고, 이러한 요구를 동시에 만족시키기 위해서는 전통적인 2D 메쉬 NoC가 한계에 봉착함을 설명한다. 3D IC의 TSV(Through‑Silicon Via) 활용은 전송 지연과 에너지 소비를 크게 낮출 수 있지만, 전력 밀도가 높아 열 hotspots 문제가 심화된다. 따라서 설계 목표를 ‘지연, 처리량, 에너지, 온도’ 네 가지로 정의하고, 이를 다목적 최적화 문제로 모델링한다.
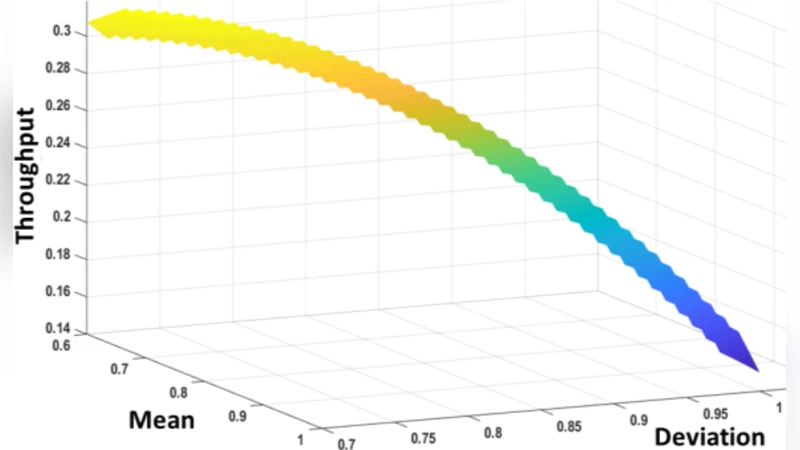
핵심 기여는 두 가지이다. 첫째, 다양한 벤치마크(머신러닝, 그래프 알고리즘, 물리 시뮬레이션 등)에서 수집한 트래픽 데이터를 기반으로, 이기종 시스템은 대부분 ‘many‑to‑few’ 패턴, 즉 다수의 GPU·CPU가 소수의 LLC와 집중적으로 통신한다는 공통적인 특성을 발견한다. 특히, 한 CPU가 마스터 역할을 수행하며 트래픽이 집중되고, GPU‑LLC 간 트래픽은 비교적 균등하게 분포한다. 이러한 패턴은 시스템 규모(36‑tile vs 64‑tile)와 무관하게 일관되며, 애플리케이션 별 차이는 상대적으로 미미함을 보여준다.
둘째, 이러한 트래픽 특성을 활용해 기존의 탐색 기반 MOO(예: NSGA‑II, AMOSA)보다 빠르고 확장 가능한 학습 기반 알고리즘 MOO‑STAGE를 제안한다. STAGE는 이전 탐색 경로를 메타‑학습하여 유망한 설계 영역을 사전에 예측하고, 탐색 효율을 크게 향상시킨다. 실험에서는 AMOSA와 최신 브랜치‑앤‑바운드 기법(PCBB)과 동일 수준의 파레토 최적 해를 얻으면서도 최적화 시간은 30% 이상 단축되었다.
다목적 최적화 결과, 온도 제한(iso‑temperature) 하에서 평균 9.6%의 EDP 개선을 달성했으며, 이는 온도‑성능 트레이드오프를 동시에 고려했을 때 얻을 수 있는 최대 이득이다. 또한, ‘애플리케이션‑불감형’ 설계는 특정 워크로드에 최적화된 설계와 거의 동일한 성능을 유지한다는 점에서, 설계 비용과 시간 절감 효과가 크다.
전반적으로, 이 논문은 트래픽 패턴 분석 → 애플리케이션‑불감형 설계 가설 → 학습 기반 MOO 알고리즘 적용이라는 일련의 흐름을 통해, 이기종 3D many‑core 시스템의 NoC 설계 문제를 실용적인 수준으로 끌어올렸다. 향후 연구에서는 더 다양한 가속기 유형(예: AI 전용 ASIC)과 동적 워크로드 변동성을 고려한 실시간 재구성 메커니즘을 추가하면, 제안 프레임워크의 적용 범위가 더욱 확대될 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기