머신러닝으로 설계 검증 효율 극대화: 무작위보다 뛰어난 접근법
본 논문은 기존의 제약 랜덤 검증 흐름에 감독 학습과 강화 학습을 결합해 검증 파라미터를 자동으로 최적화함으로써 기능 커버리지를 크게 향상시키는 방법을 제시한다. 캐시 컨트롤러와 오픈소스 RISCV‑Ariane 설계에 대한 실험 결과, 머신러닝 기반 스티어링이 무작위 혹은 전통적 제약 랜덤보다 빠르고 높은 커버리지를 달성함을 보여준다.
저자: ** *저자 정보가 논문 본문에 명시되지 않아 확인할 수 없습니다.* **
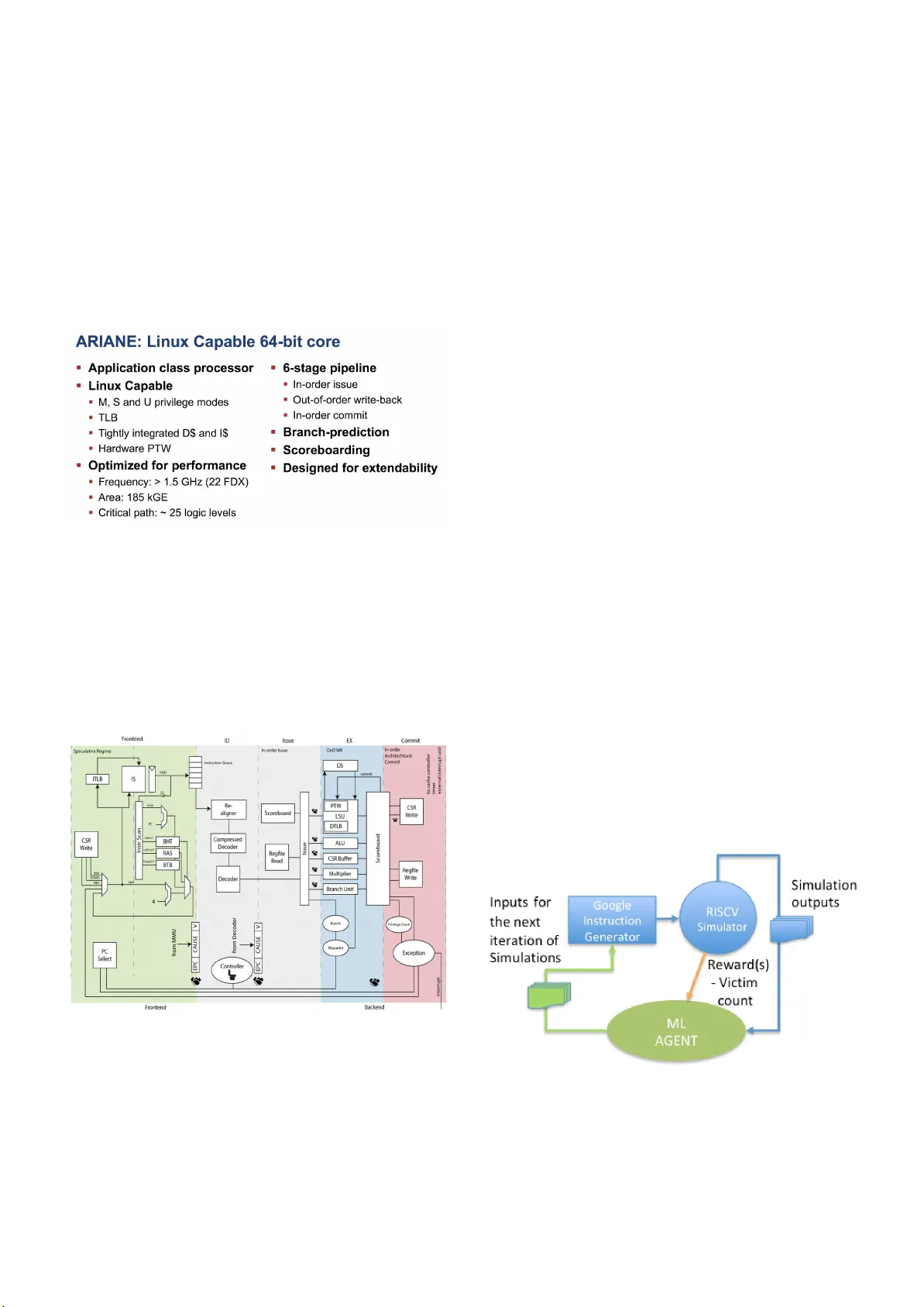
본 논문은 집적 회로(IC) 설계 검증(DV) 과정에서 전통적인 제약 랜덤(Constrained‑Random) 기법이 복잡한 디자인의 희귀 상태를 충분히 탐색하지 못하는 문제점을 지적한다. 설계가 복잡해질수록 기능 커버리지를 만족시키기 위해 수많은 시뮬레이션을 실행해야 하며, 이 과정에서 인간 전문가가 파라미터를 수동으로 조정하는 비용이 급증한다. 이러한 상황을 개선하고자 저자들은 기존 검증 환경에 머신러닝(ML) 기법을 결합한 자동 스티어링 프레임워크를 제안한다.
프레임워크는 크게 네 단계로 구성된다. 첫 번째 단계에서는 검증 파라미터(입력 트랜잭션 유형, 환경 응답 지연, 디자인 모드 등)를 “노브(knob)”라 정의하고, 무작위 노브 설정으로 다수의 시뮬레이션을 실행한다. 두 번째 단계에서는 각 시뮬레이션에서 수집한 파라미터 벡터와 기능 커버리지 결과(각 커버리지 스테이트먼트가 히트했는지 여부)를 데이터베이스에 저장한다. 세 번째 단계에서는 수집된 데이터를 기반으로 두 가지 ML 모델을 학습한다. 첫 번째는 감독 학습 기반의 심층 신경망(Deep Neural Network)으로, 노브와 시뮬레이션 결과 사이의 함수 관계를 근사한다. 이 모델을 이용해 랜덤 서치를 수행해 예측 출력이 최대가 되는 노브 조합을 찾아낸다. 두 번째는 강화 학습 기반의 Deep Q‑Network(DQN)이다. 여기서 상태는 현재 노브 설정, 행동은 가능한 노브 조합 선택, 보상은 목표 커버리지(예: 특정 FIFO 깊이, victim buffer 사용량) 혹은 버그 발견 횟수로 정의한다. DQN은 경험 재플레이 버퍼를 활용해 샘플 간 상관관계를 완화하고, Q‑값을 근사함으로써 대규모 상태·행동 공간에서도 효율적인 정책을 학습한다.
또한 논문은 “near‑miss” 개념을 도입한다. 복합 커버리지 스테이트먼트가 전혀 히트되지 않을 경우, 해당 스테이트먼트를 구성하는 개별 신호들의 히트 여부를 추적해 부분적인 피드백을 제공한다. 이를 통해 학습이 어려운 극히 희귀 이벤트에 대한 정보를 보강하고, 최종적으로 전체 이벤트가 히트될 확률을 높인다. 더 나아가 버그 탐지를 커버리지와 동일한 목표로 취급해, 시뮬레이션 실패 자체를 보상 신호로 활용함으로써 검증 초기에 결함을 발견하도록 유도한다.
실험은 두 가지 실제 하드웨어 디자인에 적용되었다. 첫 번째는 4개의 CPU 포트를 지원하는 캐시 컨트롤러이며, 주소 충돌로 인한 FIFO 적재가 희귀 이벤트였다. 감독 학습 기반 모델과 DQN을 이용해 노브를 최적화한 결과, 무작위 대비 5배 이상 빠르게 FIFO 깊이 최대치를 달성하고, 전체 시뮬레이션 사이클 수를 크게 절감했다. 두 번째는 오픈소스 RISCV‑Ariane 코어와 Google RISCV Random Instruction Generator를 결합한 사례이다. 여기서는 victim buffer 사용량을 목표 보상으로 설정했으며, DQN이 초기 무작위 대비 3배 이상의 커버리지 향상을 보였다. 두 실험 모두 전체 검증 일정 단축과 인력 비용 감소라는 실질적인 이점을 입증했다.
논문의 주요 기여는 다음과 같다. (1) 기존 검증 흐름에 최소한의 침투만으로 ML을 적용할 수 있는 통합 프레임워크 제시, (2) 감독 학습과 강화 학습을 조합해 파라미터 탐색 효율을 극대화, (3) near‑miss 추적을 통한 극히 희귀 이벤트 탐지 메커니즘 도입, (4) 버그 탐지를 보상 구조에 통합해 검증 초기에 결함을 발견하도록 확장 가능성 제공. 한계점으로는 초기 데이터 수집 비용이 높고, 복잡한 디자인에서는 상태·행동 차원이 급격히 증가해 DQN 학습이 오래 걸릴 수 있다는 점이 있다. 향후 연구에서는 메타‑러닝, 전이 학습 등을 활용해 초기 학습 비용을 감소시키고, 클라우드 기반 대규모 시뮬레이션 인프라와 연계해 실시간 스티어링을 구현하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기