재귀적 스피치 분리를 통한 화자 수 무관 단일 모델
본 논문은 화자 수가 사전에 알려지지 않은 경우에도 단일 신경망 모델 하나로 다중 화자 음성 분리를 수행할 수 있는 재귀적 구조와 One‑and‑Rest PIT(OR‑PIT) 학습 방식을 제안한다. 모델은 매 반복마다 한 화자를 추출하고 잔여 신호를 다음 단계에 입력한다. 또한 잔여 신호가 음성인지 여부를 판단하는 이진 분류기를 이용해 재귀 종료 시점을 자동으로 결정한다. WSJ0‑2mix, WSJ0‑3mix 및 새롭게 만든 WSJ0‑4mix에…
저자: Naoya Takahashi, Sudarsanam Parthasaarathy, Nabarun Goswami
**1. 연구 배경 및 동기**
다중 화자 환경에서 음성 인식·처리를 위해서는 겹쳐진 음성을 개별 화자별로 분리하는 기술이 필수적이다. 기존의 스펙트럼 클러스터링, CASA, NMF 등 전통적 방법은 제한된 성능을 보였으며, 최근 딥러닝 기반 DPCL, uPIT, DANet, Conv‑TasNet 등이 크게 향상시켰다. 그러나 이들 대부분은 화자 수 N 을 사전에 알고 있거나, 최대 M 개의 출력 채널을 고정해 두고 M 보다 적은 화자일 경우 ‘무음 채널’으로 처리한다. 이런 접근은 (i) 실제 상황에서 화자 수가 변동적이라는 점, (ii) M 보다 많은 화자를 처리해야 할 경우 적용이 불가능하다는 점에서 한계가 있다.
**2. 제안 방법 개요**
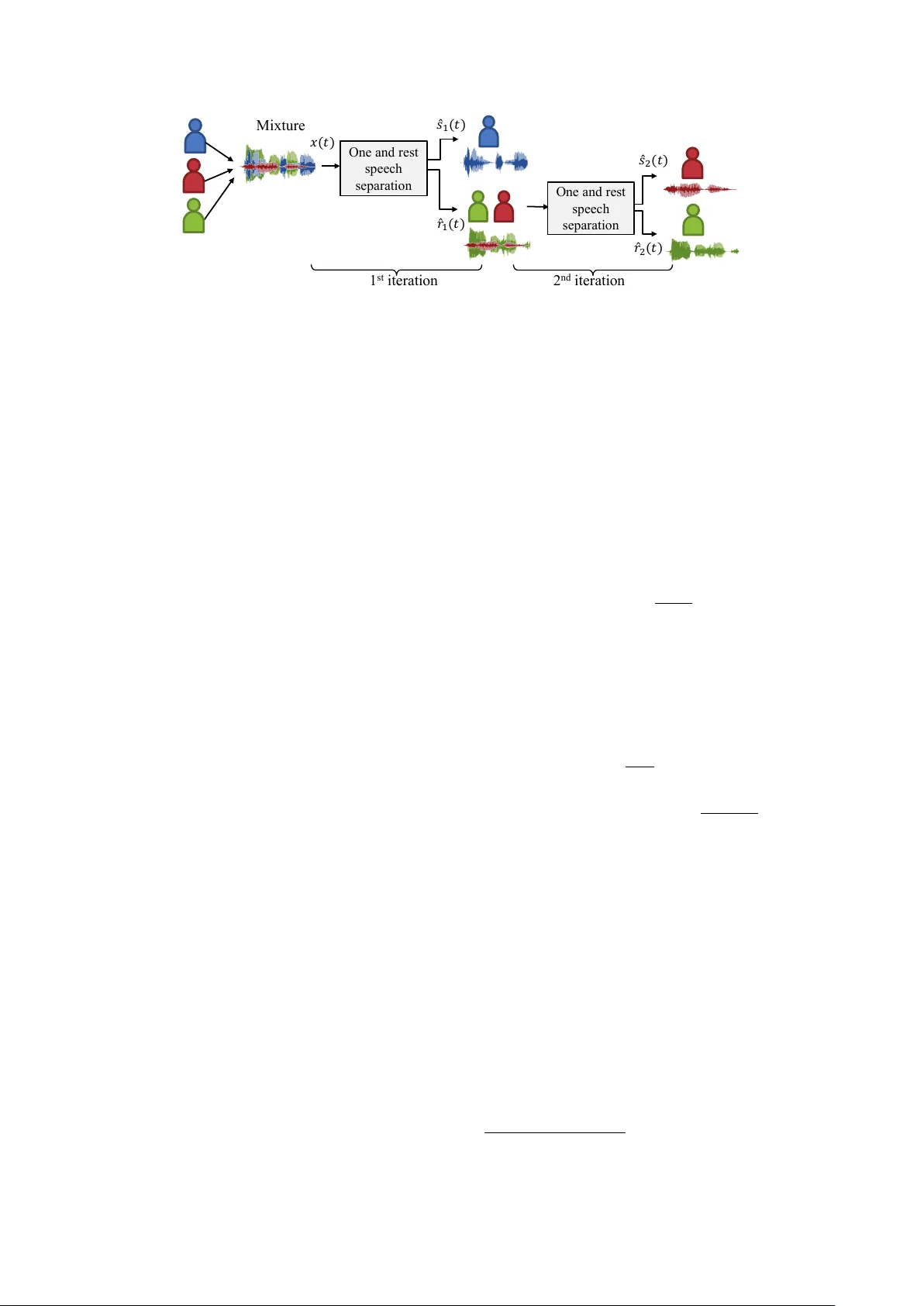
본 논문은 “한 화자를 한 번에 분리하고, 남은 신호를 재귀적으로 다시 분리한다”는 아이디어를 기반으로, 단일 모델 F 을 여러 번 호출하는 재귀적 스피치 분리 프레임워크를 제안한다. 핵심은 (a) One‑and‑Rest PIT(OR‑PIT)라는 새로운 학습 방식, (b) 잔여 신호가 더 이상 화자를 포함하지 않을 때를 자동으로 판단하는 이진 분류기이다.
**3. One‑and‑Rest PIT(OR‑PIT)**
입력 혼합에 N개의 화자가 존재할 때, 네트워크는 두 개의 출력 채널을 만든다: 하나는 단일 화자 \hat{s} , 다른 하나는 나머지 \hat{r}=∑_{i≠k}s_i . 어느 화자를 ‘첫 번째 채널’에 할당할지는 사전에 정해두지 않는다. 대신, N가지 가능한 ‘한 화자 + 나머지’ 조합을 모두 평가하고, SI‑SNR 기반 손실 l 이 가장 작은 조합을 선택한다. 손실 함수는
L = min_i
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기