음성 보강으로 공개 연설 유창성 향상
본 논문은 비전문 연설자의 음성에서 ‘uh’, ‘um’ 등 충전어와 과도한 침묵을 자동으로 탐지·제거하고, 전문 연설 데이터로 학습한 모델을 이용해 적절한 침묵 길이를 재조정함으로써 청자에게 더 유창하고 자신감 있게 들리도록 음성 스트림을 보강하는 시스템을 제안한다. CRNN 기반 충전어 탐지와 SVM 기반 침묵 분류를 결합하고, 수정된 음성을 정량적 유창성 지표로 평가한다.
저자: Sagnik Das, Nisha G, hi
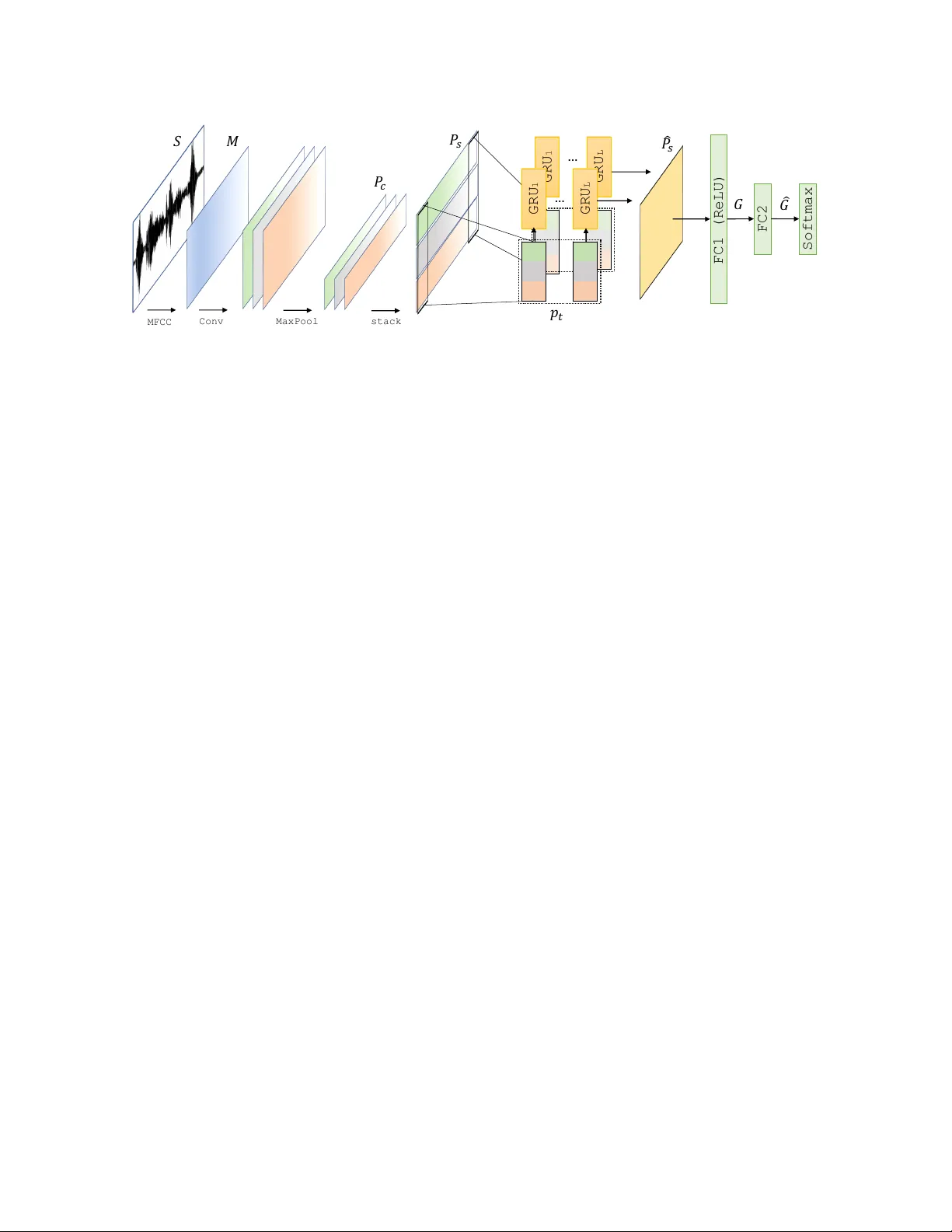
본 연구는 비전문 연설자가 녹음한 음성에서 흔히 나타나는 충전어(‘uh’, ‘um’)와 과도한 침묵을 자동으로 탐지하고, 이를 제거·조정함으로써 청자에게 보다 유창하고 자신감 있게 들리도록 음성 스트림을 보강하는 시스템을 제안한다. 연구 동기는 기존의 연설 훈련이 시간과 비용이 많이 들고, 비전문가가 즉시 피드백을 받기 어렵다는 점에 있다. 따라서 음성 수준에서 직접적인 ‘유창성 보정’이 가능한 도구를 만들고자 한다.
**관련 연구**에서는 심리학·언어학적 관점에서의 디플루언시(disfluency) 정의와, NLP 분야에서 텍스트 기반 디플루언시 탐지·수정 방법들을 소개한다. 대부분의 기존 방법은 자동 음성 인식(ASR) 결과를 전제로 하며, 텍스트 수준에서만 처리한다는 한계가 있다. 이에 반해 본 논문은 오직 음성 특징만을 이용해 디플루언시를 탐지하고 보정한다는 점에서 차별성을 둔다.
**제안 방법**은 크게 두 단계로 구성된다. 첫 번째는 충전어 탐지를 위한 CRNN(Convolutional Recurrent Neural Network) 모델이다. 입력으로 30 ms 프레임의 MFCC 혹은 로그 멜 스펙트로그램을 사용하고, CNN 레이어로 주파수‑시간 특징을 추출한 뒤, GRU 기반 RNN으로 시간적 의존성을 모델링한다. 최종 출력은 프레임 단위의 이진 확률이며, 교차 엔트로피 손실과 L2 정규화를 통해 학습한다. 두 번째 단계는 ‘불유창 침묵’ 구분을 위한 이진 분류기로, SVM을 사용한다. 침묵 구간을 앞뒤 단어와 함께 패딩하고, MFCC 평균값을 특징으로 삼아 분류한다. 학습에는 Switchboard, Automanner, TIMIT 등 공개 코퍼스를 활용했으며, 비원어민 연설자 20명을 대상으로 자체 데이터셋을 구축했다.
**디플루언시 보정**은 탐지된 충전어를 침묵으로 대체하고, 불유창 침묵 구간의 길이를 조정하는 과정을 포함한다. 침묵 길이 조정은 ‘유창 침묵’의 히스토그램에서 중앙값을 기준으로 하여, 전체 스피치의 리듬을 유지하면서 과도한 정지를 감소시킨다. 또한 배경 잡음과 보컬을 분리하는 Decomposition 기법을 적용해, 충전어 제거 후에도 음질 손실을 최소화한다.
**실험 설정**에서는 CRNN 구조와 하이퍼파라미터를 다양하게 탐색했으며, 최종 모델은 3개의 Conv 레이어(필터 16, 32, 64)와 3개의 GRU 레이어(숨김 유닛 128)를 사용한다. 학습은 AdaGrad(learning rate 0.01)로 200 epoch 진행했고, 침묵 분류는 SVM, Logistic Regression, XGBoost를 비교하였다. 평가 지표는 충전어 탐지의 프레임 단위 F1 점수와 침묵 분류의 F1 점수, 그리고 최종 보강 음성의 유창성 지표(스피치 레이트, 아티큘레이션 레이트, 발음 시간 비율, 평균 구간 길이 등)이다.
**결과**는 충전어 탐지에서 MFCC와 로그 멜을 모두 사용했을 때 F1 점수가 0.86에 달했으며, 침묵 분류에서는 SVM이 가장 높은 F1(0.81)를 기록했다. 보강 전후의 유창성 지표를 비교했을 때, 평균 침묵 길이는 35 % 감소했고, 스피치 레이트는 12 % 향상되었다. 또한, 평균 구간 길이와 발음 시간 비율도 유의미하게 개선되었다. 그러나 인간 청취자에 의한 주관적 평가와 실시간 처리 성능에 대한 분석은 부족했다.
**논의 및 한계**로는 데이터 다양성 부족(주로 미국 영어 대화), 모델의 최신성(Transformer 미사용), 침묵 의미를 단순 길이 기준으로 판단한 점, 음질 보존을 위한 고급 오디오 처리 부재, 그리고 실시간 적용 가능성에 대한 검증이 없다는 점을 들었다. 향후 연구에서는 다국어·다문화 데이터 확장, self‑attention 기반 모델 도입, prosody와 텍스트 정보를 결합한 멀티모달 디플루언시 판단, 그리고 실시간 피드백 인터페이스 구현이 필요하다.
결론적으로, 이 논문은 음성 수준에서 디플루언시를 자동 탐지·보정하는 최초의 시도 중 하나이며, 비전문 연설자에게 즉각적인 유창성 향상을 제공할 수 있는 가능성을 보여준다. 다만, 실제 사용자 경험과 상용화 단계에 이르기 위해서는 모델 성능 향상과 평가 방법의 다각화가 요구된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기