강화학습 정책의 스파이크 신경망 변환을 통한 ATARI 게임에서의 견고성 향상
초록
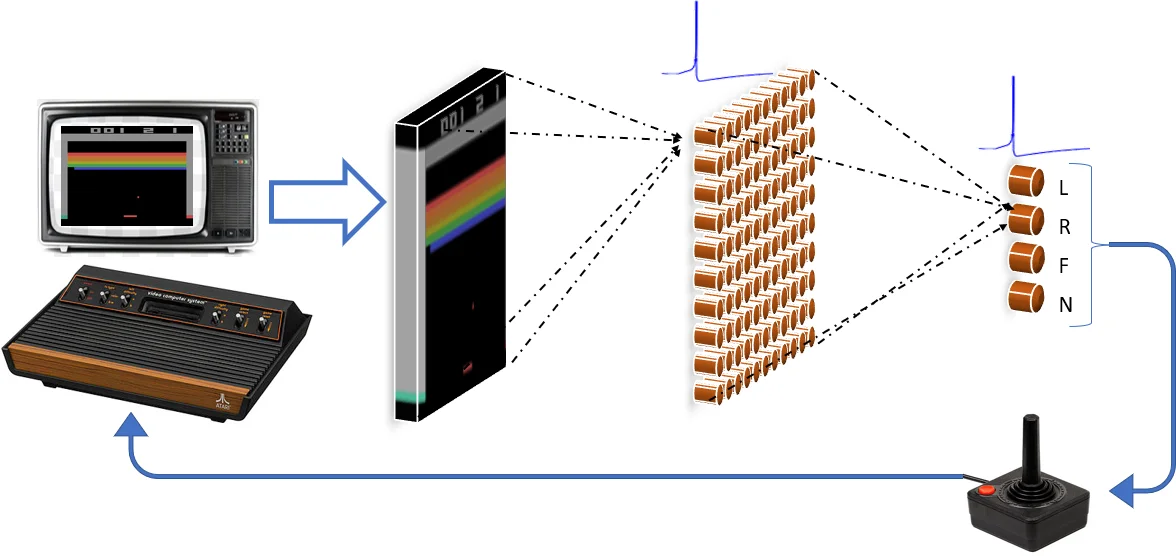
본 연구는 딥 강화학습(RL) 정책의 취약한 입력 민감도를 해결하기 위해, 학습된 ReLU 인공 신경망을 스파이크 신경망(SNN)으로 변환하는 방법을 제시한다. ATARI 브레이크아웃 게임에서 실험한 결과, 변환된 SNN이 원본 네트워크와 동등한 성능을 유지하면서 입력 이미지의 일부가 가려지는 경우(occlusion)에 대해 더욱 견고한 성능을 보임을 입증했다. 이는 SNN이 에너지 효율적인 뉴로모픽 하드웨어에서 강화학습 애플리케이션의 견고성을 높일 수 있는 가능성을 시사한다.
상세 분석
이 논문의 핵심 기술적 통찰은 지도학습 영역(예: 이미지 분류)에서 검증된 ‘사전 학습된 ReLU NN을 SNN으로 변환’하는 방법론을 강화학습 도메인으로 성공적으로 확장했다는 점이다. 연구팀은 ATARI 브레이크아웃 게임을 플레이하는 Q-Learning 네트워크(얕은 네트워크 및 본격적인 DQN)를 학습시킨 후, ReLU 활성화 함수를 다양한 스파이크 뉴런 모델(Integrate-and-Fire, Leaky Integrate-and-Fire 등)로 대체하여 SNN으로 변환했다.
변환의 성공을 위해 몇 가지 중요한 기술적 조치가 적용되었다. 첫째, SNN 시뮬레이션을 충분히 많은 시간 단계(nt=500) 동안 실행하여 출력층 뉴런의 발화 빈도(Firing Rate)를 안정적으로 측정했으며, 이 빈도가 원본 ReLU NN의 Q-value 추정치에 비례하도록 했다. 둘째, 가중치 정규화(Weight Normalization) 기법을 적용하여 스파이크 활동의 과소 또는 과대 발생으로 인한 오차를 줄였다. 특히 Subtract-IF 뉴런 모델을 사용해 스파이크 발생 시 임계값을 초과한 전압을 ‘기억’하도록 함으로써 정보 손실을 최소화했다.
가장 주목할 만한 결과는 변환된 SNN이 ‘occlusion’ 공격에 대해 원본 ReLU NN보다 향상된 견고성(Robustness)을 보였다는 것이다. 이는 SNN의 이벤트 기반 동작과 뉴런 집단의 집단적 효과가 내부 및 외부 노이즈를 효과적으로 완화하는 생물학적 시스템의 특성을 모방하기 때문으로 해석된다. 이는 기존 딥 RL이 특정 입력 영역에 과도하게 의존하는 취약점을 SNN이 부분적으로 해결할 수 있음을 시사하며, 향후 적대적 공격에 강인한 AI 시스템 개발에 SNN이 기여할 수 있는 길을 열었다.
댓글 및 학술 토론
Loading comments...
의견 남기기