이질성 인식 비동기 분산 학습 Ripples
Ripples는 부분 All‑Reduce와 정적 그룹 스케줄링을 결합해 동기화 비용을 최소화하고, 그룹 버퍼·분할 기법으로 충돌을 억제한다. 이를 통해 동질 환경에서는 All‑Reduce 수준의 속도를, 이질 환경에서는 AD‑PSGD보다 두 배 이상의 가속을 달성한다.
저자: Qinyi Luo, Jiaao He, Youwei Zhuo
**1. 연구 배경 및 동기**
데이터 병렬 학습은 대규모 모델을 빠르게 학습시키기 위해 여러 GPU/노드에 모델 복제본을 두고 동시에 학습한다. 이때 매 반복마다 **동기화**가 필수적인데, 기존 방법은 크게 두 가지로 나뉜다. 첫째, **Parameter Server(PS)**는 중앙 서버가 모든 워커의 그라디언트를 모아 업데이트한다. 통신 병목과 서버 과부하가 한계이며, 확장성이 떨어진다. 둘째, **All‑Reduce**는 링 구조를 이용해 전역 평균을 수행해 중앙 서버 없이도 높은 효율을 달성한다. 그러나 All‑Reduce는 **전역 장벽**을 도입해 가장 느린 워커가 전체 속도를 좌우한다는 이질성 문제를 안고 있다.
**2. 기존 대안과 한계**
분산 학습의 이질성 문제를 해결하기 위해 **AD‑PSGD**가 제안되었다. AD‑PSGD는 무작위 이웃 선택과 비동기 평균화로 스트래거러(straggler) 워커의 영향을 최소화한다. 하지만 구현 시 **데드락**이 발생할 수 있고, 원자성 보장을 위해 두 워커 간 동기화가 필요해 **동기화 오버헤드**가 크게 늘어난다. 또한, 그래프가 이분(bipartite) 형태여야만 정상 동작한다는 제약이 있다.
**3. Ripples 설계 목표**
- **동일 환경에서 All‑Reduce 수준의 성능**을 유지
- **이질 환경에서 AD‑PSGD와 동등하거나 더 나은 내성** 확보
- **데드락 및 과도한 동기화 비용 제거**
**4. 핵심 기술**
1) **Partial All‑Reduce**
- 전체 워커를 **다수의 서브그룹**(예: 8~16명)으로 나눈 뒤, 각 그룹 내에서 Ring All‑Reduce를 수행한다.
- 그룹 간 동기화는 최소화하고, 그룹 내부에서는 기존 All‑Reduce와 동일한 파이프라인을 활용해 높은 대역폭 활용도를 유지한다.
- 이렇게 하면 전체 동기화 라운드가 **그룹 수만큼** 감소해 지연 시간이 크게 줄어든다.
2) **정적 그룹 스케줄링**(동질 환경)
- 사전에 정의된 순서대로 그룹을 활성화한다. 한 그룹이 동기화를 마치면 다음 그룹이 시작되므로 **동시 충돌**이 발생하지 않는다.
- 이는 기존 AD‑PSGD에서 발생하는 “두 워커가 같은 파라미터를 동시에 평균화하려는” 상황을 원천 차단한다.
3) **Group Buffer & Group Division**(이질 환경)
- 워커가 느려질 경우, 해당 워커가 속한 그룹을 **버퍼에 저장**하고 다른 그룹이 먼저 진행하도록 한다.
- 일정 시점에 느린 워커가 다시 참여하도록 **그룹을 재분할**해 전체 진행률을 유지한다.
- 이 과정에서 무작위성을 약간 감소시키지만, 전체 수렴 속도에는 큰 영향을 주지 않는다.
**5. 알고리즘 흐름**
- 각 워커는 로컬 SGD를 수행하고, 일정 주기마다 **Partial All‑Reduce**를 호출한다.
- 그룹 스케줄러는 현재 활성화된 그룹을 결정하고, 해당 그룹 내 워커들만 평균화 작업을 수행한다.
- 평균화 과정에서 두 워커가 동시에 접근하면 **Group Buffer**에 한쪽을 임시 저장하고, 다른 워커가 먼저 완료되면 버퍼에 있던 작업을 이어서 수행한다.
- 이질 환경에서는 **Group Division** 로직이 작동해 느린 워커를 다른 그룹에 재배치한다.
**6. 구현 및 실험**
- 구현은 **NCCL** 기반 Ring All‑Reduce를 재활용했으며, Partial All‑Reduce와 그룹 관리 로직을 추가하였다.
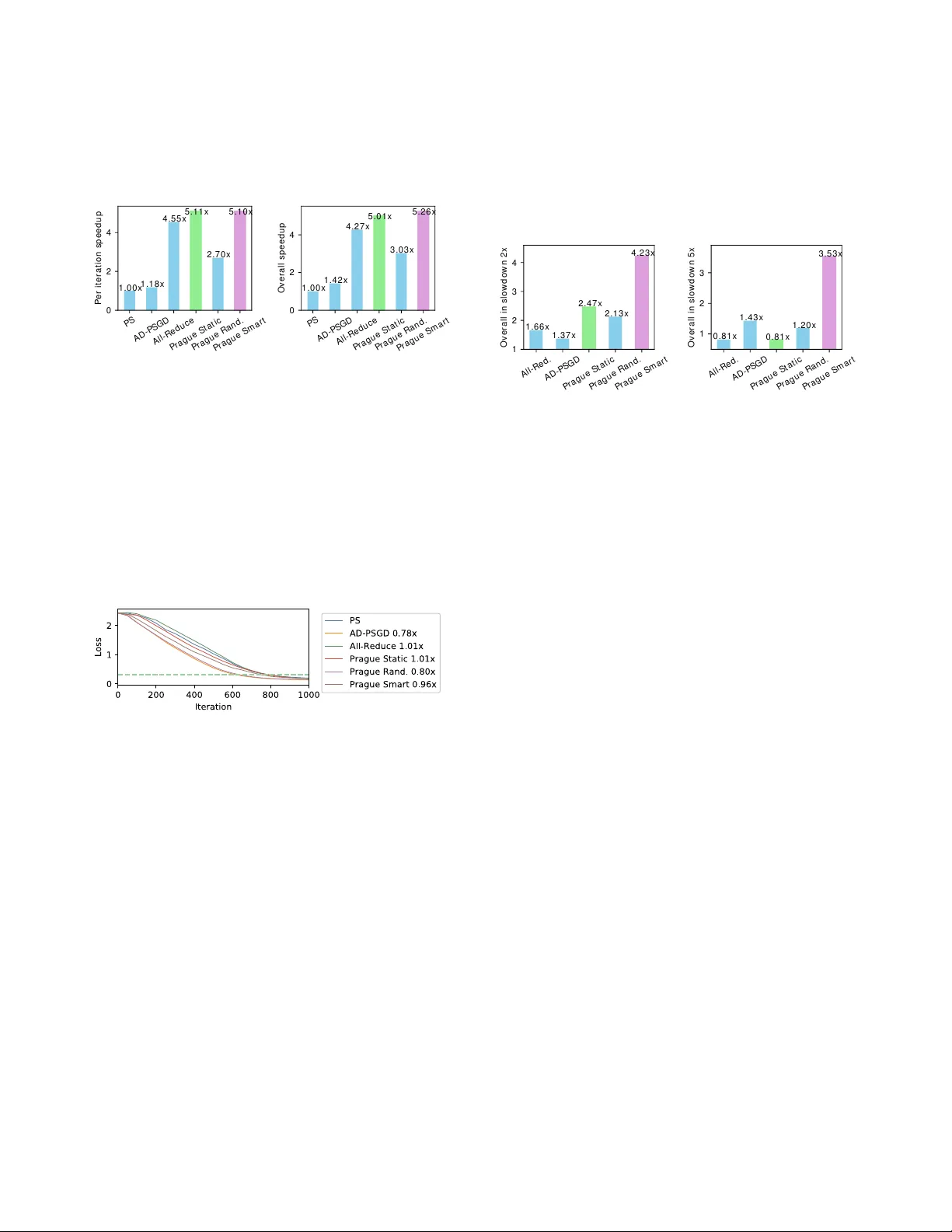
- 실험은 **Maverick2** 클러스터(TACC Supercomputer)에서 VGG‑16(CIFAR‑10)과 ResNet‑50(ImageNet) 모델을 사용해 수행했다.
- **동질 환경**: Ripples는 최신 All‑Reduce 구현보다 1.1배, PS보다 5.1배, AD‑PSGD보다 4.3배 빠른 학습 속도를 기록했다.
- **이질 환경**(한 워커 5배 느려짐): Ripples는 All‑Reduce 대비 2배, PS 대비 3배 이상의 가속을 달성했다.
- 수렴 곡선은 기존 AD‑PSGD와 유사하거나 더 빠른 수렴을 보였으며, 최종 정확도에도 차이가 없었다.
**7. 논의 및 한계**
- Partial All‑Reduce는 그룹 크기에 따라 최적 성능이 달라지며, 매우 큰 클러스터에서는 그룹 간 통신 비용이 다시 부각될 수 있다.
- 정적 스케줄링은 워크로드가 급격히 변할 경우 비효율적일 수 있어, 동적 스케줄링 기법과의 결합이 향후 연구 과제로 남는다.
- 현재 구현은 링 토폴로지를 전제로 하지만, 트리형이나 하이브리드 토폴로지에도 적용 가능하도록 확장할 여지가 있다.
**8. 결론**
Ripples는 **Partial All‑Reduce**와 **그룹 기반 충돌 회피** 기법을 통해 동기화 비용을 크게 낮추고, 이질성에 강인한 비동기 분산 학습을 구현했다. 실험 결과는 동질 환경에서 All‑Reduce와 동등하거나 더 나은 성능을, 이질 환경에서는 기존 방법들보다 현저히 높은 가속을 제공함을 입증한다. 이 연구는 알고리즘과 시스템 구현이 긴밀히 결합될 때 분산 딥러닝의 병목을 효과적으로 해소할 수 있음을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기