보상 강화 적응 스트레스 테스트로 자율주행 차량 검증
본 논문은 기존 적응 스트레스 테스트(AST)의 한계를 극복하기 위해 보상 함수를 두 가지 방식으로 확장한다. 첫째, 책임‑민감 안전(RSS) 규칙을 활용해 차량이 잘못된 행동을 했을 때만 실패로 간주하도록 하여, 불가피한 충돌을 배제한다. 둘째, 실패 궤적 간의 차이도를 보상에 포함시켜 서로 다른 유형의 실패를 다양하게 탐색한다. 시뮬레이션 실험에서 제안 방법은 기존 AST보다 더 풍부하고 의미 있는 실패 시나리오를 발견함을 보였다.
저자: Anthony Corso, Peter Du, Katherine Driggs-Campbell
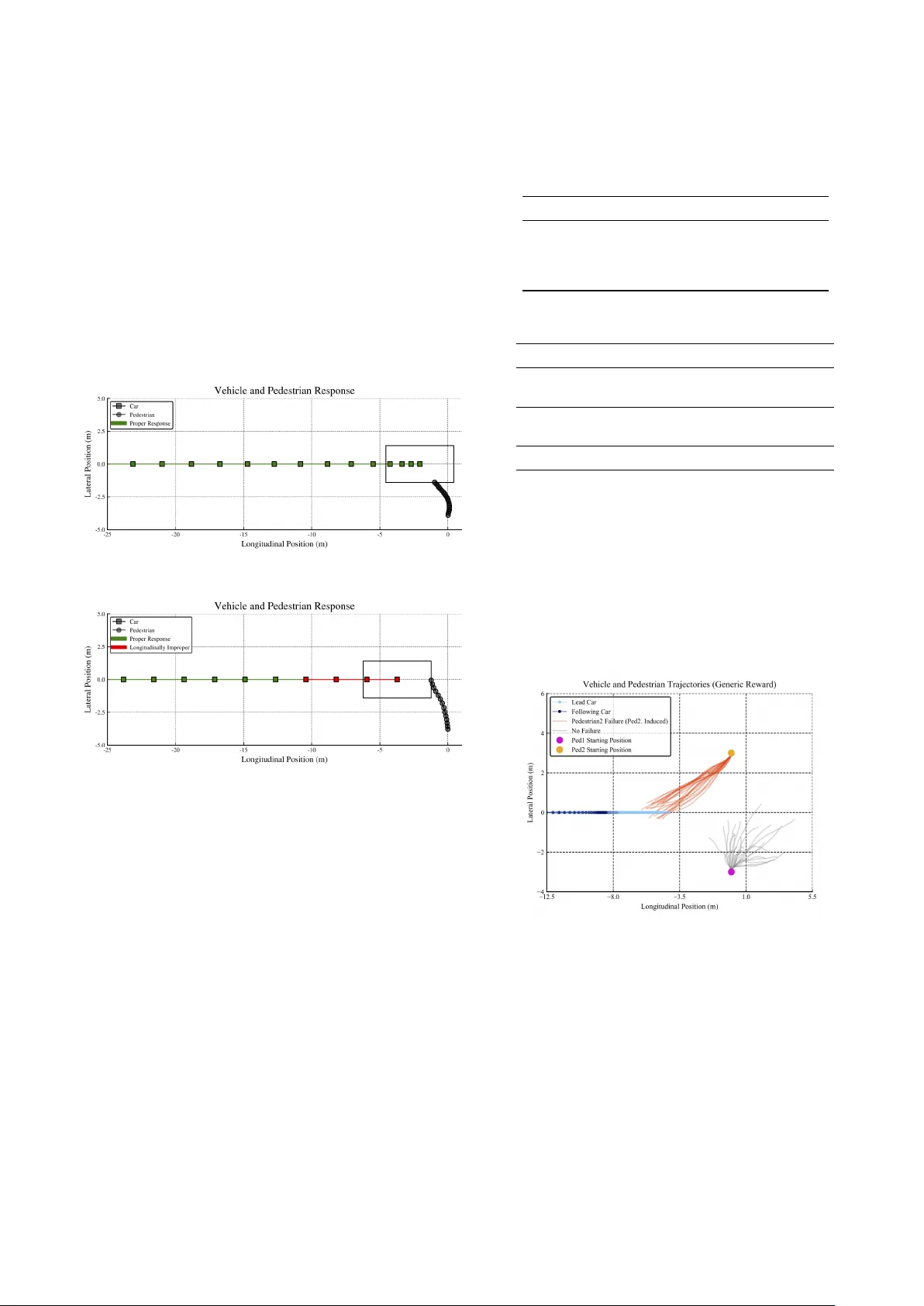
본 연구는 자율주행 차량(AV) 검증을 위한 시뮬레이션 기반 적응 스트레스 테스트(AST)의 한계를 보완하고자, 보상 함수를 두 가지 방식으로 확장한 새로운 프레임워크를 제안한다. 기존 AST는 시뮬레이션 환경을 마코프 결정 과정(MDP)으로 모델링하고, 강화학습(RL) 알고리즘을 통해 가장 가능성이 높은 실패 시나리오를 탐색한다. 그러나 두 가지 주요 문제점이 있다. 첫째, 충돌이 불가피한 상황까지도 실패로 간주해, 실제 시스템 결함을 드러내지 못한다. 둘째, 탐색이 동일하거나 유사한 실패 유형에 머무르는 경향이 있어, 다양한 위험 상황을 포괄적으로 평가하지 못한다.
이를 해결하기 위해 저자들은 보상 함수를 도메인 지식과 다양성 확보 메커니즘을 반영하도록 설계하였다. 첫 번째 보상 확장은 책임‑민감 안전(Responsibility‑Sensitive Safety, RSS) 규칙을 도입한다. RSS는 차량 간 최소 안전 거리, 반응 시간, 최대 가속·제동 능력 등을 수학적으로 정의하여, 각 에이전트가 “적절한” 반응을 했는지 판단한다. 논문에서는 시뮬레이션 각 타임스텝마다 AV가 RSS 규칙을 위반했는지 여부를 평가하고, 위반된 타임스텝 비율 f_imp 를 계산한다. 보상 함수는 f_imp 가 사전 정의된 임계값 f_crit 보다 큰 경우에만 해당 시나리오를 실패 집합 E_RSS 에 포함시킨다. 이렇게 하면 차량이 규칙을 위반한 경우에만 충돌을 “책임 있는” 실패로 인정하게 되어, 불가피한 충돌을 배제하고 실제 제어 정책의 결함을 강조한다.
두 번째 보상 확장은 실패 궤적 간 차이도(dissimilarity)를 보상에 포함시키는 방법이다. 두 실패 궤적 τ₁, τ₂ 를 일정한 구간으로 나누어 각 구간의 중심점을 구하고, 유클리드 거리의 평균을 차이도로 정의한다. 보상 함수는 현재 실패 궤적과 기존 µ 개의 최상위 실패 궤적 간 차이도의 평균에 가중치 γ 를 곱한 값을 추가 보상으로 제공한다. 이 메커니즘은 탐색 알고리즘이 이미 발견된 시나리오와 유사한 새로운 시나리오를 생성하는 것을 억제하고, 서로 다른 위험 패턴을 탐색하도록 유도한다.
실험 설정은 교차로에서 보행자와 마주치는 상황을 모델링하였다. 시뮬레이터는 차량의 제어 정책으로 Intelligent Driver Model(IDM)을 사용하고, 환경 행동(보행자 가속도, 센서 노이즈 등)을 AST가 제어한다. 보상 함수는 기본 AST 보상(충돌 여부, 상태 전이 확률, Mahalanobis 거리)과 위에서 소개한 두 확장 중 하나를 결합한다. 두 RL 솔버, Monte Carlo Tree Search(MCTS)와 Trust Region Policy Optimization(TRPO)를 사용해 각각의 보상 변형을 평가하였다.
RSS 보상 실험에서는 TRPO 기반 정책이 1000개의 액션 시퀀스를 샘플링했으며, 충돌이 발생한 시나리오를 기록하였다. 기존 AST는 차량 무과실 충돌이 다수를 차지했지만, RSS 보상은 차량이 RSS 규칙을 위반한 경우에만 충돌을 인정함으로써, 차량 과실 충돌만을 집중적으로 탐색했다. 이는 정책 개발자가 차량 제어 로직의 결함을 직접 확인할 수 있게 한다.
차이도 보상 실험에서는 MCTS와 TRPO 모두 기존 AST가 주로 동일한 충돌 유형(예: 보행자와 정면 충돌)을 반복적으로 찾는 반면, 차이도 보상은 보행자 회피 실패, 측면 스키드, 급제동 후 재가속 등 다양한 실패 모드를 생성했다. 특히, µ = 5, γ = 0.5와 같은 파라미터 설정에서 상위 5개의 실패 궤적과의 평균 차이도가 높은 새로운 시나리오가 지속적으로 발견되었다.
전체적으로, 보상 강화 AST는 (1) 차량의 책임을 명확히 구분해 불가피한 충돌을 배제하고, (2) 다양한 실패 유형을 탐색해 검증 범위를 확대한다는 두 가지 목표를 달성했다. 논문은 이러한 접근법이 자율주행 시스템 검증에 있어 보다 실용적이고 풍부한 실패 데이터셋을 제공함으로써, 정책 개선 및 안전성 보증에 기여할 수 있음을 입증한다. 또한, 도메인‑특화 보상 설계와 메타‑다양성 메커니즘이 시뮬레이션 기반 검증 프레임워크의 효율성을 크게 향상시킬 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기