가변 입력 길이 셀프오가니징 맵을 이용한 모티프 탐색 및 단어 구분
본 논문은 Self‑Organizing Map 기반의 VILMAP 모델을 제안한다. VILMAP은 입력 차원의 가변성을 허용하여 서로 다른 길이의 시계열 패턴(모티프)을 동시에 군집화하고, 이를 통해 표준 모티프 데이터셋과 영유아 언어 습득 실험에서 기존 방법과 동등하거나 우수한 성능을 보인다. 또한 입력 크기가 점진적으로 증가해도 재학습 시 발생하는 재앙적 망각을 효과적으로 억제한다.
저자: Raphael C. Brito, Hansenclever F. Bassani
본 논문은 시계열 모티프 탐색(Time Series Motif Discovery, TSMD)과 영유아 언어 습득에서 핵심적인 문제인 단어 구분(Word Segmentation)을 동시에 해결할 수 있는 새로운 신경망 모델인 Variable Input Length MAP(VILMAP)을 제안한다. 기존의 Self‑Organizing Map(SOM)은 고정된 입력 차원을 전제로 하여, 서로 다른 길이의 패턴을 동시에 군집화하기에 한계가 있었다. 이러한 문제를 해결하고자 저자들은 LARFDSSOM(Local Adaptive Receptive Field Dimension Selective SOM) 모델을 기반으로, 입력 차원을 동적으로 조절할 수 있는 메커니즘을 추가하였다.
VILMAP의 핵심 아이디어는 각 노드가 현재 담당하고 있는 차원 수 m 을 저장하고, 새로운 입력이 기존 차원보다 길면 updateNodeDimension 함수를 통해 노드의 중심벡터 c, 가중치 ω, 거리벡터 δ 를 확장한다. 거리 계산은 가중치 ω 를 반영한 가중 거리 D_ω (식 2)를 사용하고, 이를 기반으로 라디얼 베이스 함수식(식 1)으로 활성화 a 를 구한다. 활성화가 사전에 정의된 임계값 a_t 보다 낮으면 새로운 노드를 삽입하고, 높으면 승자 노드와 이웃 노드들의 c, δ, ω 를 업데이트한다. 이 과정은 알고리즘 1에 상세히 기술되어 있다.
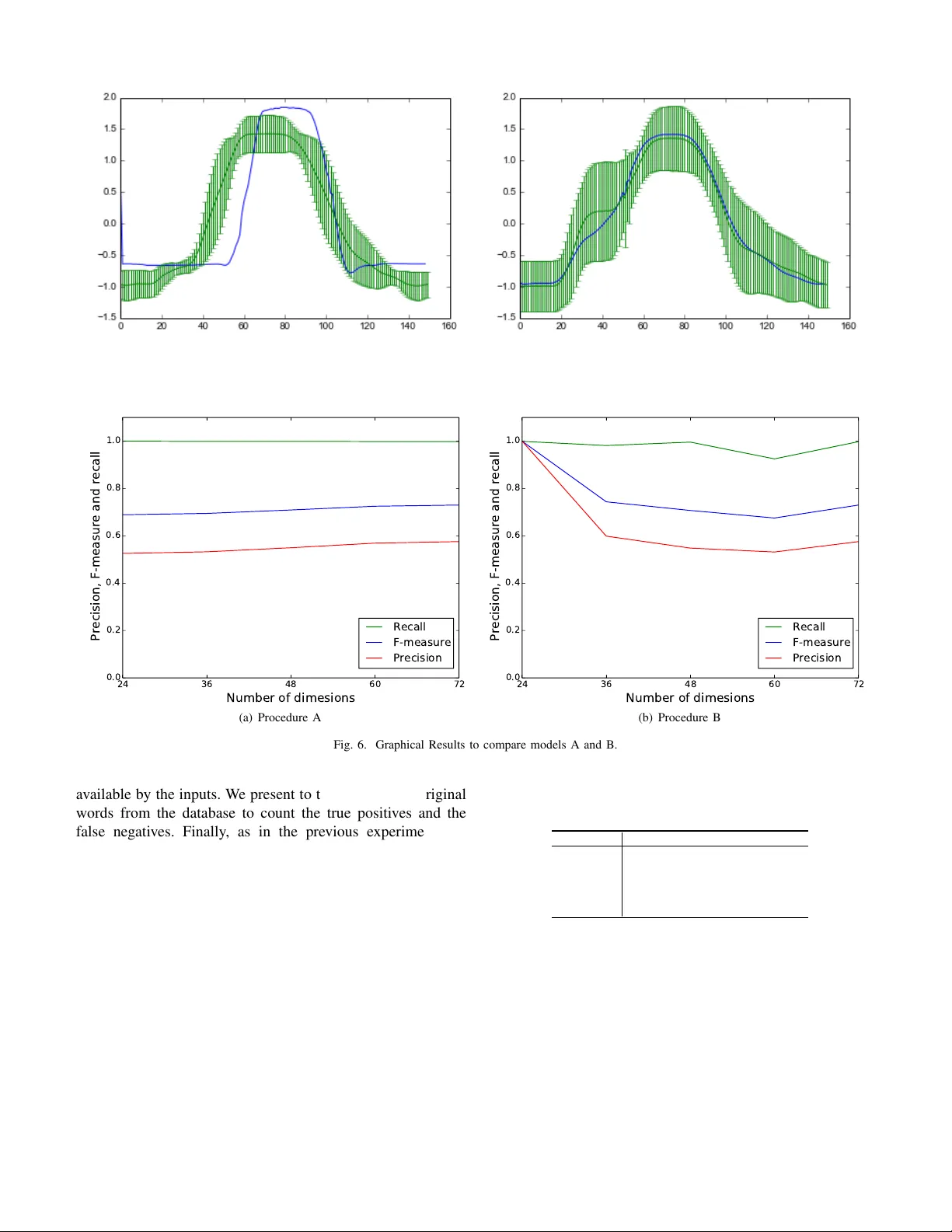
학습이 완료된 후, 클러스터링 단계(알고리즘 2)에서는 동일한 활성화 계산을 수행한 뒤, 임계값을 초과하는 가장 높은 활성화 노드에 입력을 할당한다. 이때 하나의 입력은 하나의 클러스터에만 속하도록 설계돼, 모티프와 단어 각각을 명확히 구분할 수 있다.
실험은 세 가지 주요 축으로 진행되었다. 첫째, 표준 시계열 모티프 데이터셋인 GunPoint를 이용해 VILMAP이 다양한 길이의 모티프를 정확히 탐지함을 확인하였다. 기존 VLMD와 비교했을 때, VILMAP은 동일하거나 더 높은 정확도와 재현율을 보였으며, 특히 길이가 다른 모티프를 하나의 맵에서 동시에 학습할 수 있다는 장점이 두드러졌다. 둘째, 입력 차원이 점진적으로 증가하는 시나리오에서 VILMAP이 재앙적 망각(catastrophic forgetting)을 방지함을 실증하였다. 기존 LARFDSSOM은 새로운 차원의 데이터가 들어올 때 기존 노드가 과도하게 수정되어 이전 패턴을 잃어버리지만, VILMAP은 차원 확장을 통해 기존 노드의 구조를 보존하면서 새로운 정보를 흡수한다. 셋째, CHILDES 코퍼스를 활용한 영유아 단어 구분 실험에서는 DiBS, Transitional Probabilities(TPs), PUDDLE, AGu 등 네 가지 대표적인 베이스라인과 비교하였다. VILMAP은 평균 F‑score와 정확도에서 경쟁력 있는 성능을 기록했으며, 특히 온라인 학습 환경에서 메모리 사용량이 제한된 상황에서도 안정적인 결과를 보여, 실제 언어 습득 모델링에 적용 가능함을 시사한다.
논문의 주요 기여는 다음과 같다. (1) 입력 차원의 가변성을 허용하는 SOM 기반 모델을 최초로 제안함으로써, 모티프와 단어 구분이라는 두 분야를 하나의 프레임워크로 통합했다. (2) 노드 차원 확장·축소 메커니즘을 통해 재앙적 망각을 효과적으로 억제하고, 연속적인 학습 시나리오에서도 성능 저하를 최소화했다. (3) 실험을 통해 기존 방법들과 동등하거나 우수한 성능을 입증했으며, 특히 온라인 학습과 메모리 효율성 측면에서 실용성을 강조했다.
하지만 몇 가지 한계점도 존재한다. 현재 구현은 1차원 시계열에 최적화돼 있어, 다변량 시계열이나 이미지와 같은 고차원 데이터에 대한 확장 가능성은 아직 검증되지 않았다. 또한 노드 삽입·삭제를 결정하는 임계값 a_t 과 학습률 β 등 파라미터가 고정값으로 설정돼 있어, 데이터 특성에 따라 민감하게 동작할 수 있다. 마지막으로, 실험 재현성을 높이기 위한 파라미터 튜닝 과정과 코드 공개가 제한적이다. 향후 연구에서는 다변량 입력 지원, 적응형 임계값 설정, 그리고 하드웨어 친화적 구현을 통해 실시간 스트리밍 데이터에 적용하는 방안을 모색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기