이미지 기반 자율주행을 위한 강화학습과 모방학습 결합
초록
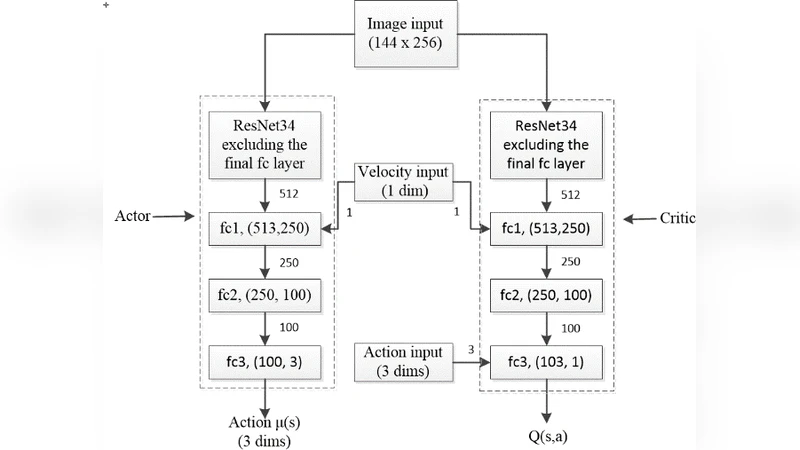
본 논문은 카메라 이미지와 차량 속도를 입력으로 받아 스로틀·브레이크·조향을 연속적·결정적으로 출력하는 자율주행 정책을 학습하는 파이프라인을 제안한다. AirSim 시뮬레이터의 다양한 날씨·조명 조건을 활용해 데이터 다양성을 확보하고, ResNet‑34 기반의 actor‑critic 네트워크를 설계한다. 인간 운전 데이터를 이용한 모방학습(Imitation Learning)으로 초기 정책을 학습한 뒤, 이를 가중치 초기값으로 사용해 DDPG 기반 강화학습을 진행한다. 실험 결과, 순수 모방학습이나 순수 DDPG에 비해 두 단계 결합 방식이 성능과 안정성에서 현저히 우수함을 확인하였다.
상세 분석
이 연구는 이미지 기반 자율주행이라는 고차원 연속 제어 문제에 대해 두 가지 학습 패러다임을 효과적으로 통합한다는 점에서 의미가 크다. 먼저, AirSim 시뮬레이터의 풍부한 날씨·조명 API를 활용해 다양한 환경을 시뮬레이션함으로써 도메인 차이에 대한 일반화 능력을 사전에 강화한다. 이는 실제 도로에서 조명 변화나 기상 조건에 따른 정책의 취약점을 완화하는 데 기여한다. 네트워크 구조는 ResNet‑34를 기반으로 하여 이미지 특징 추출에 강점을 살리면서, fully‑connected 레이어를 조정해 연속적인 제어값(스 로틀, 브레이크, 조향)을 직접 출력하도록 설계하였다. 여기서 중요한 점은 deterministic policy를 채택해 행동의 연속성을 보장하고, DDPG와 같은 off‑policy 알고리즘과 자연스럽게 결합할 수 있다는 것이다.
모방학습 단계에서는 인간 운전 데이터(이미지, 속도, 조작값)를 이용해 행동 클론을 학습한다. 이 단계는 초기 정책이 무작위 탐색에 의존하지 않도록 하여 학습 초기의 불안정성을 크게 감소시킨다. 특히, 인간 운전자의 고수준 전략(예: 코너링 시 스로틀 조절)을 그대로 반영함으로써 정책이 기본적인 주행 규칙을 이미 내재하게 만든다. 이후 DDPG 단계에서는 이 사전 학습된 정책을 초기 가중치로 사용해 환경 보상에 따라 미세 조정을 수행한다. 여기서 DDPG의 actor‑critic 구조는 연속 제어에 적합하고, replay buffer를 통해 과거 경험을 재활용함으로써 샘플 효율성을 높인다.
실험 결과는 세 가지 비교군(순수 모방학습, 순수 DDPG, 제안된 두 단계 결합) 간의 성능 차이를 명확히 보여준다. 제안 방법은 주행 성공률, 평균 보상, 충돌 횟수 등 주요 지표에서 현저히 우수했으며, 특히 복잡한 날씨·조명 조건에서의 견고성이 두드러졌다. 이는 모방학습이 제공하는 초기 정책의 품질과 DDPG가 제공하는 보상 기반 미세 조정이 상호 보완적으로 작용했기 때문이다. 또한, ablation study를 통해 ResNet‑34 대신 얕은 CNN을 사용했을 때 성능이 급격히 저하되는 것을 확인함으로써 깊은 특징 추출기의 중요성을 강조한다.
한계점으로는 시뮬레이션-실제 간 격차(gap)를 완전히 해소하지 못했으며, 인간 데이터의 품질과 양에 크게 의존한다는 점을 들 수 있다. 향후 연구에서는 도메인 적응 기법이나 실제 도로 데이터와의 혼합 학습을 통해 시뮬레이션 의존성을 줄이고, 멀티‑모달 센서(라이다, 레이더)와의 융합을 탐색할 여지가 있다. 전반적으로 이 논문은 이미지 기반 자율주행에서 모방학습과 강화학습을 순차적으로 적용함으로써 학습 효율성과 정책 견고성을 동시에 향상시킨 실용적인 접근법을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기