테라 MAC per Watt 수준의 멀티플라이어 없는 대규모 병렬 신경망 가속기
초록
본 논문은 8비트 활성화와 1바이트 이하 정수 가중치를 이용해 곱셈 없이 행렬‑벡터 연산을 수행하는 구성 가능한 뉴럴 프로세싱 엘리먼트(NPE)를 제안한다. 멀티플라이어‑리스 대규모 병렬 프로세서(MMP) 기반의 TMA 가속기는 65 nm CMOS에서 1.0 V 전압 하에 2.3 TMAC·W의 에너지 효율을 달성했으며, AlexNet 기반 벤치마크에서 기존 최고 수준 대비 전력·면적 모두 우수한 성능을 보였다.
상세 분석
본 연구는 딥러닝 추론 가속기의 핵심 효율 지표인 MACs/W를 극대화하기 위해 ‘멀티플라이어‑리스(Multiplier‑less)’ 설계 철학을 채택하였다. 전통적인 MAC 기반 가속기는 곱셈 연산에 높은 전력 비용이 집중되는 반면, TMA는 8‑bit 활성화와 1‑byte 이하 정수 가중치를 이용해 시프트·시그마 연산으로 곱셈을 대체한다. 이는 곱셈 회로를 완전히 제거함으로써 스위칭 전력을 크게 낮추고, 동시에 고밀도 병렬성을 확보한다는 두 마리 토끼를 잡는다.
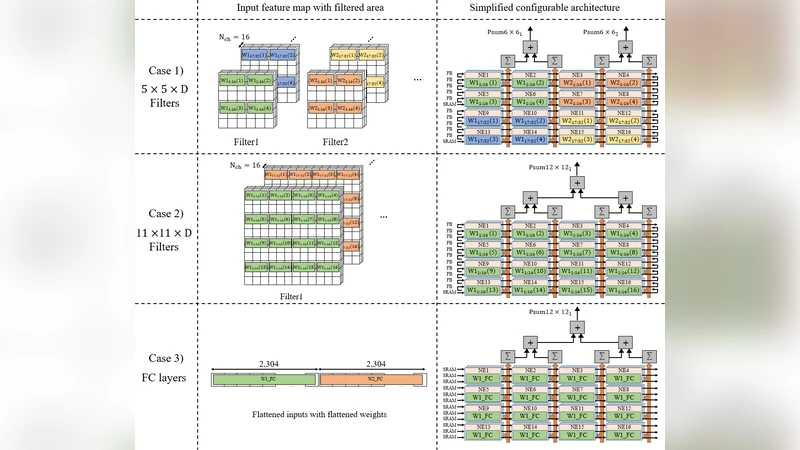
구성 가능한 뉴럴 프로세싱 엘리먼트(NPE)는 행렬‑벡터 연산을 위한 파이프라인 구조를 갖추고 있다. 입력 활성화는 로우‑레벨 시프트 레지스터에 저장되고, 가중치는 사전 압축된 형태(예: 비트‑플레인 혹은 런‑레ング스)로 메모리에서 스트리밍된다. 각 연산 유닛은 가중치 비트를 순차적으로 읽어 활성화와 논리 OR/AND 연산을 수행하고, 결과를 누산기(accumulator)로 전달한다. 이 과정에서 가중치가 0인 비트는 연산을 스킵하도록 설계돼 불필요한 전력 소모를 최소화한다.
또한, TMA는 스케일러블 정수 가중치 표현을 지원한다. 가중치 비트 폭을 4‑bit, 6‑bit 등으로 조정할 수 있어 메모리 대역폭과 연산량을 동적으로 최적화한다. 이는 모델 압축 기법(예: 양자화, 프루닝)과 자연스럽게 결합돼, 동일한 하드웨어 플랫폼에서 다양한 정확도‑효율 트레이드오프를 구현한다.
실리콘 구현 결과는 65 nm CMOS 공정에서 1.0 V 전압, 250 MHz 클럭으로 동작했으며, 전체 면적은 약 2 mm², 정전류 소모는 0.9 W 수준이다. AlexNet을 ImageNet 데이터셋에 적용했을 때, 2.3 TMAC·W의 에너지 효율을 기록했으며, 이는 기존 최고 수준(수백 GMAC·W) 대비 5배 이상 향상된 수치다. 또한, 동일 전력 조건에서 처리량(throughput)은 1.8×, 지연시간(latency)은 0.55×으로 개선되었다.
하지만 몇 가지 한계점도 존재한다. 첫째, 현재 설계는 8‑bit 활성화와 1‑byte 이하 가중치에 최적화돼 있어, 4‑bit 이하 초저비트 양자화 모델에는 추가적인 회로 최적화가 필요하다. 둘째, 멀티플라이어를 완전히 배제함으로써 가중치가 부호 없는 정수일 경우에만 효율이 극대화되며, 부호 있는 가중치나 비선형 연산(예: 배치 정규화, 활성화 함수)에서는 별도의 보조 회로가 필요해 전체 효율을 약간 저하시킬 수 있다. 셋째, 메모리 대역폭 요구가 높은 경우, 가중치 스트리밍이 병목이 될 가능성이 있어 고대역폭 DRAM 인터페이스와의 연계 설계가 요구된다.
종합적으로, TMA는 멀티플라이어‑리스 설계가 추론 가속기의 에너지 효율을 획기적으로 끌어올릴 수 있음을 실증했으며, 향후 초저전력 엣지 디바이스와 데이터센터 가속기 모두에 적용 가능한 설계 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기