테스트 파손 방지와 복구 기술에 대한 체계적 문헌 고찰
초록
본 논문은 소프트웨어 진화 과정에서 발생하는 테스트 케이스 파손을 예방·복구하는 연구들을 체계적으로 정리한다. 목표‑질문‑측정(GQM) 기반으로 41편의 주요 논문을 선정·분석했으며, 파손 원인 분류와 현재 공개된 복구 도구 현황을 제시한다. 대부분이 오픈소스 사례에 기반하고, 산업 현장 적용 연구와 공개 도구가 현저히 부족함을 지적한다.
상세 분석
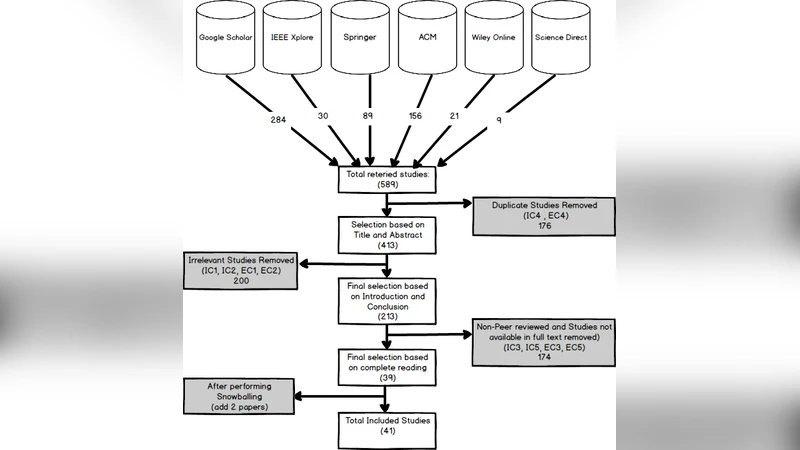
본 연구는 테스트 케이스 파손 방지와 복구라는 좁지만 실무적 파급력이 큰 영역을 메타분석한다. 먼저 GQM 프레임워크를 적용해 “테스트 파손 원인 파악”, “복구 기법의 효과성 평가”, “산업 적용 가능성” 등 세 가지 목표를 설정하고, 각각에 대응하는 구체적 질문을 도출하였다. 검색 전략은 주요 디지털 라이브러리(IEEE Xplore, ACM DL, Scopus 등)를 활용했으며, 2010년부터 2023년까지 발표된 논문을 대상으로 키워드(‘test repair’, ‘test breakage’, ‘test maintenance’ 등)를 조합했다. 포함 기준은 (1) 테스트 케이스 파손을 직접 다루는 연구, (2) 실험적 평가를 제공하는 논문, (3) 영어·한국어 논문 모두 포함했으며, 배제 기준은 설문·이론적 고찰만을 다루는 논문이었다.
선정된 41편 중 5편은 저널, 36편은 학술대회 논문으로, 이는 해당 분야가 아직 학술지 수준보다는 워크숍·컨퍼런스 중심임을 시사한다. 연구자는 각 논문에서 제시된 파손 원인을 코드 변경 유형(시그니처 변경, API 폐기, 로직 수정 등), 테스트 의존성(외부 서비스, 데이터베이스, 파일 시스템) 및 환경 요인(플랫폼 차이, 설정 파일) 등으로 분류해 7개의 카테고리로 정리하였다.
복구 기법은 크게 (1) 변형 기반 자동 수정, (2) 시맨틱 분석을 통한 재작성, (3) 메타테스트(테스트 자체를 테스트) 접근, (4) 머신러닝 기반 예측·제안 등으로 구분된다. 이 중 실제 도구로 구현된 사례는 4개에 불과했으며, 공개 저장소(GitHub 등)에 배포된 것은 두 개뿐이다. 도구들의 공통적인 제한점은 (① 제한된 언어 지원, ② 특정 프레임워크에 종속, ③ 대규모 프로젝트 적용 시 성능 저하)이며, 특히 산업 현장에서의 적용 사례가 거의 보고되지 않았다.
평가 방법론을 살펴보면, 대부분이 오픈소스 프로젝트(예: Apache, Eclipse, JUnit)에서 파손 테스트 비율, 복구 성공률, 유지보수 비용 절감 효과 등을 정량화했다. 평균 복구 성공률은 62% 수준이었지만, 테스트 정확도(오탐·누락)와 복구 후 회귀 테스트 비용 증가가 부수적인 문제로 지적되었다. 또한, 실험 설계의 내부 타당성을 확보하기 위해 교차 검증, 베이스라인(기존 수동 복구)과의 비교를 수행했지만, 외부 타당성—특히 산업 현장 적용 가능성—에 대한 검증은 거의 이루어지지 않았다.
위협 요인으로는 (① 검색 키워드와 데이터베이스 선택에 따른 논문 누락, ② 선택 편향(주로 영어 논문 중심), ③ 평가 지표의 비표준화) 등을 제시한다. 저자는 이러한 한계를 보완하기 위해 향후 메타데이터 표준화, 산업 파트너와의 공동 연구, 그리고 도구의 오픈소스화·플러그인화가 필요하다고 주장한다.
전체적으로 본 논문은 테스트 파손 방지·복구 연구의 현황을 명확히 제시하고, 도구·데이터·산업 적용이라는 세 축에서의 격차를 강조한다. 이는 학계와 실무 모두에게 향후 연구 로드맵을 제공하는 중요한 기여라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기