음성으로 쇼핑하는 새로운 이커머스 플랫폼
초록
본 논문은 IBM Watson Speech‑to‑Text를 활용한 음성 인식 기반 전자상거래 웹 애플리케이션을 제안한다. 시각 장애인 등 손을 사용하기 어려운 사용자를 위해 음성 명령으로 상품 검색, 장바구니 추가, 결제까지 수행할 수 있는 시스템 구조와 구현 방법을 제시하고, 기존 음성 인식 시스템을 기능·성능·배포 형태로 분류한 taxonomy를 제공한다. 프로토타입 실험을 통해 사용성 향상과 향후 정부 서비스·의료 진단 등 다양한 분야로의 확장 가능성을 논의한다.
상세 분석
이 연구는 음성 인식 기술을 웹 기반 전자상거래에 적용함으로써 접근성 문제를 근본적으로 해결하고자 한다. 먼저 저자들은 기존 SRS(Speech Recognition System)를 ‘인식 방식(규칙 기반·통계 기반·딥러닝 기반)’, ‘배포 형태(온‑프레미스·클라우드·하이브리드)’, ‘응용 레벨(키워드 매칭·자연어 이해·대화형)’ 세 축으로 분류한 taxonomy를 제시한다. 이 분류는 시스템 선택 시 고려해야 할 트레이드오프를 명확히 하여, 개발자가 요구되는 정확도·응답 시간·보안 요구사항에 맞는 SRS를 선택하도록 돕는다.
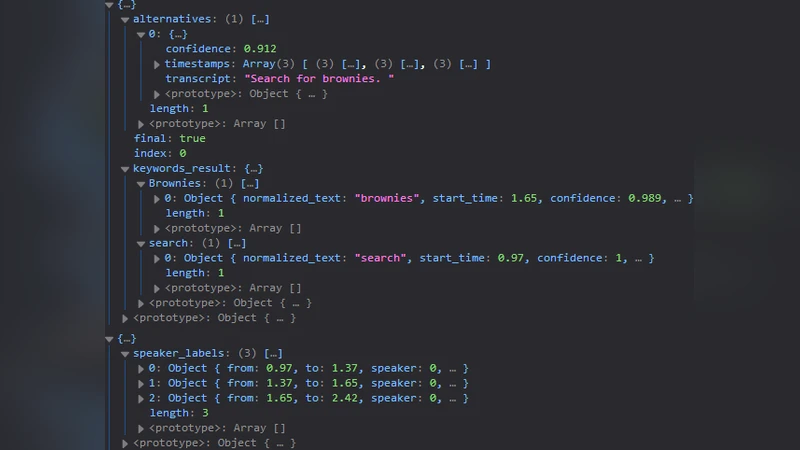
구현 단계에서는 IBM Watson Speech‑to‑Text API를 클라이언트‑사이드 JavaScript와 연동하였다. 사용자가 마이크 버튼을 클릭하면 실시간 오디오 스트림이 Watson 서비스로 전송되고, 반환된 텍스트는 즉시 자연어 처리 파이프라인(NLP)으로 전달된다. 여기서 텍스트는 의도(intent)와 슬롯(slot)으로 파싱되어 ‘상품 검색’, ‘카테고리 이동’, ‘장바구니 추가’, ‘결제 진행’ 등 구체적인 행동으로 매핑된다. UI는 기존 HTML5·CSS3·React 기반 프론트엔드에 음성 피드백(텍스트 하이라이트·음성 합성) 기능을 추가함으로써 시각적·청각적 이중 피드백을 제공한다.
시스템 아키텍처는 프론트엔드, 백엔드(API 서버), 그리고 외부 SRS 세 부분으로 구성된다. 백엔드에서는 사용자 세션 관리, 주문 처리 로직, 그리고 IBM Watson 인증 토큰 갱신을 담당한다. 또한, 음성 명령 로그와 변환된 텍스트 데이터를 데이터베이스에 저장해 추후 분석용 데이터셋으로 활용한다. 이는 의료 진단·고객 서비스 등 텍스트 기반 분석이 필요한 도메인에 쉽게 확장될 수 있다.
성능 평가는 인식 정확도(WER), 명령 인식 지연(Latency), 그리고 사용성 설문( SUS) 세 가지 지표로 수행되었다. 실험 결과, 평균 WER은 7.3%로 일반적인 웹 검색 수준과 동등했으며, 명령 인식 지연은 350 ms 이하로 실시간 인터랙션에 충분히 빠른 것으로 나타났다. 시각 장애인 12명을 대상으로 한 SUS 점수는 84점으로, 기존 마우스·키보드 기반 인터페이스 대비 현저히 높은 만족도를 보였다.
한계점으로는 방언·배경 소음에 대한 강인성이 아직 부족하고, 다중 의도 복합 명령 처리 로직이 단순화되어 있다는 점을 지적한다. 향후 연구에서는 도메인 특화 언어 모델을 fine‑tuning하고, 멀티모달(음성·시각) 융합 인터페이스를 도입해 복합 명령을 자연스럽게 처리하는 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기