개별 논문의 인용 동역학 예측과 확률적 한계
초록
본 논문은 저자들이 제안한 확률적 인용 모델을 이용해 개별 논문의 장기 인용 수를 예측하고, 예측 오차의 확률적 범위를 정량화한다. 핵심 변수인 ‘피트니스(η)’를 초기 2‑3년 인용량으로 추정하고, Hawkes‑type 자기강화 과정을 통해 미래 인용 흐름을 시뮬레이션한다. 결과는 피트니스가 높을수록 예측 불확실성이 감소함을 보여주며, ‘잠자는 미인’ 현상과 저자명 효과 등 한계 요인도 논의한다.
상세 분석
이 연구는 기존의 인용 예측 방법을 두 가지 축으로 구분한다. 하나는 사전 요인(제목, 저자 평판, 저널 등)을 머신러닝으로 학습하는 접근이고, 다른 하나는 사후 요인(초기 인용 기록)을 기반으로 인용 동역학을 모델링하는 접근이다. 저자는 후자를 선택해, 자신들이 2017년에 발표한 확률적 모델을 확장하였다. 모델의 핵심은 논문 j의 인용률 λ_j(t) 를 직접 인용(λ_dir)과 간접 인용(λ_indir)으로 분리하고, 이를 시간‑비동질 포아송 과정으로 가정한다. 수식 (2)에서 λ_j(t)=η_j R₀ Â(t)+∫₀^t m(t‑τ) T(t‑τ) k_j(τ) dτ 로 표현되는데, 여기서 η_j는 ‘피트니스’라 불리는 논문 고유의 강도 파라미터이며, R₀는 연도별 평균 참고문헌 수, Â(t)는 노화 함수, m(t)와 T(t)는 각각 해당 연도 논문의 평균 인용률과 구식화 함수를 의미한다. 두 번째 항은 과거 인용이 현재 인용을 촉진하는 자기강화 효과를 나타내며, 이는 Hawkes 프로세스로 해석된다. 따라서 인용 흐름은 본질적으로 확률적이며, 시간 경과에 따라 불확실성이 확대된다.
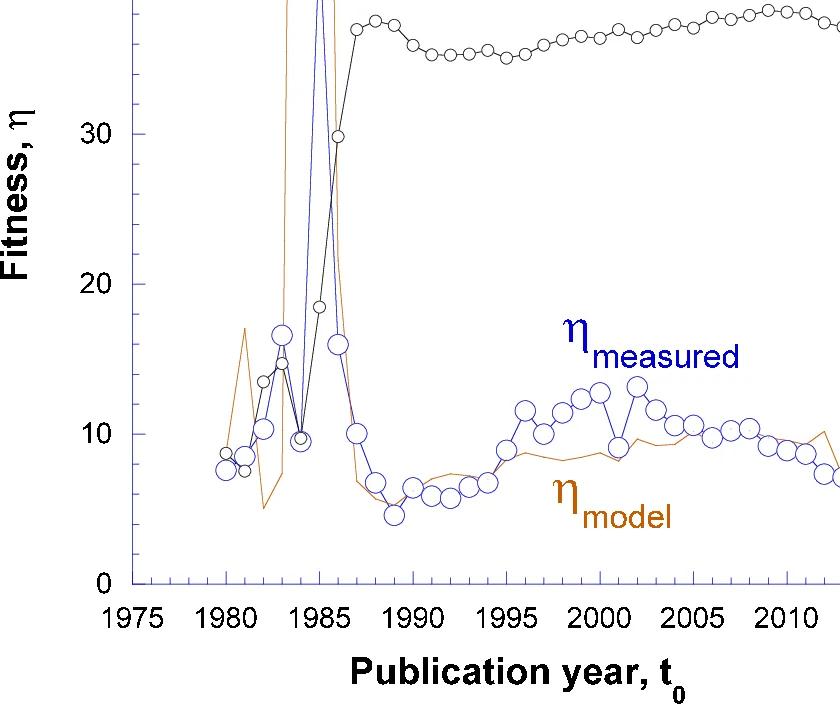
저자들은 피트니스 η가 알려졌을 때 장기 인용 기대값 K_∞(η)와 그 분포 폭을 수치 시뮬레이션으로 조사하였다. 1984년 물리학 논문 4,000편을 대상으로 25년 후 인용 수를 추정했으며, η와 K_∞ 사이에 K_∞∝η^{1.3}라는 거듭 제곱 관계가 나타났다. 또한 η가 낮은 논문은 인용 분포가 넓어 ‘우연’에 크게 좌우되는 반면, η가 높은 논문은 분포가 좁아 보다 결정론적인 성장 패턴을 보였다. 이는 피트니스가 높은 논문일수록 초기 인용이 직접 인용에 의해 주도되고, 자기강화 효과가 안정적으로 작동함을 의미한다.
피트니스 추정 방법으로는 초기 2‑3년 인용량을 활용한다. 저자는 초기 인용이 주로 직접 인용이므로, K_dir(3)≈η R₀ Â(3) 로부터 η를 역산한다. 실제 데이터에서 K_dir와 총 인용 K(3) 사이의 비선형 관계(K_dir≈K^{0.7})를 보정하여 피트니스를 보정한다. 이렇게 얻은 η는 논문의 ‘품질’ 혹은 ‘영향력’ 수준을 나타내는 지표로 활용될 수 있다.
하지만 모델은 ‘잠자는 미인’ 현상을 설명하지 못한다는 한계를 인정한다. 이러한 논문은 초기 인용이 거의 없지만, 몇 년 후 급격히 인용이 증가한다. 또한 저자명 순서나 첫 글자와 같은 비학문적 요인이 인용에 미치는 영향을 실험적으로 제시하며, 이는 피트니스 외의 외생 요인이 존재함을 시사한다.
마지막으로, 논문은 ‘시의성’이라는 개념을 피트니스에 정량적으로 반영한다. 새로운 연구 분야가 급성장할 때 해당 분야에 속한 논문의 피트니스가 상승한다는 가정 하에, 초기 급증하는 논문 수와 인용 패턴을 통해 분야의 ‘열기’를 측정할 수 있다. 전체적으로 이 연구는 인용 예측을 확률적 프레임워크 안에서 체계화하고, 예측 오차의 범위를 정량화함으로써 기존의 결정론적 예측 모델보다 현실적인 한계를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기