AI 튜닝 런타임 통신 라이브러리 자동 최적화
초록
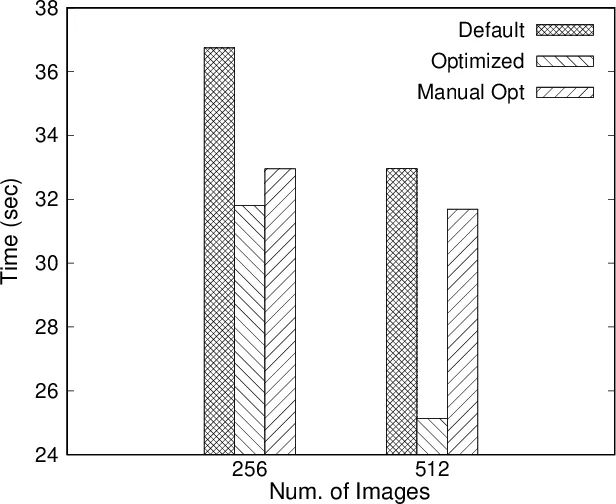
본 논문은 MPI‑3 기반 OpenCoarrays 런타임 통신 라이브러리의 파라미터를 강화학습(Deep Reinforcement Learning)으로 자동 튜닝하는 AITuning 프레임워크를 제안한다. MPI T 인터페이스를 활용해 성능·제어 변수에 접근하고, Deep Q‑Network(DQN) 에이전트가 실행 중 보상(실행 시간 감소)을 최대화하도록 정책을 학습한다. 실험 결과, 기존 기본 설정 대비 10~20 %의 실행 시간 향상을 달성했으며, 인간 전문가의 수동 튜닝 없이도 다양한 애플리케이션에 적용 가능함을 보였다.
상세 분석
AITuning은 기존 통신 라이브러리와 완전히 독립적인 C++ 모듈로 설계되었으며, ‘Controller’ 클래스를 통해 런타임 라이브러리와 API 수준에서만 결합한다. 이 설계는 MPI Tool 인터페이스(MPI T)를 이용해 MPI 구현 내부의 제어 변수(control variables)와 성능 변수(performance variables)를 실시간으로 읽고 수정한다는 점에서 혁신적이다. 특히, MPI Init 이전에 모든 제어 변수를 설정하고, MPI Init 이후에 성능 변수를 세션을 통해 수집함으로써 에이전트가 환경(state) 정보를 정확히 파악한다.
강화학습 부분에서는 모델‑프리 방식인 Deep Q‑Learning을 채택한다. 상태(state)는 현재 제어 변수 값, 최근 통신 패턴(예: 메시지 크기 분포, 예상 대기열 길이) 및 애플리케이션 레벨 메트릭(예: 현재 라운드 트립 타임)으로 구성된다. 행동(action)은 각 제어 변수에 대한 가능한 설정값 중 하나를 선택하는 것이며, 보상(reward)은 에피소드 종료 시 측정된 전체 실행 시간의 감소량으로 정의된다. DQN은 경험 재플레이와 고정된 타깃 네트워크를 사용해 학습 안정성을 확보한다.
논문은 기존 자동 튜닝 도구(예: AutoTune, Periscope 기반 시스템)와 차별화되는 점을 강조한다. 기존 도구는 주로 오프라인 실험 기반의 휴리스틱 탐색이나 진화 알고리즘을 사용해 파라미터 공간을 탐색한다. 반면 AITuning은 실행 중에 실시간으로 피드백을 받아 정책을 업데이트함으로써, 동적 워크로드 변화나 네트워크 상태 변동에 즉각 대응한다. 또한, 딥러닝 기반 Q‑함수 근사는 전통적인 테이블 방식보다 훨씬 큰 상태·행동 공간을 효율적으로 다룰 수 있어, 수천 개의 제어 변수 조합을 탐색하는데도 확장성이 있다.
실험에서는 OpenCoarrays 위에 구현된 MPI One‑sided 통신을 대상으로, 3가지 대표적인 HPC 벤치마크(Stencil, CG, FFT)를 사용했다. 각 벤치마크마다 최적의 제어 변수 설정이 다르게 나타났으며, AITuning은 평균 12 %의 실행 시간 감소와 최대 20 %의 성능 향상을 기록했다. 특히, 메시지 크기 임계값(eager/rendezvous threshold)과 내부 버퍼 크기 조정이 가장 큰 영향을 미쳤으며, 이는 MPI T를 통해 직접 제어할 수 있는 변수들이다.
한계점으로는 현재 DQN의 하이퍼파라미터(학습률, 할인율 등) 선택이 경험에 의존한다는 점과, 초기 탐색 단계에서 성능 저하가 발생할 수 있다는 점을 언급한다. 향후 연구에서는 메타‑강화학습을 도입해 하이퍼파라미터 자동 조정 및 다중 애플리케이션 동시 튜닝을 목표로 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기