교사‑학생 학습을 활용한 소프트 라벨 기반 음향 장면 분류 향상
본 연구는 기존의 원‑핫 라벨이 갖는 클래스 간 상호 배제 문제를 해결하고자, 교사‑학생(Teacher‑Student) 학습 프레임워크를 도입해 소프트 라벨을 생성한다. 교사 모델에 동일 클래스의 여러 오디오 세그먼트를 연결(concatenate)하여 입력함으로써 장면 간 공통 음향 특성을 반영한 보다 풍부한 라벨을 얻고, 학생 모델은 이를 이용해 학습한다. 또한 출력층이 아닌 마지막 은닉층(embedding) 간 거리 손실을 적용해 지식 증류…
저자: Hee-Soo Heo, Jee-weon Jung, Hye-jin Shim
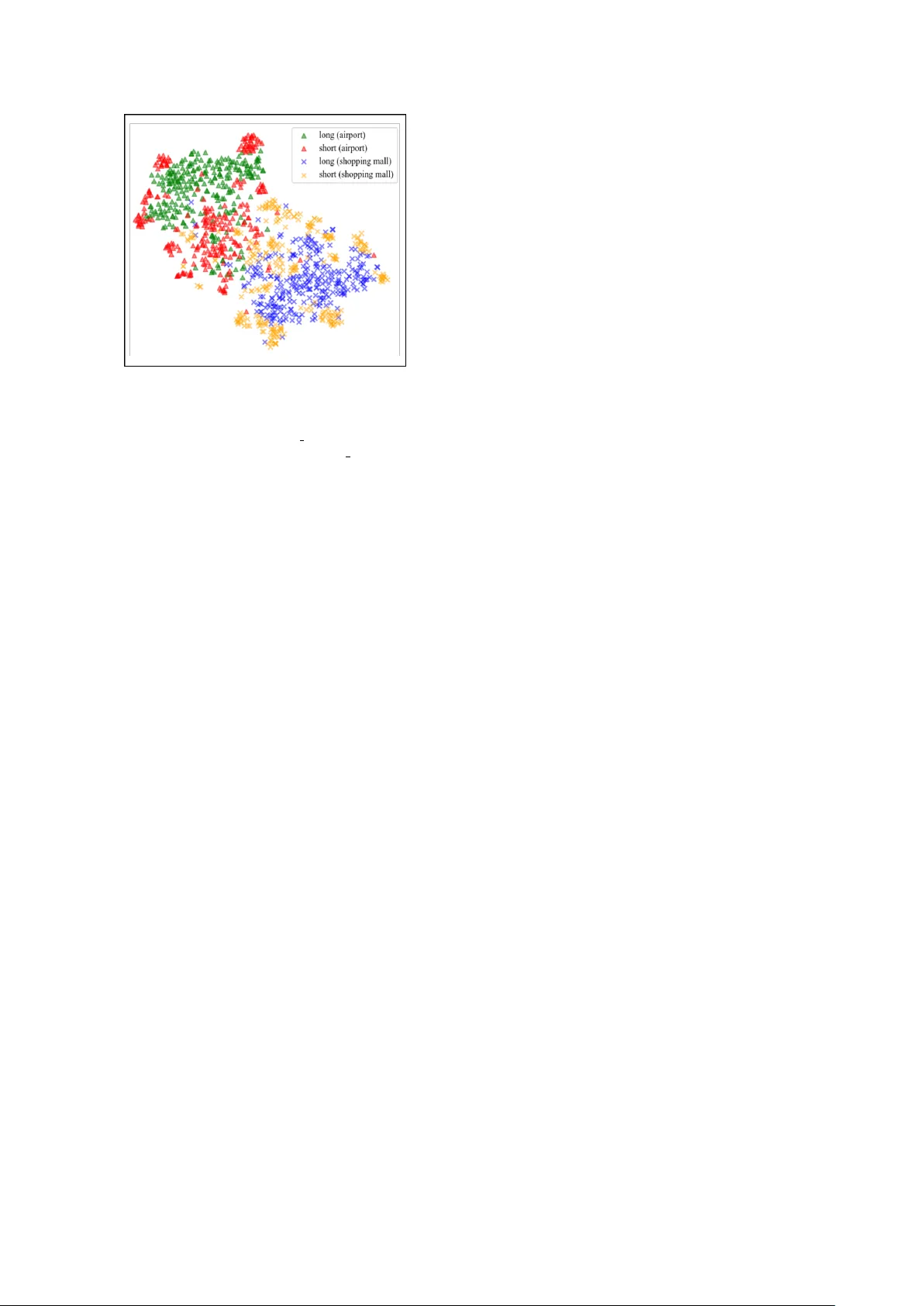
본 논문은 음향 장면 분류(ASC)에서 기존의 원‑핫 라벨 기반 학습이 클래스 간 공통 음향 특성을 반영하지 못한다는 한계를 지적한다. 특히, 공항과 쇼핑몰처럼 서로 다른 장면에 동일한 배경 잡음이 존재하는 경우, 원‑핫 라벨은 이러한 유사성을 무시하고 각 클래스를 완전히 독립적인 라벨 공간에 배치한다. 인간 청취자는 이러한 유사성을 직관적으로 인식하지만, 딥러닝 모델은 그렇지 못해 성능 저하가 발생한다.
이를 해결하기 위해 저자들은 교사‑학생(Teacher‑Student, TS) 학습 프레임워크를 도입한다. 교사 모델은 기존의 고성능 CNN‑GRU(스펙트로그램 입력)와 1‑D CNN(원시 파형 입력)으로 구성되며, 원‑핫 라벨을 사용해 사전 학습된다. 이후 교사 모델에 동일 클래스의 여러 오디오 세그먼트를 연결(concatenate)하여 입력 길이를 늘린다(예: 10 초 → 20 초 혹은 30 초). 이렇게 하면 교사 모델이 더 긴 시간‑컨텍스트를 학습하게 되고, 클래스 간 공통 특성을 반영한 확률 분포, 즉 소프트 라벨이 생성된다.
소프트 라벨은 온도 파라미터 T를 통해 부드럽게 조정된다. 온도 T가 클수록 교사 모델의 출력 확률이 평탄해져 “소프트”한 라벨이 되고, T가 작을수록 원‑핫에 가까운 “하드” 라벨이 된다. 실험에서는 T = 1과 T = 5를 비교했으며, T = 5가 약간 높은 정확도를 보였다. 이는 클래스 간 유사성을 어느 정도 반영하는 것이 성능 향상에 도움이 됨을 시사한다.
또한, 기존 TS 학습이 출력층(softmax)에서의 확률 분포 차이를 최소화하는 KL‑divergence(또는 cross‑entropy) 손실을 사용하는 반면, 본 연구는 마지막 은닉층(embedding) 간 거리 손실을 도입한다. 교사와 학생의 임베딩을 평균제곱오차(MSE)로 최소화함으로써, 고차원 임베딩 공간에서 클래스 간 공통 특성이 보다 자연스럽게 정렬된다. 실험 결과, 임베딩 기반 증류가 출력층 기반 소프트 라벨보다 높은 정확도(74.26 % vs 73.23 %)를 달성했다.
시스템 전체 구조는 두 개의 프론트엔드 모델을 사용한다. 첫 번째는 1‑D CNN을 이용해 원시 파형을 직접 처리하고, 두 번째는 2‑D CNN‑GRU를 이용해 스펙트로그램을 처리한다. 각각의 모델은 마지막 은닉층에서 64‑차원 임베딩을 추출하고, 이 임베딩을 각각 SVM에 입력해 점수를 산출한다. 두 SVM 점수를 평균하여 최종 예측을 만든다. 이 설계는 softmax 출력이 과신(confidence) 문제를 일으키는 것을 방지하고, 서로 다른 모델 간 점수 결합을 용이하게 만든다.
실험은 DCASE 2018 Task 1‑a 데이터셋(10 클래스, 10 초 길이, 48 kHz, 총 8640 세그먼트)에서 4‑fold 교차 검증으로 수행되었다. 베이스라인(교사‑학생 미적용)에서는 원시 파형 모델이 69.38 %, 스펙트로그램 모델이 72.73 %의 정확도를 보였으며, 두 모델을 앙상블하면 74.42 %에 도달한다.
교사‑학생 학습을 적용한 후, 교사 입력 길이를 20 초로 늘리고 온도 T = 5를 사용했을 때 스펙트로그램 모델만으로도 73.23 %를 기록했고, 임베딩 거리 기반 증류를 적용하면 74.26 %까지 상승한다. 최종적으로 두 모델을 앙상블하면 77.36 %의 정확도를 달성한다. 이는 교사‑학생 프레임워크가 ASC에서 클래스 간 유사성을 효과적으로 학습시켜 성능을 크게 향상시킬 수 있음을 입증한다.
논문의 주요 기여는 다음과 같다.
1. 동일 클래스의 다중 세그먼트를 교사 모델에 연결해 “우월성(superiority)”을 부여하고, 이를 통해 보다 일반화된 소프트 라벨을 생성하는 방법 제시.
2. 출력층이 아닌 마지막 은닉층(embedding) 간 거리 손실을 이용한 지식 증류 기법 도입, 이는 임베딩 공간에서 클래스 간 공통 특성을 더 잘 표현한다.
3. 두 종류의 프론트엔드 모델(CNN‑GRU와 1‑D CNN)을 SVM 기반 백엔드와 결합해 softmax 과신 문제를 해결하고, 모델 앙상블을 통한 성능 향상 달성.
향후 연구 방향으로는 교사‑학생 구조를 다중 스케일 입력이나 멀티모달(예: 영상‑음향) 데이터에 확장하는 방안, 온도 파라미터를 자동으로 최적화하는 메타‑학습 기법, 그리고 교사 모델 자체를 더 강력한 사전 학습 모델(예: 대규모 사전 학습된 음향 모델)로 교체하는 방법 등을 고려할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기