고에너지 입자 물리학을 위한 차세대 전송 코드 GeantV 개발과 성능 평가
초록
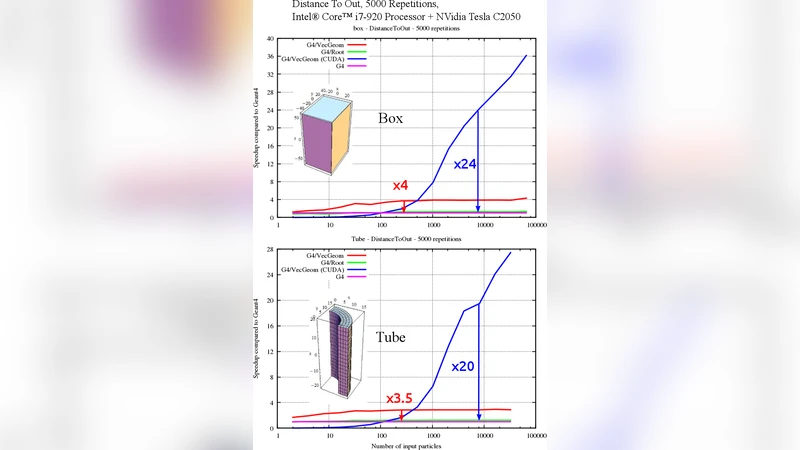
본 논문은 기존 Geant4의 한계를 극복하고자 CPU·GPU 다중코어 환경에서 SIMD 기반 벡터화와 스케줄러를 도입한 GeantV 프로젝트와 그 핵심 라이브러리인 VecGeom의 구현·성능을 소개한다. 간단한 박스와 튜브 형상에 대해 CPU(SSE4.2)와 NVIDIA Tesla C2050 GPU에서 수행한 거리 계산 테스트 결과, 입자 수가 증가할수록 GPU에서 10배 이상, CPU에서도 2~3배의 속도 향상이 관찰되었다.
상세 분석
GeantV는 Geant4가 20년 넘게 HEP 커뮤니티에서 표준으로 사용되어 온 점을 감안할 때, 향후 수십 년간 유지·확장이 가능한 구조를 목표로 설계되었다. 핵심 설계는 세 단계로 구분된다. 첫째, Scheduler는 입자들을 동일한 볼륨 타입별로 ‘바스켓’에 모아 SIMD 명령어를 활용해 동시에 처리함으로써 메모리 접근 패턴을 최적화하고, 입자 간 의존성을 최소화한다. 이는 Geant4가 순차적으로 한 입자씩 추적하는 방식과 근본적으로 다르며, 입자 수가 많을수록 스케줄러의 효율이 급격히 상승한다는 점이 실험적으로 확인된다.
둘째, Physics 모듈은 현재 테이블 기반(lookup table) 접근을 채택하고 있다. 물리 과정의 확률 분포와 최종 상태를 사전에 계산해 다차원 테이블에 저장함으로써 런타임에 복잡한 수치 적분을 회피한다. 이 방식은 계산량을 크게 줄이지만, 테이블 해상도에 따라 정확도가 제한될 수 있다. 향후 고해상도 테이블 또는 동적 보간 기법을 도입하면 정확도와 메모리 사용량 사이의 트레이드오프를 조정할 수 있다.
셋째, Geometry 모듈인 VecGeom은 GeantV의 성능 핵심이다. 기본 3차원 원시형(박스, 튜브 등)의 좌표 변환·거리 계산을 SIMD 라이브러리(Vc)와 CUDA를 이용해 동일한 템플릿 코드로 구현하였다. CPU에서는 SSE4.2, AVX, AVX‑512 등 다양한 명령어 집합을 자동 선택하도록 설계했으며, GPU에서는 CUDA 커널을 통해 수천 개 스레드가 동시에 실행된다. 또한 OpenCL·SYCL 포팅을 진행 중이라, NVIDIA 외에도 AMD·Intel GPU에서의 이식성을 확보하려는 의도가 엿보인다.
성능 테스트에서는 두 가지 기본 형상(박스, 튜브)에 대해 ‘DistanceToOut’ 메서드를 5,000번 반복 측정하였다. 결과는 입자 수가 10⁴ 수준일 때 CPU에서 약 2배, GPU에서는 8~12배의 속도 향상을 보였으며, 입자 수가 10⁶을 초과하면 GPU 가속 비율이 더욱 증가한다. 이는 GPU가 대규모 데이터 병렬 처리에 최적화된 구조임을 재확인시킨다. 다만, 작은 입자 수에서는 오버헤드(데이터 전송·커널 런치 비용) 때문에 CPU가 유리한 경우도 관찰되었다.
전체적으로 GeantV는 다중 레벨 병렬성(스케줄러 수준, SIMD 수준, GPU 수준)을 결합함으로써 기존 Geant4 대비 2~10배 이상의 가속을 목표로 한다. 현재는 기본 기하학 연산에 국한되어 있지만, 물리 프로세스와 복합 볼륨 지원이 추가되면 전체 시뮬레이션 파이프라인에서도 유사한 비율의 개선이 기대된다. 향후 과제는 테이블 기반 물리 모델의 정밀도 향상, 복잡한 복합 볼륨에 대한 SIMD 최적화, 그리고 다양한 GPU 아키텍처에 대한 포팅이다.
댓글 및 학술 토론
Loading comments...
의견 남기기