부분관측 강화학습을 이용한 로봇 보행 자세 최적화
본 논문은 주기적인 입력에 의해 생성된 제한궤도(limit cycle)를 단일 위상 변수로 축소하고, 피드백 입자 필터(FPF)로 위상에 대한 사후 분포를 추정한 뒤, Q‑learning 기반의 연속시간 Q‑함수(해밀토니안) 근사 학습을 통해 부분관측 환경에서 로봇의 최적 보행 자세를 학습하는 프레임워크를 제안한다. 두 몸체 평면 모델을 시뮬레이션으로 검증하였다.
저자: Tixian Wang, Amirhossein Taghvaei, Prashant G. Mehta
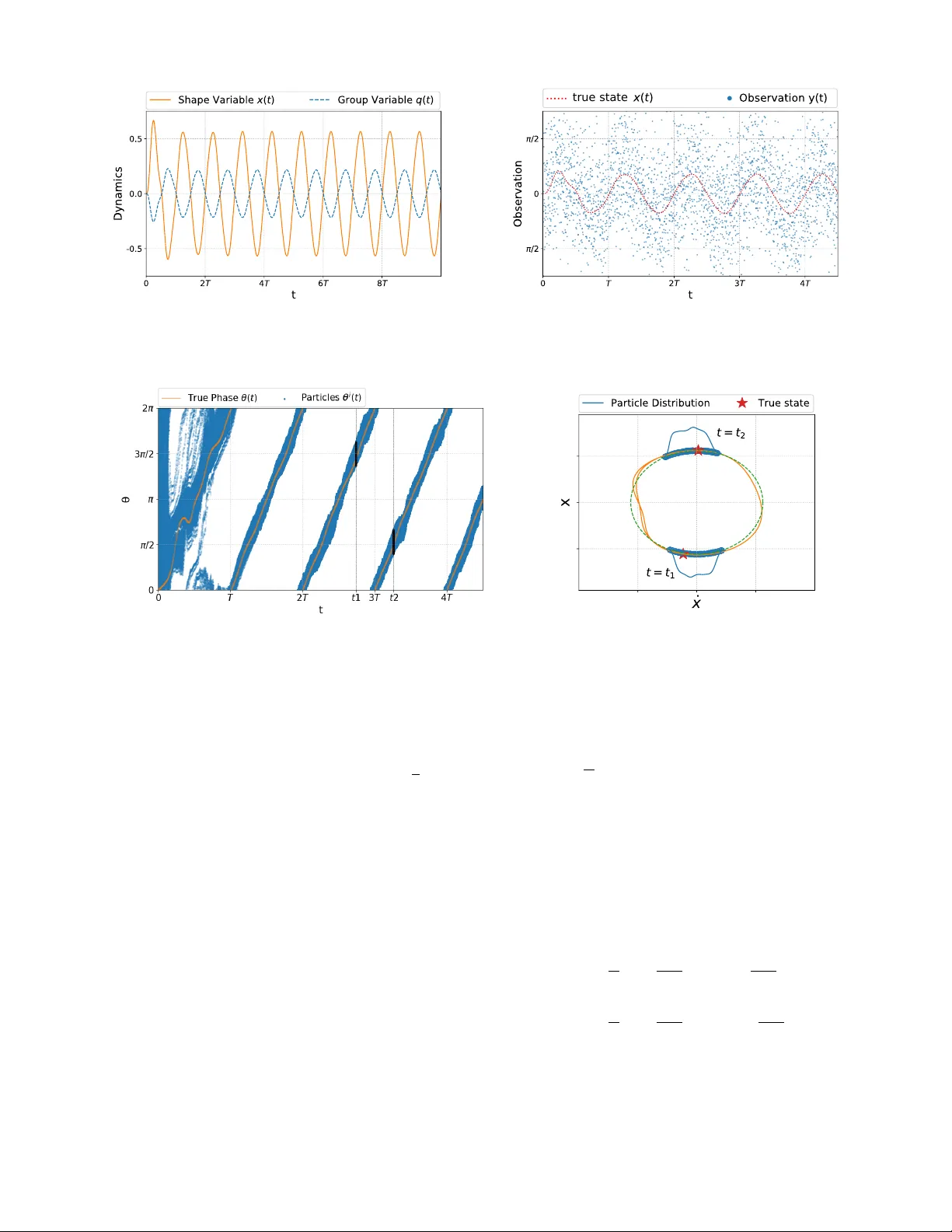
본 논문은 부분관측 마코프 결정 과정(POMDP) 하에서 로봇의 최적 보행 자세를 학습하기 위한 새로운 프레임워크를 제안한다. 연구 배경은 생물학적 보행이 주기적인 형태 변화를 통해 전역 이동을 달성한다는 점이며, 이러한 주기성은 로봇 시스템에서도 제한궤도(limit cycle) 형태로 나타난다. 저자는 먼저 로봇의 고차원 구성공간을 “형상 변수(내부 자유도)와 군집 변수(전역 위치·방향)”로 분리하고, 외부 주기 토크 τ(t)=τ₀ sin(ω₀t) 에 의해 형상 변수가 안정적인 제한궤도를 형성한다는 가정을 둔다. 이 제한궤도는 위상 변수 θ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기