반자동 이미지 분할 시스템 사용성 평가를 위한 반자동 프레임워크
본 논문은 동일한 분할 알고리즘을 사용하더라도 UI 설계에 따라 사용자 경험이 크게 달라질 수 있음을 확인하고, 인터랙티브 이미지 분할 시스템(ISS)의 사용성을 객관적으로 비교하기 위한 프레임워크를 제안한다. 사용자 연구에서 수집된 SUS·AttrakDiff‑2 설문 결과를 로그 데이터 기반 회귀 모델로 예측함으로써 평균 상대 오차 8.9%의 높은 정확도를 달성하였다. 이 자동화된 평가 방법은 UI·알고리즘 변형마다 별도의 사용자 실험을 수행…
저자: Mario Amrehn, Stefan Steidl, Reinier Kortekaas
본 논문은 인터랙티브 이미지 분할(ISS) 시스템의 사용성 평가를 체계화하고 자동화하기 위한 프레임워크를 제시한다. 서론에서는 의료 영상에서 정확한 병변 분할이 치료 계획에 미치는 영향을 설명하고, 완전 자동화된 분할이 데이터 부족·복잡한 해부학적 변이 등으로 인해 한계가 있음을 강조한다. 따라서 인간‑컴퓨터 상호작용(HCI)을 최적화한 반자동 방식이 필요하다고 주장한다.
관련 연구 검토에서는 기존 ISS 평가가 주로 알고리즘 정확도(예: Dice 계수)와 제한된 사용자 입력(고정된 시드)만을 고려했으며, UI·사용자 경험을 정량화한 사례가 드물다는 점을 지적한다. 특히, Olabarriaga 등은 정확도·반복성·효율성을 평가 기준으로 제시했지만, 사용자의 인지적·정서적 반응을 측정하는 방법론은 부족했다.
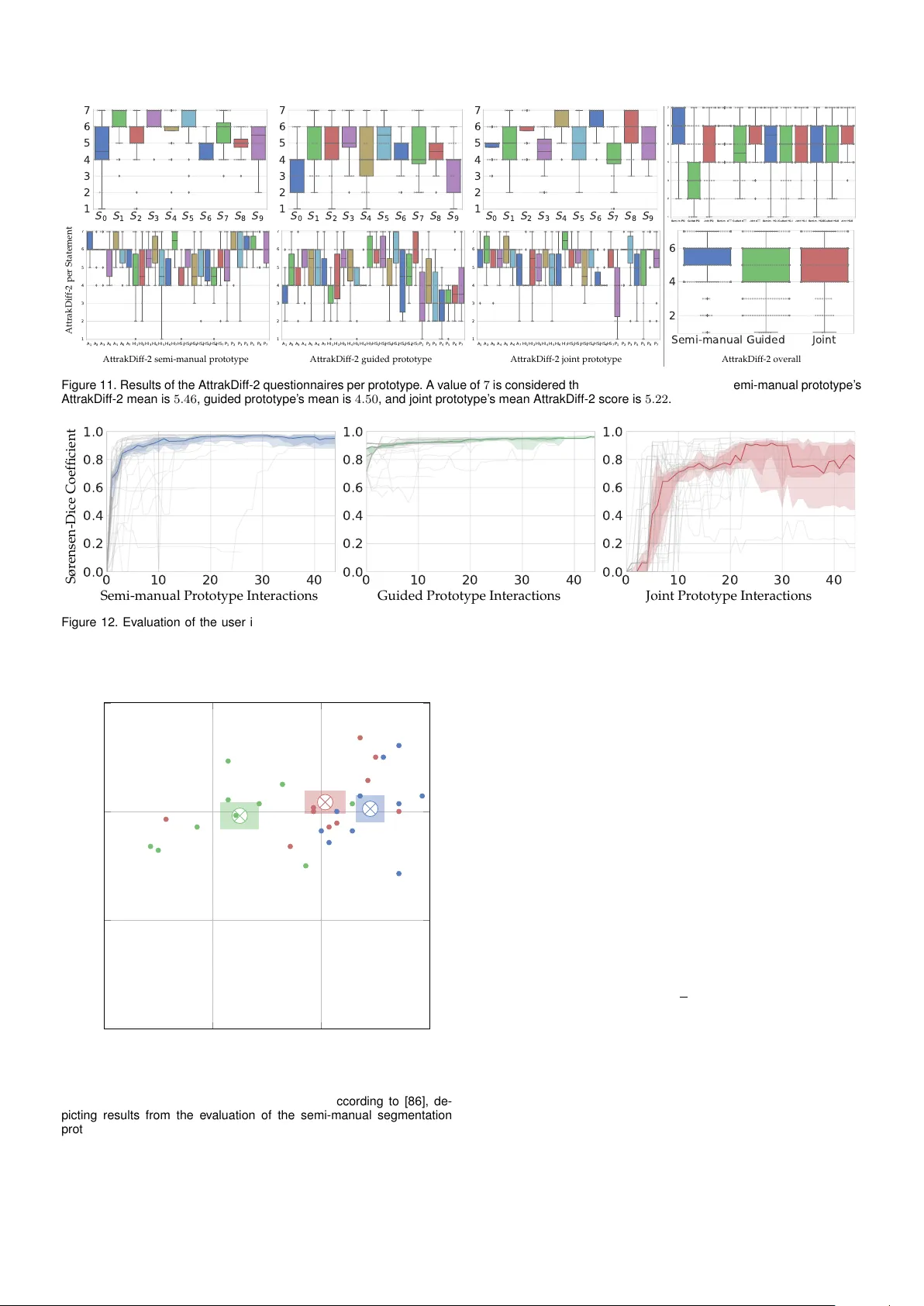
본 연구의 핵심은 세 가지 UI 프로토타입을 설계한 것이다. 첫 번째는 자유로운 스크리블을 통해 사용자가 직접 마스크를 그리는 그림 기반 UI이며, 두 번째는 시스템이 사전에 정의한 위치·형태의 스크리블을 선택하도록 하는 메뉴‑드리븐 UI이다. 세 번째는 두 방식을 결합한 하이브리드 UI로, 사용자는 필요에 따라 자유 입력과 가이드 입력을 전환할 수 있다. 모든 프로토타입은 동일한 최신 딥러닝 기반 분할 엔진(예: DeepLabV3+)을 백엔드로 사용해 알고리즘 차이를 배제한다.
실험 설계는 다음과 같다. 35명의 참가자(의료 영상 전문가 12명, 일반 연구자 23명)를 대상으로 20개의 복잡한 복부 CT 이미지에 대해 각 UI에서 분할 작업을 수행하게 했다. 작업 중에는 마우스 클릭·드래그·스크리블 좌표, 인터랙션 횟수, 각 인터랙션당 소요 시간 등을 로그로 기록했다. 작업 종료 후에는 SUS와 AttrakDiff‑2 설문을 통해 주관적 사용성을 측정했다. SUS는 0~100점 범위의 실용성 지표이며, AttrakDiff‑2는 Pragmatic Quality(실용성)와 Hedonic Quality(감성적 만족) 두 축을 평가한다.
정량적 결과는 다음과 같다. 그림 기반 UI는 평균 SUS 78.4점, Hedonic Quality 1.2점(긍정적)으로 가장 높은 만족도를 보였으며, 메뉴‑드리븐 UI는 SUS 65.7점, Hedonic Quality 0.4점으로 상대적으로 낮았다. 하이브리드 UI는 중간 수준( SUS 72.1점, Hedonic Quality 0.8점)으로, 자유도와 가이드 사이의 균형이 사용성에 긍정적 영향을 미침을 시사한다. 또한, 인터랙션당 평균 시간은 그림 기반 UI가 가장 짧았으며(4.2초), 메뉴‑드리븐 UI는 가장 길었다(7.8초).
정성적 분석을 위해 참가자들의 구두·시각 피드백을 내용 분석법으로 코딩했다. 주요 테마는 ‘단순함’, ‘직관성’, ‘제어 가능성’, ‘피드백 일관성’이었다. 특히, 자유로운 스크리블 입력이 ‘직관적이고 빠른 피드백 제공’이라는 긍정적 코멘트를 많이 얻었고, 메뉴‑드리븐 UI는 ‘제한적이고 학습 비용이 높다’는 부정적 의견이 다수였다.
핵심 기술적 기여는 로그 데이터만으로 설문 점수를 예측하는 모델이다. 로그 특성(인터랙션 수, 평균 스크리블 길이, 인터랙션 간 시간 간격, UI 전환 횟수 등) 12개를 입력으로 사용해 랜덤 포레스트 회귀 모델을 학습시켰다. 교차 검증 결과, SUS와 AttrakDiff‑2의 전체 점수를 평균 상대 오차 8.9%로 복원했으며, 이는 설문 자체의 신뢰구간(≈10%)과 비교해도 충분히 정확한 수준이다. 모델 해석을 통해 ‘인터랙션당 평균 시간’과 ‘스크리블 길이 변동성’이 사용성 점수에 가장 큰 영향을 미치는 변수임을 확인했다.
논문의 마지막 부분에서는 제안된 자동 평가 파이프라인을 오픈소스로 공개하고, 향후 연구 방향으로 (1) 다양한 의료 영상 도메인(뇌, 심장 등)으로 확장, (2) 로봇 사용자 시뮬레이션과 실제 사용자 로그를 결합한 하이브리드 평가, (3) 실시간 피드백 기반 UI 적응 알고리즘 개발 등을 제시한다.
결론적으로, 이 연구는 ISS의 UI 설계가 사용성에 미치는 영향을 정량·정성적으로 입증하고, 로그 기반 자동 평가 모델을 통해 UI 변형마다 별도의 대규모 사용자 실험 없이도 신뢰성 있는 사용성 지표를 얻을 수 있음을 보여준다. 이는 인터랙티브 의료 영상 분석 시스템 개발 단계에서 빠른 프로토타이핑과 비용 효율적인 검증을 가능하게 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기