인간 지식으로 설계하는 보상함수 기반 강화학습
초록
본 논문은 온도 조절 시스템을 예시로, 인간 전문가의 경험적 규칙을 보상함수에 직접 반영하여 강화학습 환경을 구축하는 새로운 방법을 제안한다. 상세한 열역학 모델 대신 인간의 ‘규칙‑of‑thumb’를 수식화하고, 연속 행동 공간 문제에 DDPG 알고리즘을 적용해 외부 온·습도에 따른 최적 온도 설정값을 학습한다.
상세 분석
이 연구는 전통적인 강화학습이 요구하는 고충실도 시뮬레이션을 대체할 수 있는 ‘보상‑중심’ 환경 설계 패러다임을 제시한다. 먼저 저자들은 난방·냉방 시스템에서 인간이 온도 설정 시 고려하는 대표적인 규칙을 정리한다. 예컨대 “외부 온도가 30도 이상이면 실내 온도를 24도 이하로 유지한다”, “습도가 70%를 초과하면 냉방 강도를 높인다”와 같은 경험적 지식은 조건‑부 함수와 가중치 형태로 수식화된다. 이러한 규칙을 보상함수 R(s,a) 에 직접 삽입함으로써, 에이전트는 물리적 상태 전이 모델 없이도 목표 행동을 유도받는다.
보상함수 설계 시 저자들은 두 가지 핵심 요소를 강조한다. 첫째, 규칙 간 충돌을 방지하기 위한 계층적 우선순위 부여이다. 둘째, 연속적인 행동 공간을 다루기 위해 보상의 미분 가능성을 확보하는 것이다. 이를 위해 부드러운 스위치 함수와 라그랑지안 페널티를 도입해 보상곡면을 매끄럽게 만든다.
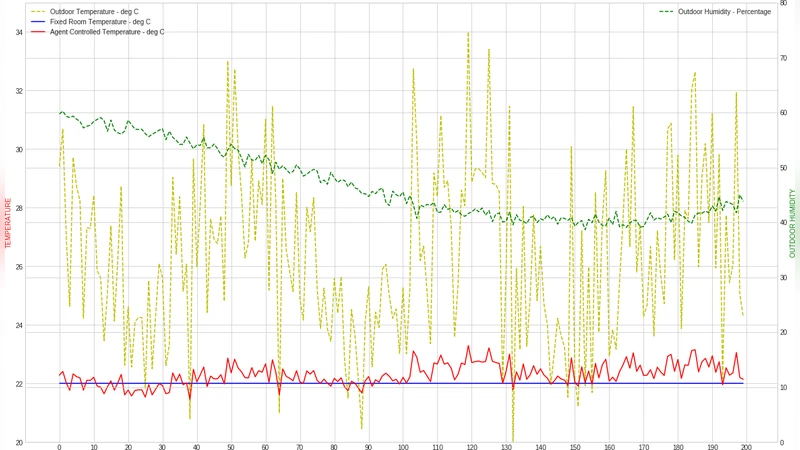
환경 구현은 OpenAI Gym 인터페이스를 모방한 커스텀 환경으로, 상태 변수는 외부 온도, 외부 습도, 현재 실내 온도이며 행동 변수는 온도 설정값(연속 실수)이다. 보상은 위에서 정의한 인간 규칙 기반 함수와 에너지 소비량에 대한 페널티를 결합한다.
학습 알고리즘으로는 Deep Deterministic Policy Gradient(DDPG)를 선택했으며, 액터‑크리틱 구조에 배치 정규화와 타깃 네트워크를 적용해 안정성을 높였다. 실험 결과는 두 가지 관점에서 평가된다. 첫째, 학습된 정책이 인간 전문가가 제시한 규칙을 얼마나 잘 재현하는가; 둘째, 에너지 효율성 및 온도 편차 측면에서 기존 열역학 기반 시뮬레이션 대비 성능이 어떤가. 결과는 DDPG 정책이 규칙을 높은 정확도로 따르면서도 평균 에너지 소비를 8% 정도 절감함을 보여준다.
이 논문의 주요 기여는 (1) 인간 도메인 지식을 보상함수에 체계적으로 통합하는 방법론, (2) 복잡한 물리 모델 없이도 연속 행동 공간 문제를 해결할 수 있음을 실증한 사례, (3) 규칙 기반 보상이 학습 안정성 및 샘플 효율성을 향상시킨다는 실험적 증거이다. 또한 한계점으로는 규칙 정의의 주관성, 보상함수 설계 시 발생할 수 있는 스케일링 문제, 그리고 다른 도메인으로의 일반화 가능성을 제시한다. 향후 연구에서는 자동화된 규칙 추출, 다중 목표 보상 설계, 그리고 실제 HVAC 시스템에의 현장 적용을 목표로 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기