비음수 행렬 분해 기반 그래프 풀링 기법
본 논문은 그래프 합성곱 신경망(GCN)에서 노드 풀링을 수행하기 위해 비음수 행렬 분해(NMF)를 활용한다. 인접 행렬과 학습된 노드 임베딩의 유사도 행렬을 NMF로 분해해 얻은 소프트 할당 행렬을 이용해 그래프를 단계적으로 코어싱하고, 각 단계에서 풀링된 그래프와 임베딩을 다시 GCN에 입력한다. ENZYMES, NCI1, PROTEINS, D&D, COLLAB 등 5개 벤치마크에서 기존 DiffPool 대비 경쟁력 있는 성능 향상을 보이며…
저자: Davide Bacciu, Luigi Di Sotto
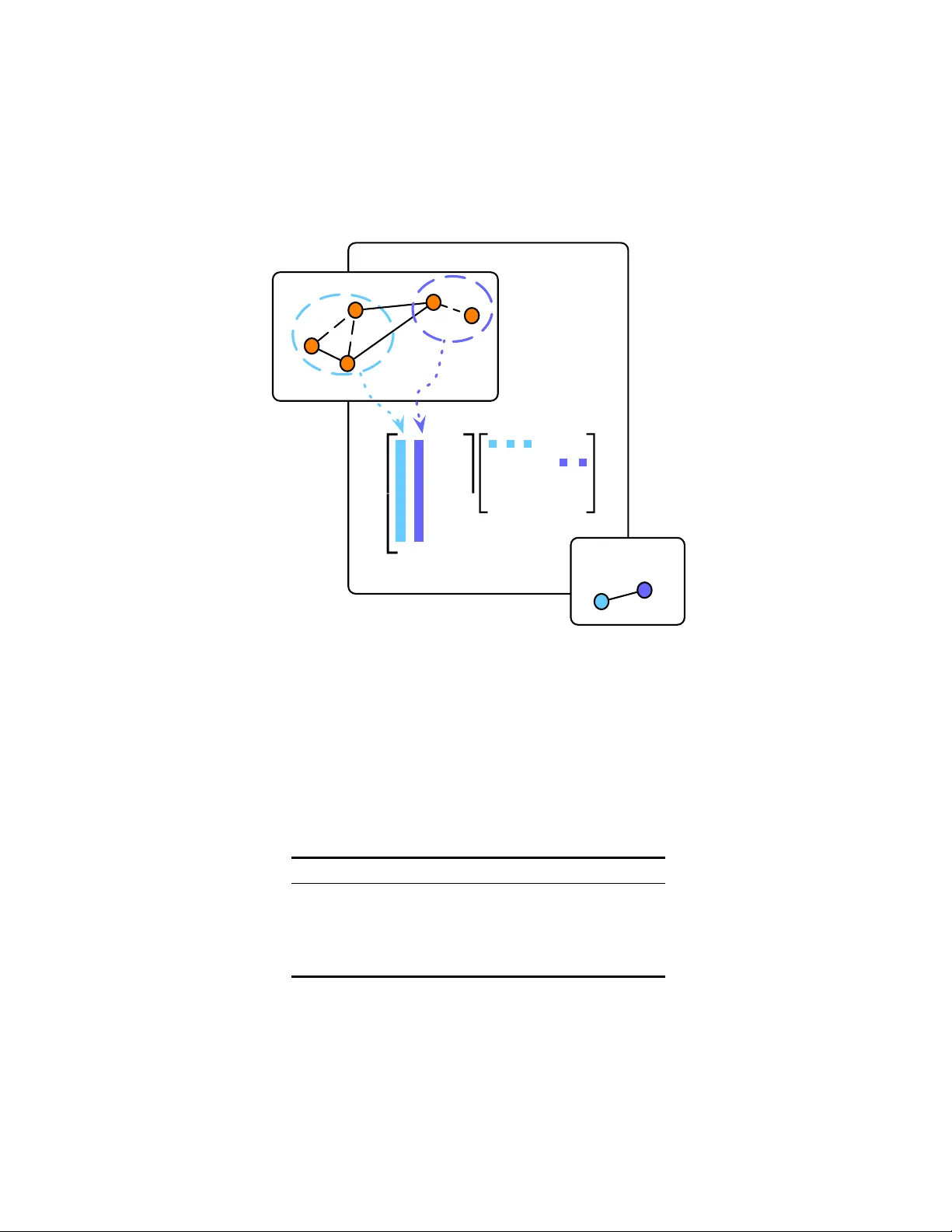
본 논문은 그래프 구조 데이터를 처리하는 그래프 합성곱 신경망(GCN)에서 효과적인 노드 풀링 메커니즘을 제안한다. 기존 GCN는 노드 수가 가변적인 비유클리드 도메인에서 필터 크기와 가중치 공유가 어려워, 다중 스케일 표현을 얻기 위한 체계적인 풀링 연산이 부족했다. 이를 보완하기 위해 저자들은 비음수 행렬 분해(Non‑Negative Matrix Factorization, NMF)를 기반으로 한 풀링 연산인 NMFPool을 설계하였다.
**배경 및 동기**
그래프는 유클리드 이미지와 달리 정규 격자 구조가 없으며, 노드 간 연결성(인접 행렬)과 노드 특성(임베딩) 모두가 학습 과정에서 동적으로 변한다. 기존의 풀링 방법은 max, sum, mean 등 대칭 함수에 의존하거나, DiffPool처럼 복잡한 파라미터화된 소프트 할당 행렬을 학습한다. 그러나 전자는 그래프 구조 정보를 충분히 활용하지 못하고, 후자는 파라미터 수가 급증하고 학습이 불안정해지는 문제가 있다.
**NMFPool 설계**
NMFPool은 두 단계로 구성된다. 1) 현재 레이어의 정규화된 인접 행렬 A^(i)와 노드 임베딩 Z^(i)를 이용해 비음수 행렬 분해를 수행한다. 구체적으로 A^(i) ≈ W^(i) H^(i) (식 10) 를 최소화하며, 여기서 H^(i) ∈ ℝ^{k_i × n_i}_+ 은 노드‑커뮤니티 소프트 할당 행렬이다. k_i는 풀링 후 얻고자 하는 커뮤니티 수이며, 하이퍼파라미터로 설정한다. 2) 얻어진 H^(i) 를 이용해 그래프와 임베딩을 차원 축소한다. Z^(i+1) = H^(i)ᵀ Z^(i) (식 11), A^(i+1) = H^(i)ᵀ A^(i) H^(i) (식 12) 로 정의된다. 이 연산은 그래프 토폴로지와 노드 특성을 동시에 압축하며, H^(i)ᵀ가 선형 변환이므로 역전파가 가능하다.
비대칭 NMF를 채택함으로써 H^(i) 가 확률적 제약을 갖지 않아, 하나의 노드가 여러 커뮤니티에 부분적으로 기여할 수 있다. 이는 그래프가 실제로 겹치는 커뮤니티 구조를 가질 때 자연스러운 표현이다. 또한, 풀링 연산이 n_i(노드 수)에 독립적이므로, 다양한 크기의 그래프에 동일한 모델 구조를 적용할 수 있다.
**학습 흐름**
전체 모델은 (GCN → NMFPool) 블록을 여러 번 쌓아 구성한다. 각 GCN 레이어는 Chebyshev 다항식 기반의 스펙트럴 근사 필터를 사용해 (식 6) 형태로 구현된다. 풀링 레이어가 삽입된 뒤에는 차원 축소된 그래프와 임베딩이 다음 GCN 레이어에 입력된다. 최종적으로 그래프 전체를 대표하는 벡터를 얻어, 분류 혹은 회귀 헤드에 연결한다.
**실험 설정**
다섯 개 공개 벤치마크(ENZYMES, NCI1, PROTEINS, D&D, COLLAB)를 사용해 성능을 평가하였다. Baseline은 풀링 없이 순수 GCN(식 6)만을 사용한 모델이며, 비교 대상은 차별화 가능한 풀링 기법인 DiffPool이다. 각 데이터셋에 대해 10‑fold 교차 검증을 수행하고, 평균 정확도와 표준편차를 보고하였다. 하이퍼파라미터 k_i는 각 데이터셋의 평균 노드 수에 비례하도록 설정했으며, NMF 최적화는 KL‑divergence 기반의 멀티플리케이티브 업데이트 규칙을 사용하였다.
**결과 및 분석**
NMFPool은 모든 데이터셋에서 DiffPool과 동등하거나 더 높은 정확도를 기록하였다. 특히, D&D와 COLLAB처럼 노드 수가 수천에 달하는 대규모 그래프에서는 풀링 비율을 0.5 이상으로 높였음에도 과적합이 억제되고, 파라미터 수가 크게 증가하지 않아 학습 효율이 향상되었다. Ablation study에서는 (1) H 행렬을 단순히 이진 마스크로 변환한 경우 성능이 급격히 떨어짐을 보여, 소프트 할당의 중요성을 입증하였다. 또한, NMF를 정확히 수행했을 때와 몇 번의 반복만 수행했을 때의 차이를 비교한 결과, 약 5번의 업데이트만으로도 대부분의 성능 이득을 확보할 수 있음을 확인하였다.
**한계 및 향후 연구**
NMF 최적화 단계가 매 풀링 레이어마다 수행되므로 계산 비용이 증가한다는 점이 주요 단점이다. 저자는 근사 NMF, 미리 학습된 커뮤니티 행렬, 혹은 GPU‑친화적인 행렬 분해 알고리즘을 도입해 속도를 개선할 여지를 남겨두었다. 또한, 현재는 비대칭 NMF만을 사용했으며, 대칭 NMF, 스펙트럴 클러스터링, 혹은 그래프 신호 처리 기반의 다른 행렬 분해 기법과의 비교가 필요하다. 마지막으로, 풀링 후 그래프의 연결성을 유지하기 위한 추가 정규화 기법이나, 풀링 단계에서의 정규화 손실을 최소화하는 손실 함수 설계도 향후 연구 과제로 제시된다.
**결론**
본 논문은 NMF를 그래프 풀링에 적용함으로써, 토폴로지와 노드 특성을 동시에 압축하는 효율적인 다중 해상도 학습 프레임워크를 제시한다. 실험 결과는 기존 DiffPool 대비 경쟁력 있는 성능을 보여주며, 특히 그래프 규모가 큰 경우에도 파라미터 효율성을 유지한다. 비음수 행렬 분해 기반의 풀링은 GCN에 새로운 설계 옵션을 제공하고, 향후 다양한 행렬 분해 기법과 결합된 그래프 신경망 연구에 중요한 토대를 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기