브랜치형 오토인코더로 배우는 형태 공동분할
초록
BAE‑NET은 형태 공동분할을 표현 학습 문제로 정의하고, 입력 형상의 전체를 재구성하면서 각 브랜치가 반복적으로 나타나는 파트를 학습하도록 설계된 브랜치형 오토인코더이다. 무라벨 데이터만으로도 내부‑외부 판별 손실을 최소화해 파트별 암시적 필드를 얻으며, 소수의 라벨이 있는 예시를 추가하면 원-샷 학습이 가능하다. 실험 결과, 제한된 라벨만으로도 기존 감독 학습 기반 방법들을 능가한다.
상세 분석
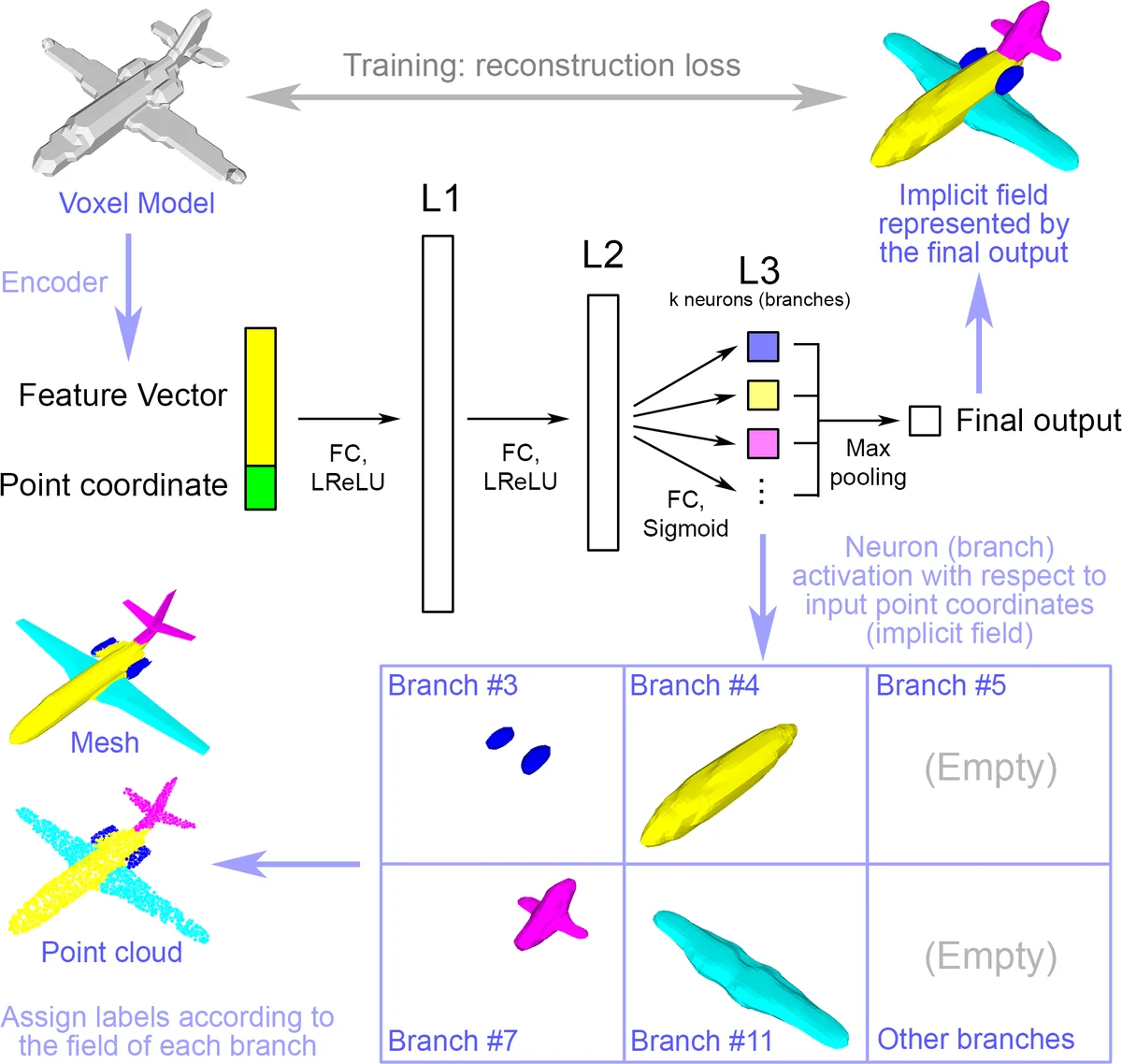
BAE‑NET은 기존의 이미지·점 클라우드 분할 네트워크와 달리 “브랜치형 디코더”라는 독특한 구조를 도입한다. 인코더는 3D voxel 혹은 2D 이미지에서 전통적인 CNN을 사용해 전역 특징 벡터를 추출하고, 이 벡터를 각 샘플링 포인트 좌표와 연결한다. 디코더는 3‑layer fully‑connected 네트워크이며, 최종 레이어(L3)의 각 뉴런이 하나의 파트를 담당한다. 각 브랜치는 독립적인 이진 판별기 역할을 하여, 입력 포인트가 해당 파트 내부에 있으면 1, 외부이면 0을 출력한다. 최종 형태는 모든 브랜치 출력을 max‑pooling으로 합쳐 얻으며, 이는 파트 간 겹침을 자연스럽게 허용한다.
학습은 두 가지 손실을 조합한다. 무라벨 상황에서는 샘플링된 포인트와 그 실제 내부‑외부 라벨(바이너리) 사이의 MSE(L_unsup)를 최소화한다. 이때 디코더는 전체 형태를 재구성하면서 동시에 각 브랜치가 가능한 한 단순하고 연속적인 파트 표현을 학습하도록 압박받는다. 라벨이 있는 경우에는 각 브랜치별 출력과 파트 라벨 사이의 MSE(L_sup)를 추가한다. 원‑샷 학습에서는 전체 데이터에 대해 L_unsup을 적용하고, 소수의 라벨이 있는 샘플에 대해서만 L_sup을 주기적으로 적용한다. 이렇게 하면 네트워크는 라벨이 없는 다수의 형태에서 일반적인 파트 구조를 스스로 발견하고, 라벨이 있는 몇 개의 예시를 통해 파트 이름을 자동 매핑한다.
브랜치 수는 사전에 정해지며, 일반적으로 데이터셋에 존재하는 파트 종류와 일치하도록 설정한다. 파트가 과도하게 겹치는 것을 방지하기 위해 L3 파라미터에 작은 L1 정규화를 적용한다. 실험에서는 2D 이미지, 3D voxel, 그리고 PointNet 기반 점 클라우드 등 다양한 입력 형태에 동일한 아키텍처를 적용했으며, 200k iteration 정도의 학습으로 1시간 내외(카테고리당) 수렴한다.
핵심적인 기여는 (1) 파트별 암시적 필드를 직접 학습하는 브랜치형 디코더 설계, (2) 라벨이 없는 데이터에서도 파트 구분을 가능하게 하는 재구성 기반 손실, (3) 소수 라벨만으로도 강력한 원‑샷 세그멘테이션을 구현하는 손실 결합 전략이다. 특히 max‑pooling을 통한 파트 합성은 파트 간 겹침을 자연스럽게 처리해 복잡한 형태(예: 램프의 여러 개별 파트)도 정확히 분리한다. 결과적으로 BAE‑NET은 기존의 대규모 라벨링이 필요한 지도 학습 방식 대비 라벨 효율성을 크게 향상시키면서도 정밀한 공동분할 성능을 달성한다.
댓글 및 학술 토론
Loading comments...
의견 남기기