컴파일러 수준에서 GEMM 최적화를 위한 탐색 기반 알고리즘 연구
초록
본 논문은 TVM 프레임워크 위에서 GEMM 연산을 최적화하기 위해 두 가지 새로운 탐색 알고리즘인 Greedy‑Best‑First‑Search(G‑BFS)와 Neighborhood Actor‑Advantage‑Critic(N‑A2C)를 제안한다. MDP 기반 상태·행동 모델링을 통해 이웃 구성들을 정의하고, 제한된 탐색 공간(0.1%)만을 조사하면서도 XGBoost와 RNN 기반 튜너 대비 각각 24%, 40%의 실행 시간 절감을 달성하였다.
상세 분석
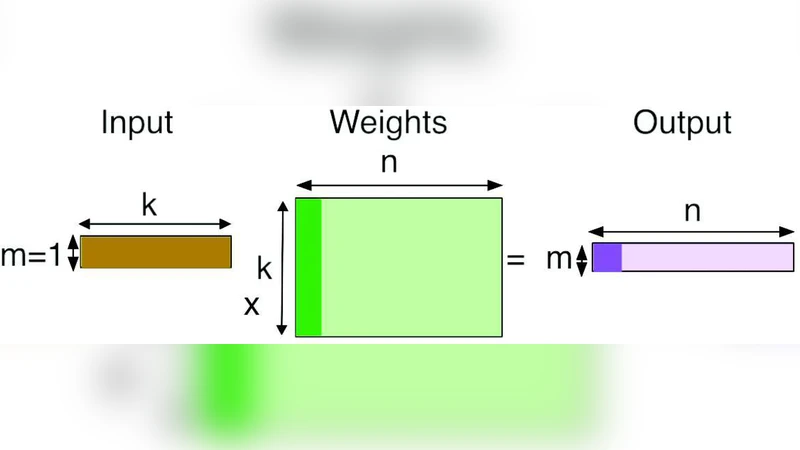
이 논문은 딥러닝 프레임워크가 하드웨어‑특화 라이브러리에 의존하는 현상을 비판하고, 컴파일러 단계에서 연산자를 자동으로 튜닝할 필요성을 강조한다. GEMM은 3중 루프 구조와 다중 차원의 타일링 파라미터(예: m‑dim, k‑dim, n‑dim)로 표현될 수 있으며, 각 파라미터 조합은 실행 시간이라는 비용 함수를 가진 고차원 탐색 공간을 형성한다. 저자들은 이 공간을 마코프 결정 과정(MDP)으로 모델링하여, 하나의 구성(state)을 이웃 구성으로 변환하는 행동(action)을 “두 배 증가·반감” 연산으로 정의한다. 이렇게 하면 인접 상태 간 비용 변화가 연속적이라는 가정 하에 탐색 효율을 크게 높일 수 있다.
첫 번째 제안인 G‑BFS는 우선순위 큐에 현재까지 발견된 최저 비용을 기준으로 후보를 정렬하고, 가장 유망한 상태를 꺼내 이웃을 확장한다. 탐색 과정에서 이미 방문한 상태를 기록해 중복을 방지하고, 초기 상태를 무작위 혹은 도메인 지식 기반으로 설정한다. 이 방법은 탐욕적이지만, 타일링 파라미터가 정수이며 곱셈 제약을 만족해야 하는 경우에도 빠르게 수렴한다는 장점이 있다.
두 번째 제안인 N‑A2C는 강화학습 기반 정책 최적화를 적용한다. Actor 네트워크는 현재 상태에서 가능한 행동을 선택하고, Critic 네트워크는 해당 행동 후의 기대 비용을 추정한다. Advantage 함수는 실제 비용과 Critic이 예측한 비용 차이를 이용해 정책 업데이트에 사용된다. 특히 “Neighborhood”라는 명칭은 인접 상태만을 탐색하도록 제한함으로써 탐색 공간을 0.1% 수준으로 축소하면서도 높은 성능을 유지하도록 설계되었다.
실험은 NVIDIA Titan XP GPU를 대상으로 1024×1024 매트릭스 곱셈을 수행했으며, XGBoost 기반 튜너와 RNN‑controller 튜너를 베이스라인으로 삼았다. G‑BFS는 XGBoost 대비 24% 빠른 실행 시간을, N‑A2C는 RNN 대비 40% 빠른 실행 시간을 기록했다. 두 방법 모두 전체 구성 공간의 0.1%만을 평가했음에도 불구하고, 최적에 근접한 솔루션을 찾아냈다. 이는 탐색 비용(시간·리소스)과 최적성 사이의 트레이드오프를 크게 개선한 결과라 할 수 있다.
또한 논문은 제안된 탐색 프레임워크가 GEMM 외에도 컨볼루션, 완전 연결 레이어와 같은 다른 연산자 튜닝에 확장 가능함을 언급한다. MDP와 이웃 정의를 일반화하면, 다양한 하드웨어(CPU, GPU, FPGA, ASIC)와 다양한 연산자에 대해 자동화된 최적화 파이프라인을 구축할 수 있다.
요약하면, 이 연구는 (1) GEMM 타일링 공간을 정형화된 MDP로 모델링, (2) 이웃 관계를 활용한 경량 탐색(G‑BFS)과 강화학습(N‑A2C) 두 가지 알고리즘을 설계, (3) 제한된 탐색 비율에서도 기존 최첨단 튜너를 크게 앞서는 성능을 입증함으로써, 컴파일러‑레벨 연산자 최적화에 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기