다중 스케일 시간‑주파수 어텐션으로 음향 이벤트 탐지 향상
본 논문은 시간축과 주파수축을 동시에 고려한 다중 스케일 어텐션 모듈(MTFA)을 제안한다. MTFA는 멜‑스펙트로그램을 여러 해상도로 처리해 2차원 어텐션 마스크를 생성하고, 이를 잔차 방식으로 특징 맵에 결합한다. DCASE 2017 Task 2 실험에서 기존 단일‑스케일 모델들을 능가하며, 특히 평가 데이터셋에서 평균 오류율 0.09를 달성하였다.
저자: Jingyang Zhang, Wenhao Ding, Jintao Kang
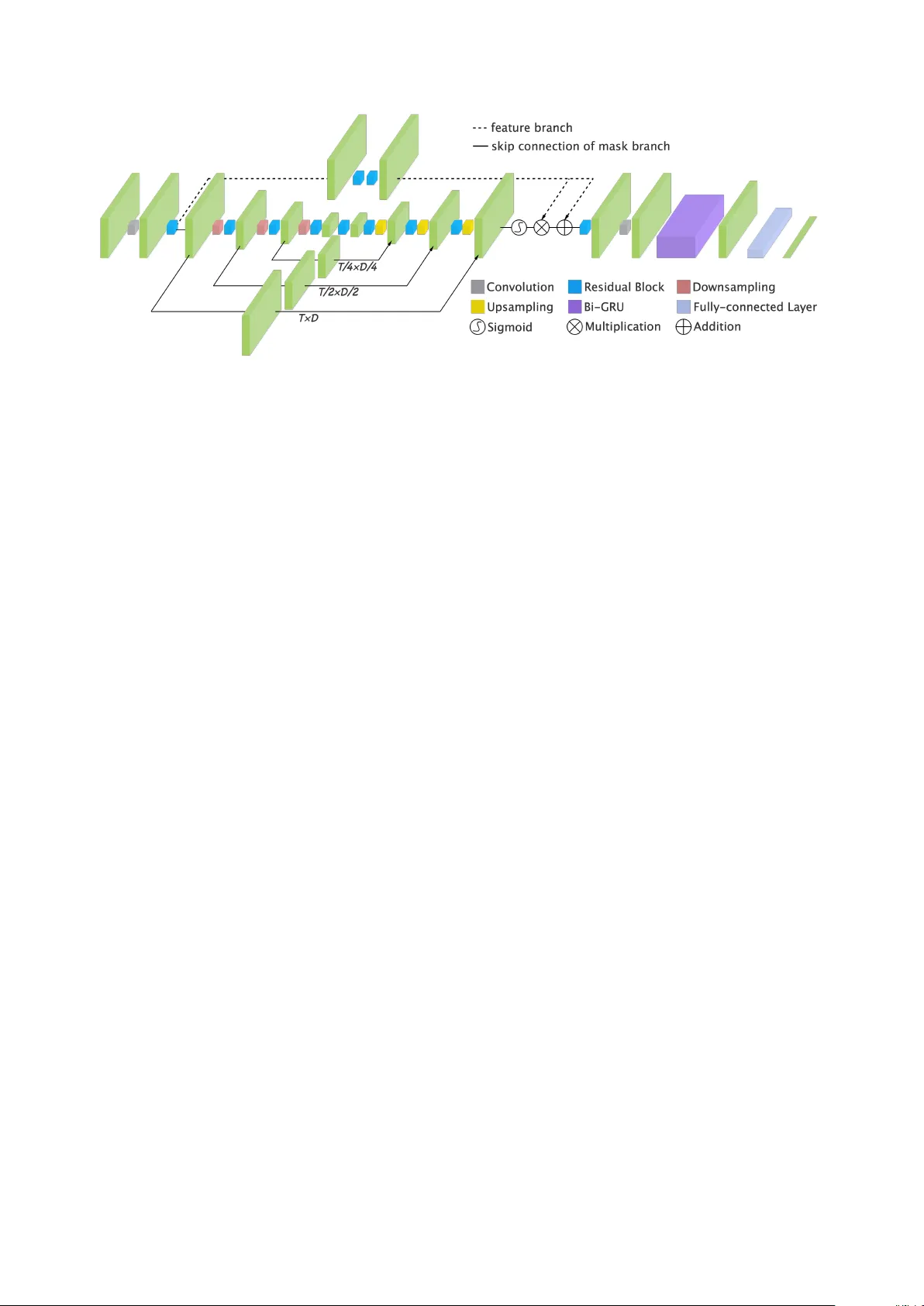
본 논문은 음향 이벤트 탐지(AED)에서 기존의 시간축 중심 어텐션이 갖는 한계를 극복하고자, 시간‑주파수 양축을 동시에 고려하는 **다중 스케일 시간‑주파수 어텐션(Multi‑Scale Time‑Frequency Attention, MTFA)** 모듈을 제안한다. AED는 자동차의 사이렌 감지, 가정용 로봇, 도로 감시 시스템 등 시각 정보가 부족하거나 없는 환경에서 중요한 역할을 한다. DCASE 2017 Task 2는 베이비크리, 유리 파손, 총성이라는 세 종류의 희귀 이벤트를 30 초 오디오 클립에서 찾아내는 과제로, 기존 연구들은 주로 프레임‑레벨 예측에 기반한 CNN‑RNN 구조를 사용했으며, 일부는 1D‑CRNN과 같은 앙상블 기법을 적용했다. 그러나 대부분의 어텐션 기법은 시간축에만 집중했으며, 이벤트마다 주파수 특성이 크게 다름에도 불구하고 이를 반영하지 못했다.
MTFA는 이러한 문제를 해결하기 위해 두 개의 병렬 흐름을 설계한다. **Feature branch**는 ResNet 구조(3×3 컨볼루션 두 개의 residual block)로 입력 멜‑스펙트로그램(1501 × 128)을 고차원 특징 맵(F, C × T × D)으로 변환한다. **Mask branch**는 Hourglass 네트워크를 차용해 다중 해상도에서 정보를 추출한다. 구체적으로, 2×2 맥스‑풀링을 세 번 적용해 (T × D) → (T/2 × D/2) → (T/4 × D/4) → (T/8 × D/8) 네 단계의 스케일을 만든 뒤, 역상향(NN interpolation)과 스킵 연결을 통해 원래 해상도로 복원한다. 각 스케일에서 1×1 컨볼루션과 시그모이드 함수를 거쳐 0‒1 범위의 어텐션 마스크 M을 얻는다.
MTFA는 **(1 + M) ⊙ F** 형태로 마스크와 특징을 결합한다. 이 잔차 연결은 마스크가 0에 가까울 때도 원본 특징을 유지하게 하여, 학습 초기에 어텐션이 과도하게 억제되는 현상을 방지한다. 결과적으로 모델은 시간축에서는 이벤트 발생 시점을, 주파수축에서는 해당 이벤트의 특이 주파수 대역을 동시에 강조한다. 예를 들어, 총성은 초기 고주파 임펄스와 이후 저주파 에너지로 구성되며, 유리 파손은 넓은 주파수 대역에 걸쳐 짧은 충격음을 포함한다. 이러한 서로 다른 스펙트럼 특성을 MTFA는 다중 해상도 정보를 융합함으로써 효과적으로 포착한다.
어텐션 처리 후, 2층 양방향 GRU(bi‑GRU, 각 64 유닛)를 적용해 프레임 간 시간적 의존성을 학습한다. 최종 Fully‑Connected 레이어와 시그모이드 활성화 함수를 통해 각 프레임에 대한 존재 확률을 출력하고, 클래스별 임계값(베이비크리 0.4, 유리 파손 0.2, 총성 0.4)과 540 ms median filter를 적용해 최종 이벤트 온셋을 결정한다.
실험 설정은 다음과 같다. 입력은 40 ms 윈도우, 20 ms 시프트로 추출한 128 차원의 로그 필터뱅크이며, 30 초 클립당 1501 프레임을 만든다. 학습 시에는 256 프레임 길이의 청크를 128 프레임씩 겹쳐서 사용해 배치 효율을 높였으며, 검증 손실이 10 epoch 연속 감소하지 않으면 학습을 종료한다. 최적화는 Adam(learning rate 0.001)이며, 베이비크리·유리 파손에 dropout 0.3, 총성에 dropout 0.4을 적용해 과적합을 방지한다.
성능 평가는 DCASE 2017 Task 2에서 사용되는 **event‑based error rate(ER)**와 **F1‑score**를 기준으로 한다. Ablation 실험에서 (1) 마스크 브랜치를 제거한 ResRNN, (2) Hourglass 대신 ResNet을 사용한 ResAttRNN과 비교하였다. ResRNN은 개발 데이터셋에서는 비슷한 성능을 보였지만 평가 데이터셋에서는 크게 성능이 떨어져 어텐션의 일반화 효과가 입증되었다. ResAttRNN은 단일 스케일 어텐션을 제공했지만, MTFA는 다중 스케일 어텐션을 통해 개발·평가 모두에서 최고 성능을 기록했다.
표 1에 제시된 결과에 따르면, 제안 모델은 개발 데이터셋에서 평균 ER 0.07, F1 96.1%를 달성했고, 평가 데이터셋에서는 평균 ER 0.09, F1 95.5%를 기록했다. 이는 기존 단일‑모델인 CRNN, R‑CRNN, Multi‑Scale RNN, CRNN+Attention 등을 능가한다. 특히 평가 데이터셋에서 기존 최고 기록(ER 0.13)을 크게 앞서며, 앙상블 없이도 경쟁력 있는 성능을 보여준다.
시각화 실험에서는 유리 파손 이벤트를 예시로 MTFA의 마스크가 네 개의 스케일에서 어떻게 변하는지 확인했다. 고해상도 마스크는 세부 주파수 패턴을 강조하고, 저해상도 마스크는 이벤트 위치만을 강조해 잡음에 강인한 특성을 보여준다. 이러한 시각적 증거는 다중 스케일 어텐션이 시간·주파수 변동성을 효과적으로 완화한다는 것을 뒷받침한다.
결론적으로, 본 논문은 **시간‑주파수 2차원 어텐션**과 **다중 스케일 정보 융합**을 결합한 MTFA 모듈을 통해 AED에서 기존 CNN‑RNN 기반 방법들의 한계를 극복하고, 다양한 이벤트의 스펙트럼·시간적 변동성을 포괄적으로 학습한다는 점을 입증하였다. 향후 연구에서는 MTFA를 다른 음성 인식·음악 정보 검색 작업에 적용하거나, 더 깊은 Hourglass 구조와 효율적인 경량화 기법을 탐색함으로써 실시간 시스템에 적용 가능한 경량 모델을 개발할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기