다중 알고리즘·다중 인스턴스 실험 비교를 위한 표본 크기 계산 방법
초록
본 논문은 여러 알고리즘을 다수의 문제 인스턴스에 걸쳐 비교할 때, 필요한 인스턴스 수와 실행 횟수를 통계적으로 설계하는 방법을 제시한다. Holm 단계적 절차를 이용해 전체 유의수준을 유지하면서 최적의 검정력을 확보하고, 각 인스턴스별 알고리즘 실행 횟수는 최소 총 실행 수를 보장하는 비율로 배분한다. 21가지 변형 시뮬레이션 어닐링을 대상으로 한 사례 연구를 통해 실제 적용 과정을 보여준다.
상세 분석
이 연구는 메타휴리스틱 실험 설계에서 가장 핵심적인 두 가지 질문—‘얼마나 많은 인스턴스를 사용해야 하는가’와 ‘각 인스턴스당 몇 번의 실행이 필요한가’를 정량화한다. 기존 연구가 주로 인스턴스 수를 무조건 늘리거나 실행 횟수를 임의로 정하는 데 그쳤던 반면, 저자는 최소 실질 효과 크기(MRES)를 기준으로 원하는 검정력(power)을 사전에 설정하고, 그에 맞는 인스턴스 수를 계산한다. 다중 알고리즘 비교에서는 다중 가설 검정 문제가 발생하므로, 전체 유의수준을 보존하기 위해 Holm의 단계적 절차를 적용한다. 이는 Bonferroni와 달리 과도한 보수성을 피하면서도 가족 전체 오류율(FWER)을 제어한다.
실행 횟수 배분 측면에서는, 각 알고리즘‑인스턴스 쌍에 대한 평균 차이 혹은 비율 차이를 추정하는 데 필요한 표본 분산을 최소화하는 비율을 도출한다. 구체적으로, 차이 평균에 대한 경우는 σ²_i/σ²_j 비율에 따라 할당하고, 퍼센트 차이(상대 차이) 두 종류에 대해서도 각각 최적 비율을 제시한다. 이러한 비율은 전체 실행 수를 최소화하면서도 원하는 정확도(예: 신뢰구간 폭) 를 만족한다.
논문은 또한 ‘전체 블록 설계(CBD)’와 ‘계층적 모델’ 두 가지 분석 프레임워크를 논의한다. 블록 설계에서는 각 인스턴스별 평균값을 요약통계량으로 사용해 ANOVA 혹은 Friedman 검정을 수행하고, 계층적 모델은 인스턴스와 알고리즘 간의 교차 효과를 직접 모델링한다. 저자는 실제 연구에서는 블록 설계가 구현이 간단하고, 특히 비정규성이나 이분산 문제가 있을 때도 강건하게 작동한다는 점을 강조한다.
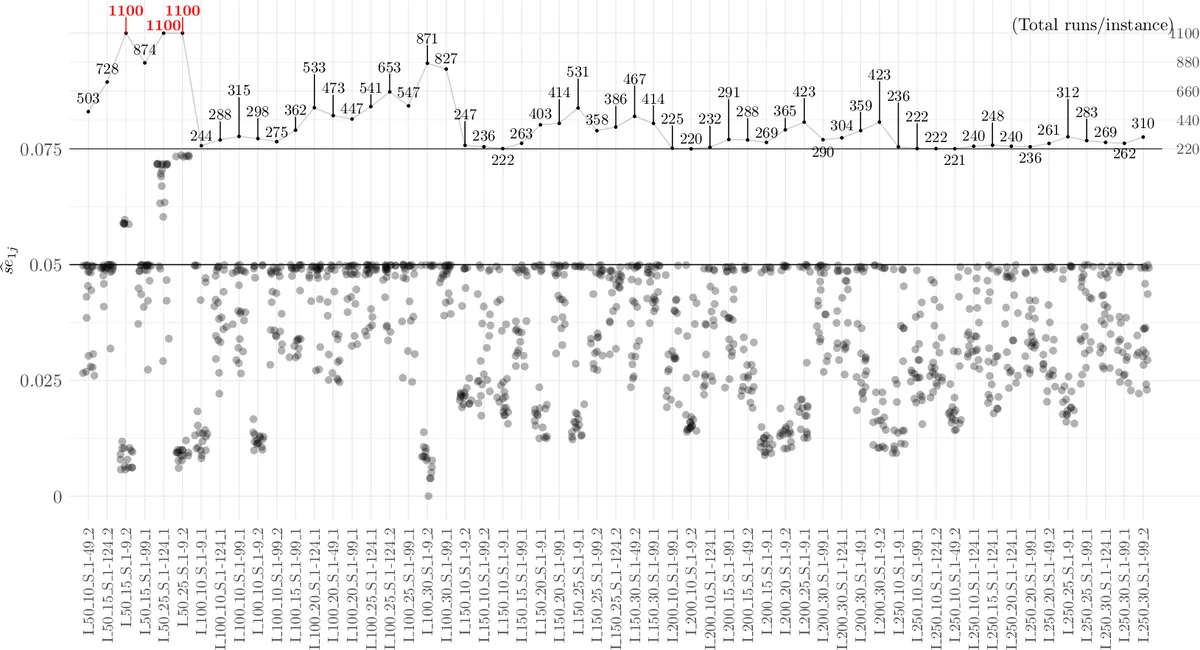
마지막으로 21가지 시뮬레이션 어닐링 변형을 대상으로 한 사례 연구에서, 목표 검정력 0.8, 유의수준 0.05, 최소 효과 크기 0.1을 설정하였다. 계산된 인스턴스 수는 30개, 각 인스턴스당 실행 비율은 최적화된 1:1.2:0.8 등으로 배분되었으며, 실제 실험 결과는 사전 설계된 검정력과 일치함을 확인했다. 이는 제안된 방법이 실제 메타휴리스틱 연구에 적용 가능함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기