분산 학습의 새로운 패러다임, DeepSqueeze: 오류 보정 압축을 활용한 탈중앙화 SGD
DeepSqueeze는 오류 보정(error‑compensated) 압축 기법을 탈중앙화(stochastic gradient descent) 환경에 적용한 알고리즘이다. 기존 탈중앙화 압축 방법보다 더 공격적인 압축 비율을 허용하면서도 수렴 속도를 유지한다. 이론적 수렴 분석과 실험 결과를 통해 DeepSqueeze가 기존 방법들을 일관되게 능가함을 입증한다.
저자: Hanlin Tang, Xiangru Lian, Shuang Qiu
**1. 서론 및 배경**
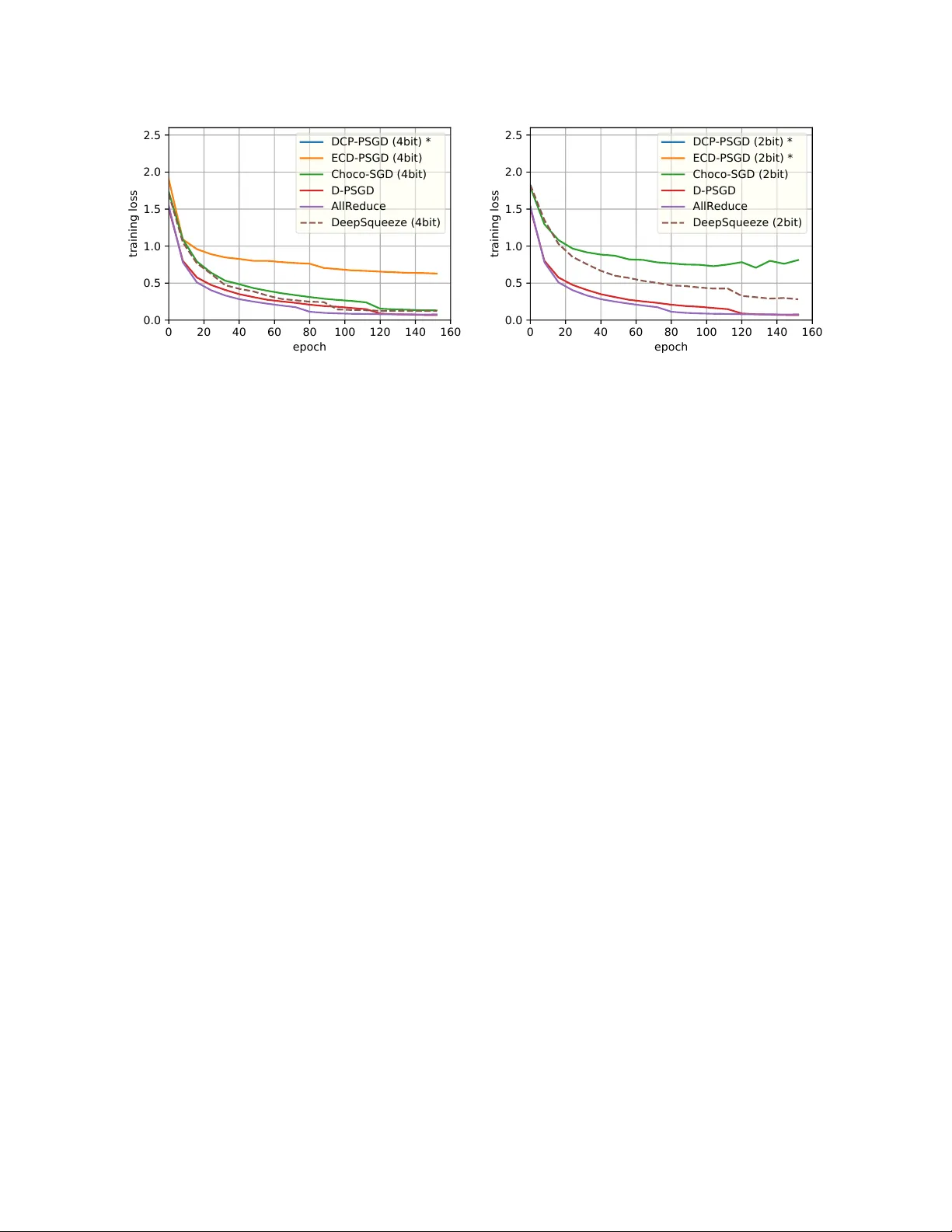
분산 딥러닝에서 통신 비용은 학습 속도를 제한하는 주요 요인이다. 중앙집중형(parallel) 학습은 파라미터 서버 혹은 AllReduce와 같은 집계 메커니즘을 사용해 모든 워커의 정보를 매 iteration마다 교환한다. 이때 압축(compression) 기법을 도입하면 전송량을 줄일 수 있지만, 압축이 편향(biased)되면 수렴이 불안정해진다. 최근 오류 보정(error‑compensated) 압축은 압축 오류를 로컬에 저장하고 다음 iteration에 보정함으로써, 매우 aggressive한 압축 비율(예: 1%까지)에도 수렴을 보장한다.
탈중앙화(decentralized) 학습은 각 워커가 이웃 노드와만 통신하기 때문에, 네트워크 토폴로지에 대한 제약이 적고 통신 비용이 크게 감소한다. 그러나 기존 탈중앙화 압축 방법(D‑PSGD, DCD‑PSGD, CHOCO‑SGD 등)은 압축 오류가 누적돼 수렴 속도가 저하되거나, 강한 가정(예: 강한 볼록성, 그래디언트 bounded) 없이는 이론적 보장이 어렵다.
**2. 문제 정의**
논문은 “오류 보정 압축을 탈중앙화 학습에 적용해도 수렴을 보장할 수 있는가?”라는 질문을 제기한다. 핵심 난관은 중앙집중형에서는 모든 워커가 동일한 파라미터를 공유하므로 오류 보정이 전역적으로 일관되지만, 탈중앙화에서는 각 노드가 서로 다른 로컬 파라미터를 유지하고, 압축된 메시지가 이웃에만 전파되기 때문에 오류 보정이 지역적으로만 적용될 위험이 있다.
**3. DeepSqueeze 알고리즘**
알고리즘 1에 요약된 DeepSqueeze는 다음 절차를 따른다.
1) 각 노드 i는 현재 파라미터 x_i^t와 학습률 γ를 사용해 스토캐스틱 그래디언트 g_i^t를 계산한다.
2) 로컬 오류 δ_i^t를 더해 오류 보정 변수 v_i^t = x_i^t – γ g_i^t + δ_i^t 를 만든다.
3) v_i^t 를 압축 연산 C_ω
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기