슬리퍼리한 닭 도축 이미지로 할랄 여부를 판별하는 딥러닝 모델 HalalNet
초록
본 논문은 도축 현장의 카메라 영상에서 닭의 목 절단 부위를 추출하고, 시암쌍둥이(Siamese) 구조와 Xception 기반 특징 추출기를 이용해 할랄·비할랄 도축을 구분하는 HalalNet을 제안한다. 데이터가 극히 불균형하고 총 30장의 비할랄 이미지만 확보된 상황에서 원샷 학습과 전이 학습을 결합해 96% 수준의 정확도를 달성하였다.
상세 분석
HalalNet은 전통적인 대규모 데이터 기반 딥러닝 접근법이 어려운 도축 현장에 적용하기 위해 원샷 학습(one‑shot learning)과 전이 학습(transfer learning)을 전략적으로 결합한 점이 가장 큰 특징이다. 시암쌍둥이 네트워크는 두 입력 이미지 사이의 유사도를 학습하도록 설계되었으며, 각 트윈 네트워크는 사전 학습된 ImageNet 가중치를 갖는 Xception 모델을 사용한다. 이는 299×299×3 입력을 10×10×2048 차원의 고차원 특징 맵으로 변환한 뒤, 두 특징 맵을 차원별 L1 차이로 결합하고 완전 연결층(FC) 2개와 시그모이드 출력층을 거쳐 “같은 클래스인지”를 확률로 반환한다.
데이터 전처리 단계에서는 YCbCr 색공간 변환 후 Otsu 이진화와 형태학적 연산(클로징·오프닝)을 적용해 목 절단 부위만을 강조한다. 그러나 비할랄 이미지가 전혀 다른 배경(컨베이어 외부)에서 촬영된 점을 감안하면, 배경 차이에 의해 모델이 과도하게 학습될 위험이 존재한다. 이를 완화하기 위해 원본 이미지와 세그멘테이션 이미지 모두를 학습에 포함하고, 세그멘테이션 데이터의 샘플링 비율을 두 배로 높여 모델이 절단 부위 자체에 집중하도록 유도하였다.
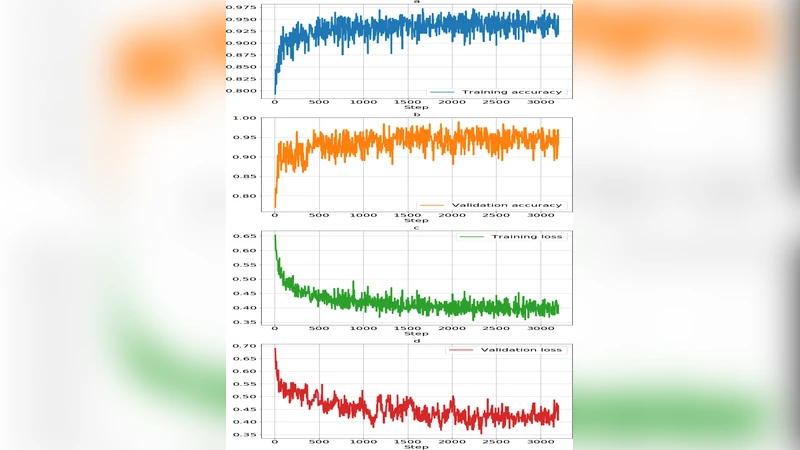
데이터 증강은 회전·이동·스케일·밝기 변환·플립·피스와이즈 어핀 변환 등 10가지 기법을 50% 확률로 적용해 실제 현장 조명·각도 변동을 시뮬레이션하고, 데이터 부족을 보완하였다. 학습은 Adam 옵티마이저(learning rate 1e‑4, decay 0.99)와 배치 크기 8, 3200 epoch을 사용했으며, L2 정규화와 Xavier 초기화를 통해 과적합을 억제하였다.
실험 결과, 전체 데이터(737 halal, 30 non‑halal)를 70:15:15 비율로 훈련·검증·테스트 셋으로 분할했을 때, 훈련 정확도 95.75%, 검증 정확도 96.00%를 기록하였다. 테스트 셋(256 쌍)에서는 정확도 96.48%, 정밀도 96.56%, 재현율 96.48%, F1 점수 96.48%를 달성했으며, 오분류는 주로 동일 클래스 쌍을 다른 클래스로, 혹은 그 반대로 혼동한 경우였다.
하지만 몇 가지 한계점도 명확하다. 첫째, 비할랄 샘플이 30장에 불과해 클래스 불균형이 심하고, 모델이 비할랄 특성을 충분히 학습했는지 의문이다. 둘째, 비할랄 이미지와 할랄 이미지의 촬영 환경 차이가 크게 나기 때문에, 실제 현장에서 비할랄 닭이 동일한 컨베이어에서 촬영될 경우 성능 저하가 예상된다. 셋째, 시암쌍둥이 구조는 쌍(pair) 기반 추론이 필요하므로 실시간 단일 이미지 판별에 추가 연산 비용이 발생한다. 넷째, 윤리적·법적 측면에서 도축 과정의 자동 감시가 종교적 규범을 완전히 대체할 수 있는지에 대한 논의가 부족하다.
향후 연구에서는 비할랄 데이터를 인위적으로 생성하거나, 도메인 적응(domain adaptation) 기법을 도입해 배경 차이를 최소화하고, 트리플렛 손실(triplet loss)이나 대조 학습(contrastive learning)으로 임베딩 공간을 보다 견고하게 만들 수 있다. 또한, 경량화된 단일 이미지 분류기로 전환하거나, Edge TPU와 같은 임베디드 하드웨어에 최적화해 현장 실시간 적용성을 높이는 방안도 고려해야 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기