대화 전사에서 단어 중요도 모델링을 위한 새로운 코퍼스
초록
본 논문은 Switchboard 대화 전사에 각 단어의 의미적 중요도를 0‑1 사이의 연속 점수로 주석 달아 만든 코퍼스를 소개한다. 인간 주석자 간의 일치도(ρc = 0.89)를 확보했으며, 이를 활용해 양방향 LSTM‑CRF와 LSTM‑SIG 모델을 학습시켰다. 최고 성능 모델은 6‑클래스 분류에서 F1 = 0.60, 인간‑모델 간 concordance correlation coefficient = 0.839를 기록한다. 이 자원은 ASR 캡션 품질을 기존 WER보다 실사용자 관점에서 평가하는 새로운 메트릭 개발에 활용될 예정이다.
상세 분석
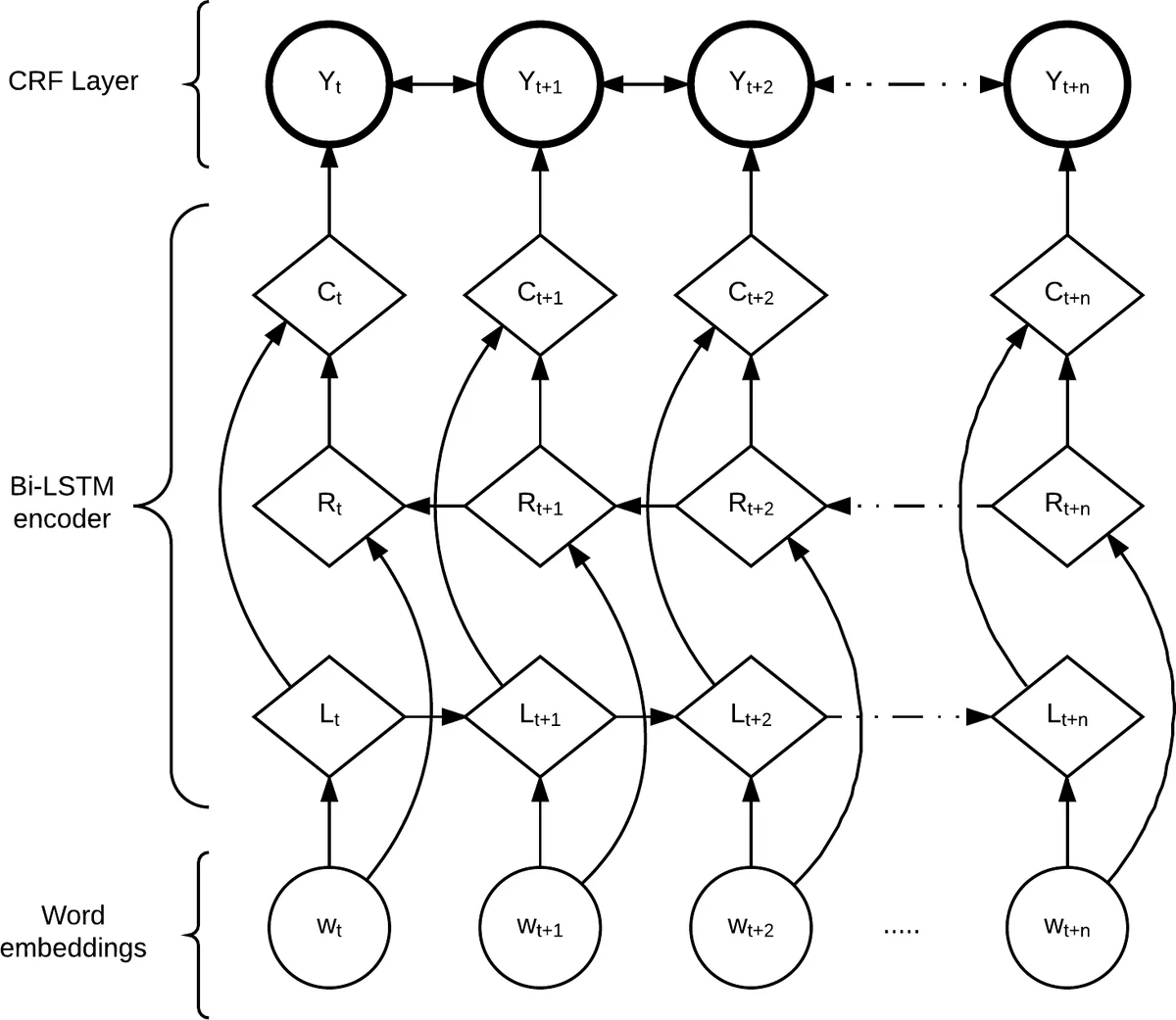
이 연구는 두 가지 핵심 기여를 가진다. 첫째, 대화형 음성 데이터에 대한 ‘단어 중요도’라는 새로운 라벨링 스키마를 정의하고, 이를 실질적인 주석 작업으로 구현했다. 중요도는 “해당 단어가 없으면 청자가 발화의 전체 의미를 이해하기 어려워지는 정도”로 정의했으며, 0.05 단위의 연속 점수(0‑1)로 표기한다. 주석자는 발화 전체와 전후 문맥을 고려해 각 단어를 평가했으며, 3,100개의 중복 토큰을 통해 두 명의 주석자 간 concordance correlation coefficient(ρc) = 0.89라는 높은 일관성을 보였다. 이는 주관적 판단이 요구되는 작업임에도 불구하고, 명확한 가이드라인(범위·해석·점수 부여 절차)과 사전 훈련된 어휘·문맥 정보를 활용해 신뢰할 수 있는 라벨을 확보했음을 의미한다.
둘째, 구축된 코퍼스를 바탕으로 두 종류의 딥러닝 모델을 설계·평가했다. 기본 구조는 사전 학습된 GloVe 임베딩과 문자‑레벨 CNN을 결합한 단어 표현을 입력으로 하는 양방향 LSTM이다. LSTM‑CRF는 각 단어를 6개의 비순서형 클래스(
댓글 및 학술 토론
Loading comments...
의견 남기기