산업 데이터 분석을 위한 일반화된 데이터 갱신 모델과 예측 알고리즘 적용
본 논문은 산업 현장의 시계열 데이터가 시간에 따라 변하는 문제를 해결하기 위해, 데이터 유사도와 손실 함수를 결합한 일반화된 데이터 갱신 모델을 제안한다. 제안 모델은 기존 예측 모델의 업데이트 시점을 자동으로 판단하고, 필요에 따라 부분 업데이트 혹은 완전 재학습을 수행한다. 두 가지 실제 예측 알고리즘(수율 예측 및 전이 학습 기반 고장 예측)에 적용한 실험 결과, 데이터 갱신 모델을 도입함으로써 예측 정확도가 최소 33 % 향상됨을 확인…
저자: Hongzhi Wang, Yijie Yang, Yang Song
본 논문은 산업 데이터 분석에서 시간에 따라 변하는 기계·공정 상태를 반영하지 못하는 고정된 예측 모델의 한계를 지적하고, 이를 해결하기 위한 **일반화된 데이터 갱신 모델**을 제안한다. 산업 현장은 센서가 고주파로 데이터를 수집하면서, 장비 노후화·마모·운영상 변동 등으로 데이터 분포가 지속적으로 변한다. 기존의 인공지능·통계 기반 예측 알고리즘은 특정 시점의 데이터에 최적화돼 시간이 흐를수록 예측 오차가 증가한다. 따라서 모델이 **데이터 흐름을 인식하고 자동으로 업데이트**되는 메커니즘이 필요하다.
### 1. 문제 정의 및 모델 개요
- 입력: 시간 구간 \(t\) 에서 수집된 다변량 시계열 \(X_t\) 와 기존 예측 모델 \(M\).
- 목표: 새 구간 \(t+n\) 의 데이터 \(X_{t+n}\) 에 대해 모델 \(M\) 가 여전히 유효한지 판단하고, 필요 시 **부분 업데이트**(새 데이터 추가 학습) 혹은 **전면 재학습**(모델 폐기 후 새 모델 구축)을 수행한다.
- 핵심 메트릭: **데이터 유사도(similarity)**와 **손실 변화율(loss change rate, LC)**.
### 2. 데이터 유사도 측정
- **이진 속성**: 동일 상태(0·0 또는 1·1) 쌍을 카운트해 \(S_1+S_2\) 비율로 정의.
- **연속형 속성**: 절대 피어슨 상관계수 \(|\rho|\)를 사용해 분산에 민감한 기존 상관계수의 단점을 보완.
- 차원별 유사도 \(sim(X_i^t, X_i^{t+n})\) 에 가중치 \(\delta_i\) (해당 속성 존재 여부) 를 곱해 전체 유사도 \(sim(X_t, X_{t+n})\) 를 산출.
- 유사도 값이 사전 설정 임계값 \(z\) 보다 낮으면 데이터 분포가 크게 변했음을 의미한다.
### 3. 손실 함수 및 변화율
- **회귀(수율 예측)**: RMSE 사용.
- **분류(고장 예측)**: 퍼셉추얼 로스(또는 0‑1, 로그, 힌지 등) 사용.
- 기존 모델 손실 \(L_m\) 과 새 데이터 적용 후 손실 \(L_n\) 을 비교해 변화율 \(LC = |L_n - L_m| / L_m\) 를 계산.
- 두 임계값 \(x\) (작은 변화)와 \(y\) (큰 변화)를 두어,
- \(LC < x\): 모델 유지 (업데이트 없음)
- \(x \le LC \le y\): **부분 업데이트** – 새 데이터를 추가 학습해 파라미터 조정
- \(LC > y\): **전면 재학습** – 기존 모델 폐기 후 새 모델 구축
### 4. 알고리즘 흐름
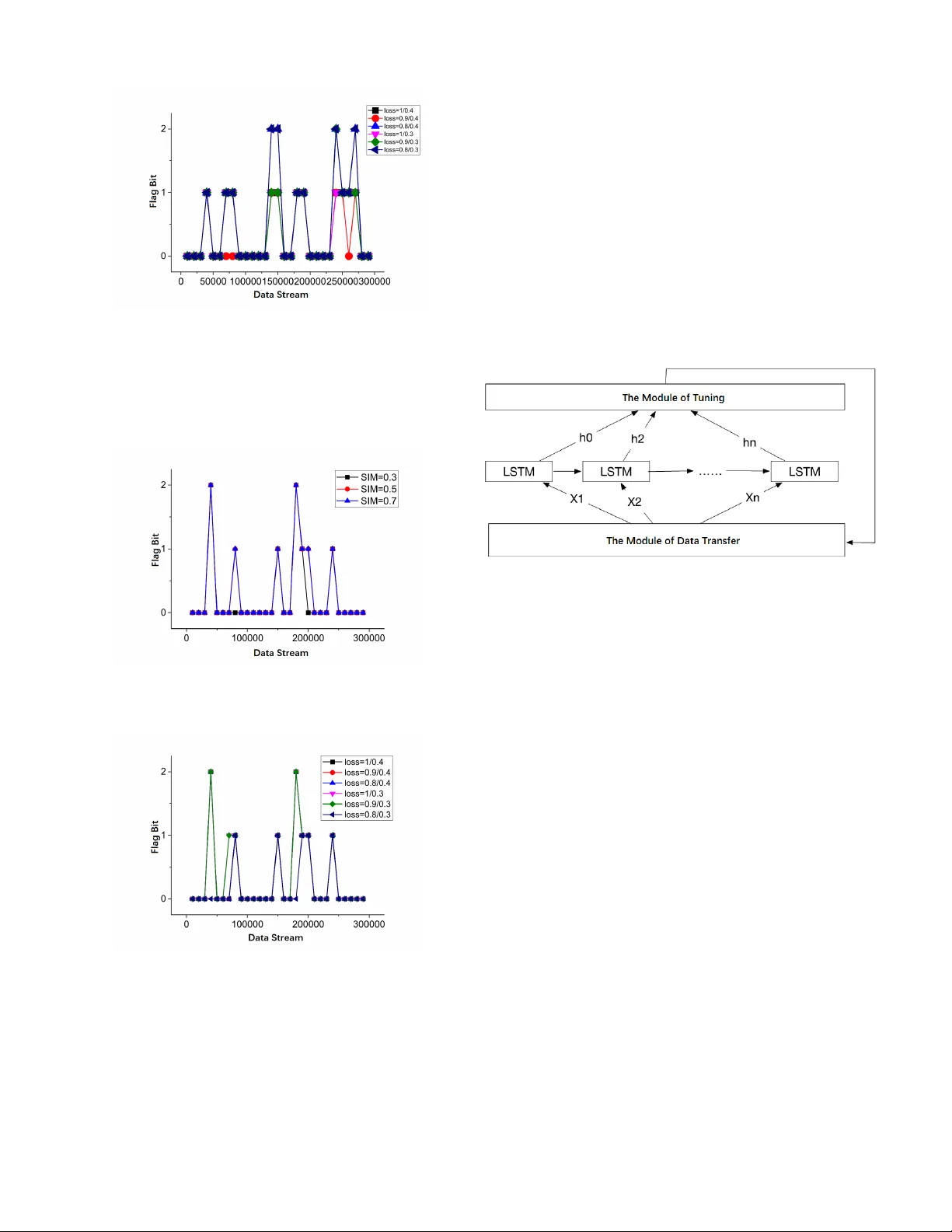
- **Algorithm 1 (update)**: 유사도와 손실을 순차적으로 평가해 플래그(0: 유지, 1: 부분 업데이트, 2: 재학습) 반환.
- **Algorithm 2 (lifelong)**: 누적 데이터 양이 최소량 \(L\) 에 도달했을 때만 Algorithm 1을 호출하고, 플래그에 따라 모델을 그대로 유지, 부분 업데이트, 혹은 재학습한다.
- 복잡도 분석: 유사도 계산이 \(O(MN)\) (두 기간 데이터 크기), 손실 계산은 \(O(M)\). 전체 시간·공간 복잡도는 \(O(MN)\).
### 5. 실험 설정
- **데이터셋**:
- **산업 보일러**: 400 000+ 샘플, 70 차원(시간, 흐름, 압력, 온도 등)
- **산업 발전기**: 80 000+ 샘플, 38 차원(시간, 속도, 전력, 압력, 온도 등)
- **합성 발전기 데이터**: 시뮬레이션용 보조 데이터셋
- **예측 알고리즘**:
- **시계열 수율 예측**(LSTM 기반)
- **전이 학습 기반 고장 예측**(소스·타깃 장비 간 특징 전이)
- **평가 지표**: 회귀는 RMSE, 분류는 정확도·F1 점수.
### 6. 파라미터 탐색 및 결과
- 유사도 임계값을 0.3, 0.5, 0.7 로 변동시켜 최적값 탐색.
- 손실 변화율 임계값은 경험적으로 설정(예: \(y = 0.4\), \(x = 0.1\)).
- **주요 결과**:
- 데이터 갱신 모델을 적용한 경우, 두 알고리즘 모두 예측 정확도가 최소 **33 %** 향상.
- 특히 전이 학습 기반 고장 예측에서, 서로 다른 시점의 데이터가 섞였을 때 전이 효율이 급격히 감소하던 현상이 갱신 모델을 통해 크게 완화됨.
- 업데이트 빈도는 설정한 최소 데이터량 \(L\) 과 임계값에 따라 조절 가능해, 과도한 재학습을 방지하면서도 최신 데이터에 대한 적응성을 유지.
### 7. 논의 및 한계
- **장점**: 모델 수명 연장, 인간 개입 최소화, 실시간 데이터 흐름에 대한 자동 적응.
- **제한점**:
- 유사도·손실 임계값을 도메인별로 튜닝해야 하는 부담.
- 대규모 데이터에서 \(O(MN)\) 복잡도가 실시간 적용에 제약될 수 있음(특히 고주파 센서 데이터).
- 현재는 두 개의 예측 알고리즘에만 적용했으며, 복합적인 다중 모델 환경에서의 확장성 검증이 필요.
### 8. 결론 및 향후 연구
본 연구는 **데이터 기반 자동 갱신**이라는 관점에서 산업 예측 모델의 지속 가능한 운영 방안을 제시한다. 향후 연구에서는
- 임계값 자동 최적화(베이즈 최적화·강화학습)
- 스트리밍 환경에서의 **샘플링 기반 유사도 계산**(시간 복잡도 감소)
- 다중 모델·다중 작업 환경에서의 **협업 갱신 메커니즘**
을 탐색함으로써, 보다 실시간에 가까운 스마트 팩토리 구현에 기여할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기