멀티코어 시스템용 BWA MEM 가속과 아키텍처 인식 최적화
초록
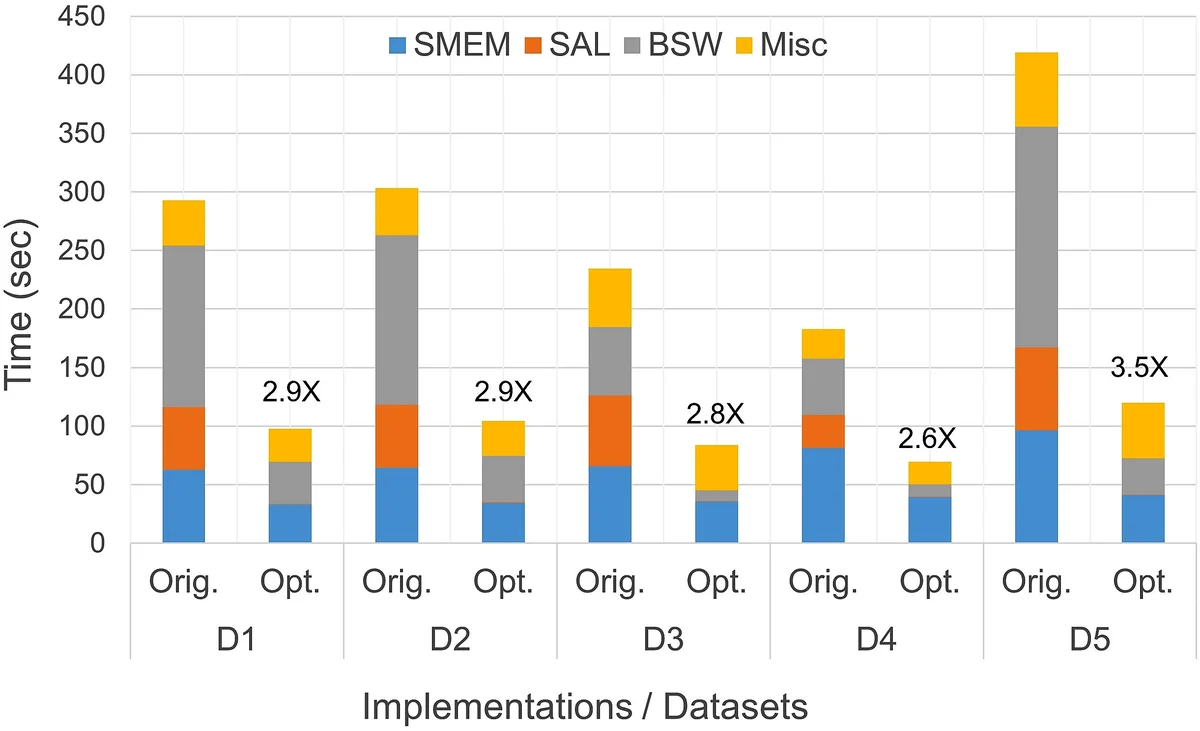
본 논문은 널리 사용되는 시퀀스 매핑 도구 BWA‑MEM의 핵심 3가지 커널(SMEM, SAL, BSW)을 멀티코어 환경에서 2배에서 183배까지 가속하고, 전체 파이프라인을 최대 3.5배 빠르게 만드는 아키텍처‑인식 최적화 기법을 제시한다. 캐시 재사용 향상, 메모리 할당 재구성, 소프트웨어 프리패치, SIMD 활용 등으로 동일한 출력 결과를 유지하면서 성능을 크게 개선한다.
상세 분석
BWA‑MEM은 FM‑index 기반의 시드 탐색(SMEM), 접미사 배열 조회(SAL), 밴드형 Smith‑Waterman(BSW)이라는 세 핵심 단계가 전체 실행 시간의 85 % 이상을 차지한다는 점을 먼저 정량화하였다. SMEM 단계는 압축된 O‑버킷 구조 때문에 매 읽기당 평균 285 k 명령을 수행하고, LLC 미스율이 높아 평균 메모리 지연이 24 클럭에 달한다. SAL 단계는 압축된 접미사 배열을 역참조하면서도 읽기당 약 5 k 명령을 소모한다. BSW 단계는 분기와 짧은 루프가 빈번해 스칼라 구현에 머물러 있어 명령어 수준 병목이 발생한다.
저자들은 이러한 병목을 해소하기 위해 다음과 같은 아키텍처‑인식 전략을 적용했다. 첫째, O‑버킷의 크기 η를 2의 거듭 제곱으로 설정해 나눗셈·모듈로 연산을 비트 시프트·AND 연산으로 대체, 연산량을 크게 감소시켰다. 둘째, 압축된 FM‑index와 접미사 배열을 대규모 연속 메모리 블록에 미리 할당하고 재사용함으로써 하드웨어 프리패치가 효율적으로 동작하도록 하여 메모리 대기 시간을 최소화했다. 셋째, 읽기 청크를 배치 단위로 재구성하고 OpenMP 동적 스케줄링을 적용해 각 배치 내에서 SIMD 벡터화가 가능한 BSW 연산을 동시에 수행하도록 설계했다. 넷째, 소프트웨어 프리패치를 명시적으로 삽입해 L1/L2 캐시 적중률을 높였으며, SIMD 명령어(AVX‑512) 활용을 통해 BSW의 행렬 연산을 8배 가속했다.
이러한 최적화 결과, SMEM 커널은 2배, SAL 커널은 무려 183배, BSW 커널은 8배의 속도 향상을 달성했으며, 단일 스레드 환경에서는 전체 파이프라인이 3.5배, 단일 소켓(스카이라인) 환경에서는 2.4배 빨라졌다. 특히 출력이 원본과 완전히 동일하도록 유지함으로써 기존 파이프라인을 그대로 교체할 수 있는 실용성을 확보했다.
댓글 및 학술 토론
Loading comments...
의견 남기기