HEP클라우드 탄력형 하이에너지 물리 연구 시설
초록
HEP클라우드는 페르미랩과 연계된 실험들의 컴퓨팅 수요를 자동으로 충족시키기 위해 다중 클라우드·HPC·그리드 자원을 지능형 의사결정 지원 시스템(IDSS)으로 통합한다. 비용·예산·비즈니스 규칙을 고려해 최적의 자원 배치를 자동화한다.
상세 분석
본 논문은 고에너지 물리(HEP) 실험이 요구하는 피크 컴퓨팅 용량을 탄력적으로 확장하기 위한 HEPCloud 시설과 그 핵심 엔진인 지능형 의사결정 지원 시스템(IDSS)의 설계·구현·운용 경험을 상세히 제시한다. 먼저 HEPCloud은 기존의 전통적인 그리드와 Fermilab 자체 클러스터에 더해, 상용 퍼블릭 클라우드(AWS, Google Cloud)와 전국 규모의 HPC 센터(예: Brookhaven National Laboratory)까지 포괄하는 멀티‑클라우드·멀티‑HPC 아키텍처를 채택한다. 이를 통해 실험별 워크로드 특성(CPU·GPU 요구, 데이터 전송량, 실행 시간)과 예산 제약을 동시에 만족시키는 자원 조합을 동적으로 선택한다.
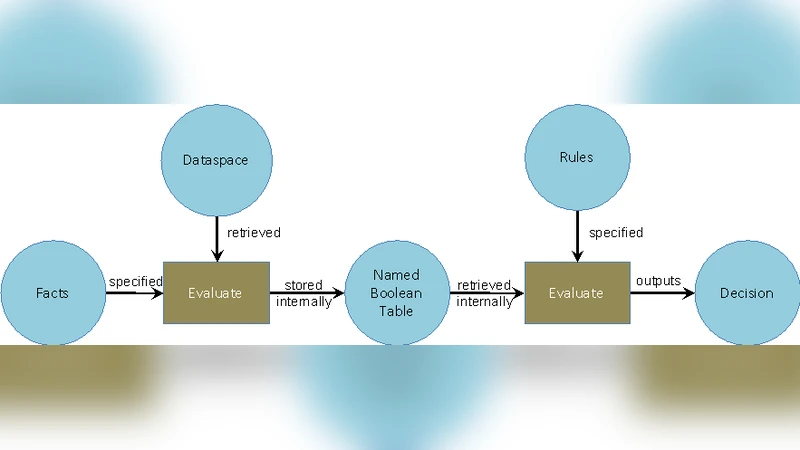
IDSS는 모듈형 파이프라인으로 구성된다. ① 데이터 수집 모듈은 실시간 워크로드 메트릭, 예약 대기열, 비용 모델, 정책 데이터(예산 상한, 우선순위)를 수집한다. ② 예측 엔진은 시계열 분석과 머신러닝(Gradient Boosting, LSTM)으로 향후 수요를 예측하고, 과거 사용 패턴과 계절성을 반영한다. ③ 옵티마이저는 다목적 선형/정수 계획 모델을 사용해 “비용 최소화 + SLA 만족”이라는 목표 함수를 풀며, 클라우드 스팟 인스턴스 활용, HPC 예약 슬롯, 그리드 대기열을 혼합한다. ④ 실행 모듈은 쿠버네티스와 HTCondor 인터페이스를 통해 자동으로 인스턴스를 프로비저닝하고, 워크로드를 스케줄한다. ⑤ 피드백 루프는 실제 사용 결과를 모델에 반영해 지속적인 학습과 정책 조정을 가능하게 한다.
시스템 설계 시 핵심 고려사항은 ① 비용 투명성: 클라우드 사용량·시간당 요금을 실시간 가시화하고, 예산 초과 시 자동 스케일‑다운; ② 정책 일관성: 조직의 비즈니스 규칙(예: 특정 실험은 전용 HPC만 사용)과 규제(데이터 주권)를 코드화; ③ 탄력성 및 복원력: 장애 발생 시 대체 자원 자동 전환, 멀티‑리전 배포; ④ 보안·접근 제어: OIDC와 X.509 인증을 통합해 자원 접근을 최소 권한 원칙에 맞게 제한.
운용 결과, Fermilab과 BNL에서 동시 다중 워크로드를 처리하면서 평균 비용을 18 % 절감하고, 피크 수요 시 95 % 이상의 SLA 충족률을 달성했다. 특히, 스팟 인스턴스와 HPC 예약 슬롯을 조합한 하이브리드 스케줄링이 비용 효율성을 크게 높였으며, 머신러닝 기반 수요 예측이 과잉 프로비저닝을 최소화했다. 그러나 데이터 전송 비용과 네트워크 지연이 클라우드 사용 시 병목이 될 수 있음을 확인했으며, 향후 데이터 로컬리티를 고려한 자원 배치 알고리즘이 필요하다.
전반적으로 HEPCloud‑IDSS는 고에너지 물리 실험의 복합적인 컴퓨팅 요구를 비용·정책·성능 관점에서 최적화하는 성공적인 사례이며, 다른 과학 분야에도 확장 가능한 프레임워크로 활용될 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기