코퓰라 기반 의존구조 추정과 최대 신장 코퓰라
** 본 논문은 코퓰라와 코퓰라 엔트로피(Copula Entropy, CE)를 이용해 변수 간 의존구조를 비모수적으로 추정하는 프레임워크를 제안한다. 그래프 모델을 코퓰라의 특수 경우로 보고, CE를 가중치로 하는 최대 신장 트리를 Chow‑Liu 알고리즘으로 구성함으로써 마진 분포와 무관한 의존관계를 효과적으로 복원한다. 시뮬레이션 및 UCI의 Abalone, Boston Housing 데이터셋 실험을 통해 제안 방법의 정확성과 로버스트성…
저자: Jian Ma, Zengqi Sun
**
본 논문은 머신러닝 분야에서 변수 간 의존구조를 정확히 파악하는 것이 다양한 과학·공학 문제 해결에 핵심적이라는 점을 출발점으로 삼는다. 기존의 그래프 모델(베이지안 네트워크 등)은 마진 분포를 특정 파라메트릭 형태로 가정하고, 조건부 독립성을 전제로 구조를 학습한다. 이러한 접근법은 실제 데이터가 비정규, 이질적, 혹은 마진에 대한 사전 지식이 부족한 경우에 모델 오차를 초래한다. 이를 극복하고자 저자들은 코퓰라 이론을 도입한다.
코퓰라란 다변량 확률분포를 각 변수의 마진 분포와 의존구조를 기술하는 함수로 분해하는 수학적 도구이며, Sklar 정리(정리 1)를 통해 그 존재와 유일성을 보장한다. 코퓰라 밀도(c)는 마진을 제거한 순수 의존 정보를 담고 있으며, 이를 로그 변환 후 적분한 것이 코퓰라 엔트로피(CE, 정의 3)이다. CE는 비음수이며, 독립일 때 0이 되는 특성을 갖는다. Ma와 Sun(2019)은 CE와 상호정보량(MI)이 부호만 반대인 동등 관계임을 정리 4로 증명했으며, 이는 CE가 정보이론적 의존 측정치로서 충분히 활용될 수 있음을 의미한다.
논문은 CE를 이용한 비모수적 의존 측정 절차를 두 단계로 제시한다. 첫 번째 단계에서는 경험 코퓰라 밀도(ECD)를 순위 기반으로 추정한다. 구체적으로 각 변수에 대해 경험 누적분포함수(F_i)를 계산하고, 이를 통해 u_i = F_i(x_i) 형태의 변환 데이터를 얻는다. 두 번째 단계에서는 k‑최근접 이웃(k‑NN) 엔트로피 추정법을 적용해 CE 값을 구한다. 이 과정은 마진 분포에 대한 가정이 전혀 필요 없으며, 데이터가 연속형이든 이산형이든 동일하게 적용 가능하다.
이러한 CE 기반 의존 행렬을 바탕으로 구조 학습을 수행한다. 저자들은 CE를 그래프의 간선 가중치로 사용하고, 최대 신장 트리(MST)를 찾는 Chow‑Liu 알고리즘을 적용한다. 여기서 얻어지는 트리는 ‘최대 신장 코퓰라(MSC)’라 명명되며, 각 간선은 두 변수 사이의 순수 의존성을 나타낸다. MSC는 ‘프로덕트 코퓰라(product copula)’와 동등함을 정리 3을 통해 증명한다. 즉, 기존 그래프 모델은 MSC의 특수 경우이며, MSC는 보다 일반적인 의존구조를 포착한다는 점에서 이론적 통합성을 제공한다.
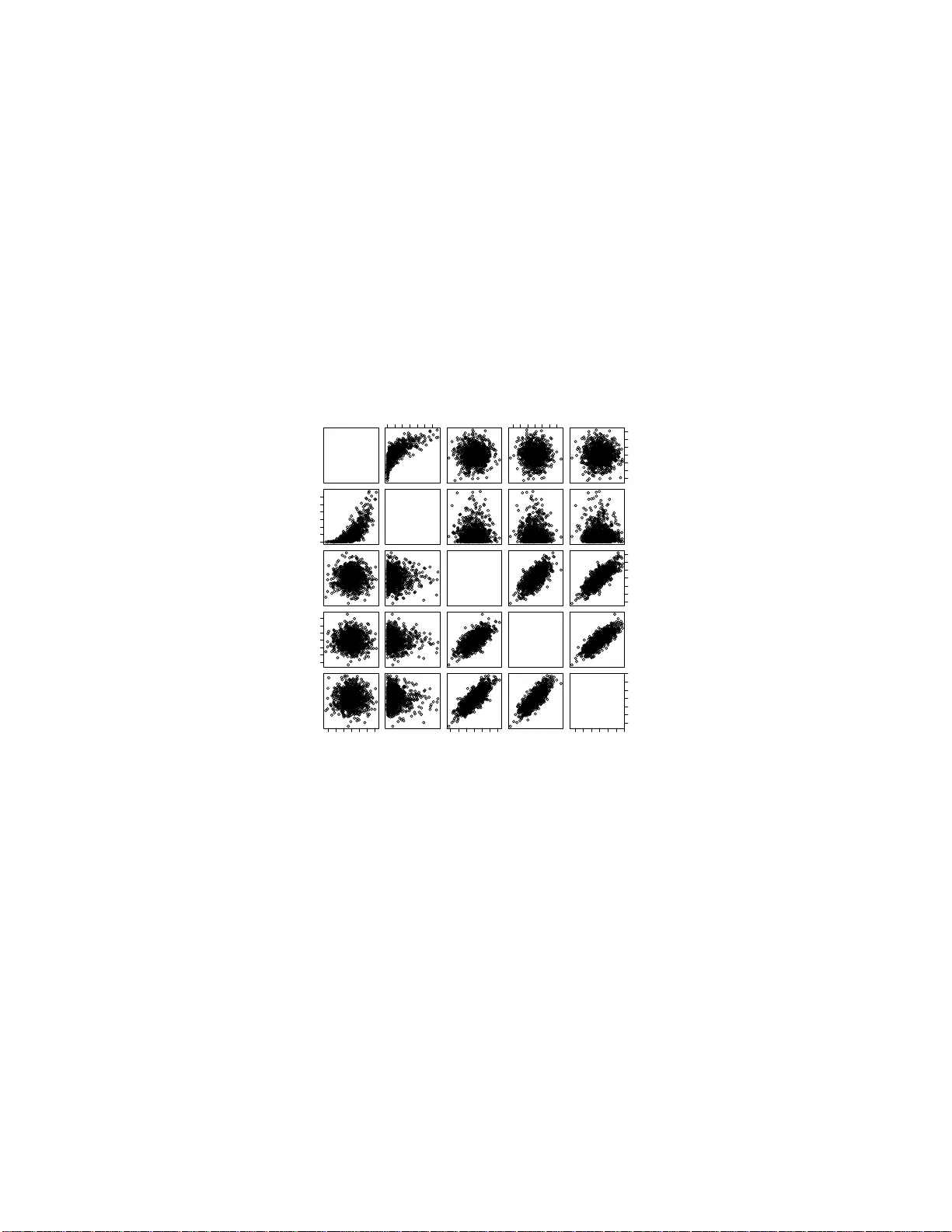
실험은 세 부분으로 구성된다. 첫 번째는 시뮬레이션 데이터로, 5차원 변수 중 3개는 표준 정규분포, 나머지 2개는 각각 정규·지수 마진을 갖는 가우시안 코퓰라를 사용해 생성하였다. 제안 알고리즘을 적용한 결과, 두 변수 그룹이 명확히 구분된 트리가 복원되었으며, 이는 알고리즘이 비정규 마진과 복합 코퓰라 구조를 정확히 인식함을 시각적으로 보여준다. 두 번째 실험은 UCI의 Abalone 데이터(9개 연속형·이산형 특성, 4177 샘플)이다. MSC를 추출한 결과, ‘Sex’와 ‘Rings’가 다른 7개 물리적 특성과 약하게 연결되고, 나머지 특성들 간에 강한 상호연관성이 존재함을 확인했다. 이는 어릴 때부터 성장에 따라 물리적 특성이 동시에 변하고, 성별·연령은 상대적으로 독립적인 정보를 제공한다는 도메인 지식과 일치한다. 세 번째 실험은 Boston Housing 데이터(14개 특성, 506 샘플)이다. MSC는 ‘범죄율‑산업비율‑방사선‑세금‑비율‑질소‑거리’와 ‘주택가격‑하위계층 비율’ 두 개의 강한 서브그래프를 형성했으며, 이는 주택가격 예측에 모든 변수를 일관되게 활용하는 기존 회귀 접근법이 과도한 가정을 포함할 수 있음을 시사한다.
논문의 장점은 다음과 같다. (1) 마진 분포와 무관한 비모수적 의존 측정으로, 다양한 데이터 타입에 적용 가능하다. (2) CE와 MI의 동등성을 이용해 정보이론적 해석이 가능하며, 기존 상호정보량 기반 방법과 이론적 연계성을 제공한다. (3) 최대 신장 트리 알고리즘을 활용해 계산 복잡도가 O(N²) 수준으로 실용적이며, 대규모 데이터에도 확장 가능하다. (4) 시뮬레이션 및 실제 데이터 실험을 통해 제안 방법이 기존 그래프 모델보다 더 풍부한 의존 정보를 포착함을 실증했다.
반면 한계점도 명확하다. (1) 트리 구조에 제한되므로, 사이클이나 다중 연결을 포함하는 복잡한 네트워크를 모델링하지 못한다. (2) 기존 Chow‑Liu 기반 상호정보량 추정과의 정량적 비교가 부재해, 실제 성능 향상을 수치적으로 입증하지 못한다. (3) k‑NN 엔트로피 추정 시 이웃 수(k) 선택에 대한 민감도 분석이 없으며, 이는 결과 재현성에 영향을 줄 수 있다. (4) 샘플 복잡도와 수렴 속도에 대한 이론적 분석이 부족해, 고차원·소규모 데이터에서의 안정성을 보장하기 어렵다. (5) 논문 전반에 걸쳐 서식·표기 오류가 다수 존재해 가독성이 떨어진다.
종합하면, 본 연구는 코퓰라와 코퓰라 엔트로피를 활용해 마진 독립적인 의존구조 학습 프레임워크를 제시함으로써, 기존 그래프 모델의 한계를 극복하고자 하는 중요한 시도이다. 향후 연구에서는 트리 구조를 넘어 복합 그래프를 다루는 확장, CE 기반 구조 학습의 통계적 일관성 및 샘플 효율성 분석, 그리고 다양한 도메인(생물학, 금융, 환경 등)에서의 실증적 검증이 진행된다면, 코퓰라 기반 구조 학습이 실용적인 데이터 과학 도구로 자리매김할 가능성이 크다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기