해석 가능한 딥러닝, 보안 위협에 직면하다
초록
본 논문은 해석 가능한 딥러닝 시스템(IDLS)의 보안 취약점을 최초로 체계적으로 분석한다. 연구팀은 ‘ADV^2’라는 새로운 공격 기법을 제시하며, 이 공격이 대상 DNN 모델의 예측을 오도할 뿐만 아니라, 연결된 해석 모델의 결과도 조작할 수 있음을 실험을 통해 증명했다. 피부암 진단 등 보안이 중요한 응용 분야에서도 이러한 취약점이 존재함을 보였으며, 예측 모델과 해석 모델 사이의 ‘간극’이 근본 원인 중 하나로 지목되었다. 마지막으로 낮은 전이성 활용 및 적대적 훈련 프레임워크 통합과 같은 잠재적 대응 방안을 탐구한다.
상세 분석
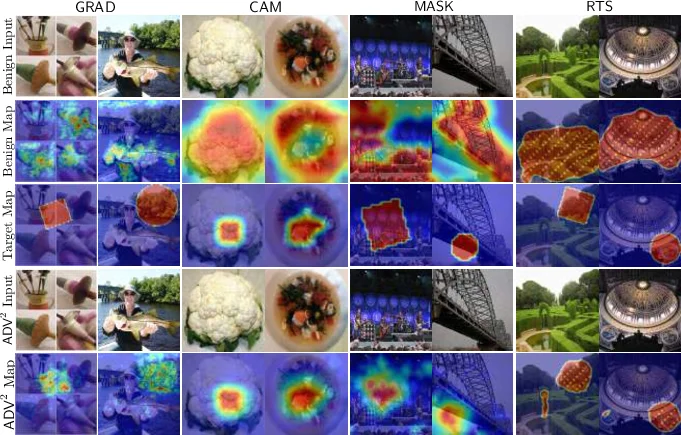
이 논문은 해석 가능성(Interpretability) 자체가 새로운 공격 표면이 될 수 있음을 경고하는 중요한 연구이다. 핵심 공격 기법인 ADV^2는 기존 적대적 예제 생성 프레임워크(예: PGD)를 확장하여, 손실 함수에 ‘해석 손실(interpretation loss)’ 항을 추가한다. 이로 인해 생성된 적대적 입력은 목표 클래스로 분류되도록 유도되는 동시에, 해석기가 생성하는 attribution map도 공격자가 지정한 특정 형태(예: 정상 샘플의 해석 결과와 유사한 형태)를 띠게 된다.
논문은 네 가지 주요 해석 기법 유형(Back-propagation-guided, Representation-guided, Model-guided, Perturbation-guided) 각각에 대한 ADV^2의 구체적인 구현 방법을 제시하며, 특히 ReLU 활성화 함수를 사용하는 모델에서 Gradient Saliency(Grad) 기법을 공격할 때 헤시안 계산의 한계를 극복하기 위한 ‘그래디언트 평활화(gradient smoothing)’ 기법과 같은 기술적 통찰을 제공한다.
가장 중요한 발견은 ‘예측-해석 간극(Prediction-Interpretation Gap)‘이다. 이는 분류기(DNN)의 내부 의사결정 논리와 해석기가 제공하는 설명이 완전히 정렬되지 않아, 두 모델을 동시에 활용하는 공격이 가능해지는 근본적 취약점이다. 이 간극은 해석 모델이 분류기의 복잡한 비선형성을 완전히 포착하지 못하기 때문에 발생한다.
대응책으로 논문은 두 가지 방향을 제시한다. 첫째, ADV^2 공격은 서로 다른 유형의 해석기 간 전이성(Transferability)이 낮다는 점을 지적하며, 다양한 원리의 해석기를 앙상블로 활용하는 방안을 제안한다. 둘째, ‘적대적 해석 증류(Adversarial Interpretation Distillation, AID)‘라는 새로운 적대적 훈련 프레임워크를 소개한다. AID는 ADV^2 공격을 훈련 과정에 통합하여 해석 모델의 견고성을 향상시키고, 궁극적으로 예측-해석 간극을 줄이는 것을 목표로 한다. 이 연구는 단순히 해석 가능성을 추가하는 것이 보안을 보장하지 않으며, 안전한 IDLS 설계를 위해서는 해석 모델의 견고성에 대한 본격적인 연구가 필요함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기