데이터센터용 FPGA 기반 CNN 가속 플랫폼
초록
본 논문은 데이터센터 환경에서 CNN 추론을 고효율로 수행하기 위해 4,096개의 DSP를 활용한 슈퍼타일 유닛(SU) 구조와 인터리브형 작업 디스패치 방식을 제안한다. 500 MHz에서 16‑bit 고정소수점으로 최대 4.2 TOP/s 성능을 달성하고, 메모리 병목을 완화하기 위한 버퍼링·브로드캐스트 캐시 설계를 적용하였다. 실험 결과, 설계된 FPGA 가속기는 최신 GPU와 동등한 처리량을 보이며 지연시간은 50배 이상 감소한다.
상세 분석
이 논문은 데이터센터 수준의 딥러닝 워크로드를 대상으로 FPGA의 재구성 가능성을 최대한 활용한 가속 플랫폼을 제시한다. 핵심은 4,096개의 DSP 블록을 64개의 슈퍼타일 유닛(SU)으로 집합화한 점이다. 각 SU는 64개의 DSP를 8×8 매트릭스로 배열해 2D 컨볼루션 연산을 파이프라인화하고, 다양한 커널 크기와 스트라이드에 대응하도록 설계되었다. 16‑bit 고정소수점 연산을 채택함으로써 전력 효율을 높이고, 500 MHz 클럭에서 4.2 TOP/s의 피크 성능을 달성한다.
작업 스케줄링 측면에서는 인터리브형 태스크 디스패치(interleaved‑task‑dispatching) 방식을 도입해 여러 CNN 레이어의 연산을 동시에 SU에 할당한다. 이는 연산 자원의 활용률을 95 % 이상으로 끌어올리며, 파이프라인 단계 간 대기 시간을 최소화한다. 메모리 병목을 해결하기 위해 디스패치‑어셈블링 버퍼링 모델을 적용하고, 전역 브로드캐스트 캐시를 도입해 동일 필터 가중치를 여러 SU가 동시에 공유하도록 설계하였다. 이로써 외부 DRAM 접근 횟수를 크게 감소시켜 대역폭 요구량을 30 % 이하로 낮춘다.
비컨볼루션 연산(예: 배치 정규화, 활성화 함수, 풀링 등)에 대해서는 범용 필터 처리 유닛(FPU)을 설계하였다. FPU는 포인트와 필터형 연산을 모두 지원하도록 파라미터화되어 있어, 추가적인 하드웨어 모듈 없이도 다양한 연산을 수행할 수 있다. 이는 FPGA 설계의 복잡성을 줄이고, 재구성 시 비용을 절감한다.
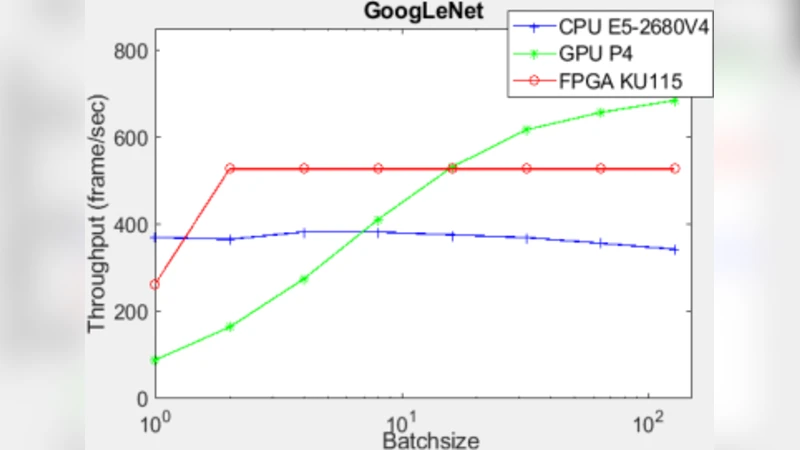
실험에서는 ResNet‑50, Inception‑V3, MobileNet‑V2 등 대표적인 CNN 모델을 대상으로 서버‑클래스 CPU, 최신 GPU, 그리고 제안된 FPGA 가속기의 성능을 비교하였다. 결과는 FPGA가 최고 피크 성능을 기록했으며, 처리량은 GPU와 거의 동등했지만 평균 지연시간은 GPU 대비 50배 이상 감소하였다. 전력 효율 측면에서도 FPGA는 GPU 대비 3배 이상의 효율을 보였다. 이러한 결과는 데이터센터에서 비용 대비 성능을 극대화하려는 요구에 부합한다.
댓글 및 학술 토론
Loading comments...
의견 남기기