텍스트‑투‑스피치 가속화: 적대적 보코딩의 새로운 패러다임
초록
본 논문은 TTS 파이프라인에서 가장 큰 병목인 보코딩을 해결하기 위해, 적대적 생성 네트워크(GAN)를 이용해 멜 스펙트로그램을 단순한 크기 스펙트로그램으로 변환하는 방법을 제안한다. 변환된 크기 스펙트럼에 빠른 위상 추정 기법(LWS)을 결합해 음성을 재생성함으로써, 기존 WaveNet·WaveGlow 기반 보코더보다 수백 배 빠른 속도와 인간 청취자 평가에서 높은 MOS 점수를 달성한다. 또한 압축 비율이 높은 특징 표현과 단어 단위 무지도 합성에서도 최첨단 성능을 보인다.
상세 분석
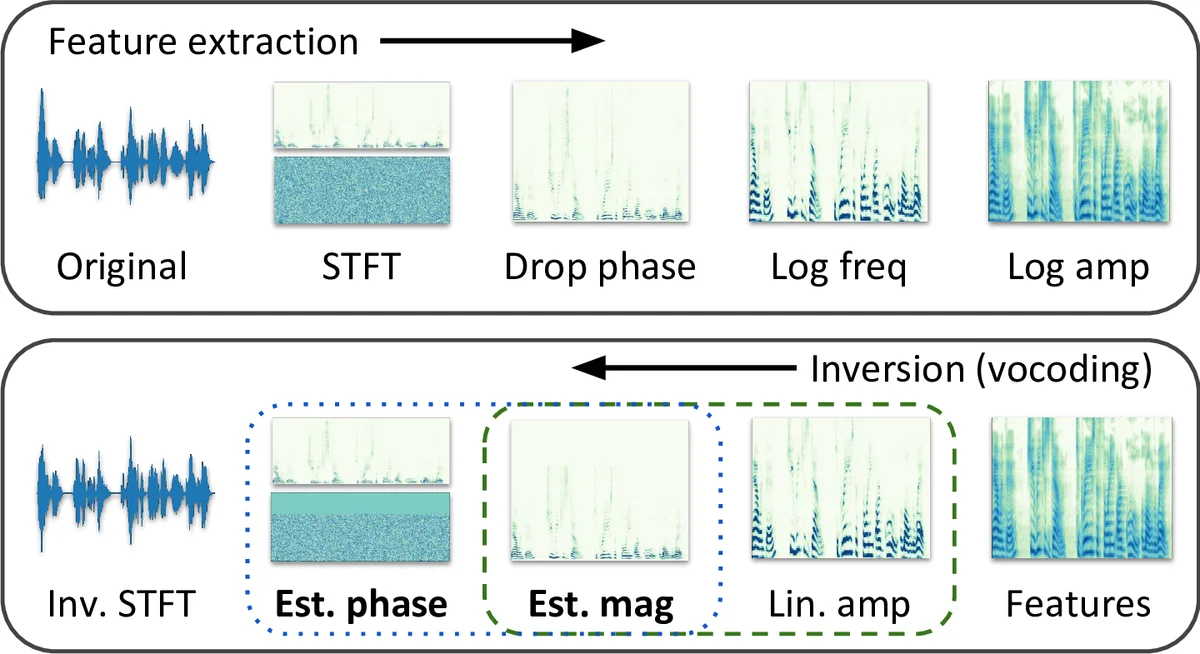
이 연구는 현대 TTS 시스템이 두 단계, 즉 텍스트→멜 스펙트로그램 변환과 멜 스펙트로그램→파형 보코딩으로 구성된다는 점을 출발점으로 삼는다. 멜 스펙트로그램은 인간 청각에 맞게 로그 스케일과 멜 주파수 축을 적용해 압축 효율을 높였지만, 위상 정보와 선형 주파수 크기 정보를 손실하기 때문에 직접 파형 복원이 불가능하다. 기존 최첨단 보코더인 WaveNet·WaveGlow는 이 두 손실을 동시에 복원하려고 시도하지만, 샘플당 수천 번의 신경망 연산을 필요로 해 실시간 처리에 큰 제약을 만든다.
저자들은 먼저 위상 복원과 크기 복원 각각이 음성 자연스러움에 미치는 영향을 사용자 실험(MOS)으로 정량화한다. 결과는 “위상이 좋은 경우(실제 위상 사용)와 크기만 이상적이면(실제 크기 사용) 모두 높은 MOS를 얻는다”는 점을 보여준다. 즉, 두 문제 중 어느 하나만 해결해도 충분히 자연스러운 음성을 얻을 수 있음을 확인한 것이다. 이때 위상 복원은 기존에 널리 쓰이는 Griffin‑Lim보다 빠르고 품질이 좋은 Local Weighted Sums(LWS) 방식을 채택한다.
핵심 기여는 크기 복원 문제에 GAN 기반의 조건부 이미지‑투‑이미지 변환(pix2pix)을 적용한 것이다. 멜 스펙트로그램을 입력으로, 실제 선형 크기 스펙트로그램을 목표로 하는 생성기와, 진짜·가짜 스펙트로그램을 구분하는 판별기로 구성한다. 생성기는 먼저 멜 → 선형 크기 변환을 위한 의사역행렬(pseudoinverse)로 초기 추정을 만든 뒤, U‑넷 형태의 인코더‑디코더를 통해 세밀한 구조를 보강한다. L1 손실과 적대적 손실을 가중합(λ=10)해 훈련함으로써, 전역적인 스펙트럼 형태는 유지하면서도 지역적인 디테일을 복원한다.
실험에서는 LJ Speech 데이터셋(13 k 클립, 24 h)과 Tacotron 2 기반 합성 멜 스펙트로그램을 대상으로, 20, 40, 80개의 멜 밴드 압축 비율을 모두 테스트했다. 모델은 1080 Ti GPU에서 100 k 배치(배치 8) 학습에 약 12 시간이 소요되었다. 평가 결과, 제안된 AdVoc(대형) 모델은 실시간 대비 3.1배 가속(×RT = 3.111)하면서 MOS‑Real = 3.78, MOS‑TTS = 2.91을 기록했다. 경량 모델(AdVoc‑small)은 더 높은 속도(×RT = 3.437)와 약간 낮은 MOS를 보였지만, 기존 WaveNet(×RT = 0.003, MOS ≈ 4.0)·WaveGlow(×RT ≈ 1.2, MOS ≈ 4.1)보다 속도·품질 균형이 우수했다. 또한 13:1 압축된 특징을 그대로 사용해도 높은 MOS를 유지했으며, 단어 단위 무지도 합성 실험에서도 최첨단 결과를 달성했다.
이 논문은 “위상 복원은 빠른 LWS로 충분히 해결 가능하고, 크기 복원만 GAN으로 고도화하면 전체 보코딩 파이프라인을 수백 배 가속할 수 있다”는 실용적 통찰을 제공한다. 향후 연구는 더 작은 모델·멀티스피커 확장, 그리고 실시간 스트리밍 TTS 시스템에 직접 통합하는 방향으로 진행될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기