데이터 증강과 다중 분류기를 활용한 음향 장면 모델링
초록
본 논문은 DCASE2019 TASK1A에서 85 % 이상의 정확도를 달성하기 위해 GAN 기반 데이터 증강과 두 종류의 특징(멜 필터뱅크와 스칼로그램)을 결합한 1D‑DCNN 및 2D‑FCNN 분류기를 제안한다. 또한 도시 적응, DCT 기반 시간 모듈, 인셉션‑LSTM/GRU 하이브리드 등 다양한 부가 기법을 적용해 다중 모델을 앙상블하고, 가중 평균 투표로 최종 성능을 끌어올렸다.
상세 분석
이 연구는 크게 네 가지 핵심 요소로 구성된다. 첫 번째는 데이터 증강을 위한 조건부 GAN(ACGAN)과 변분 오토인코더‑조건부 GAN(CV AE/ACGAN)이다. 기존 GAN이 가우시안 잡음만을 입력으로 사용해 생성 샘플의 다양성이 제한되는 점을 보완하기 위해, 인코더가 실제 데이터의 분포를 학습하도록 KL 손실을 추가하고, 재구성 손실을 통해 고차원 특징을 보존한다. 이렇게 얻은 가짜 스펙트로그램은 도시별 서브셋에서 검증 후 데이터베이스에 병합되며, 실제 테스트 환경에서의 일반화 향상에 크게 기여한다.
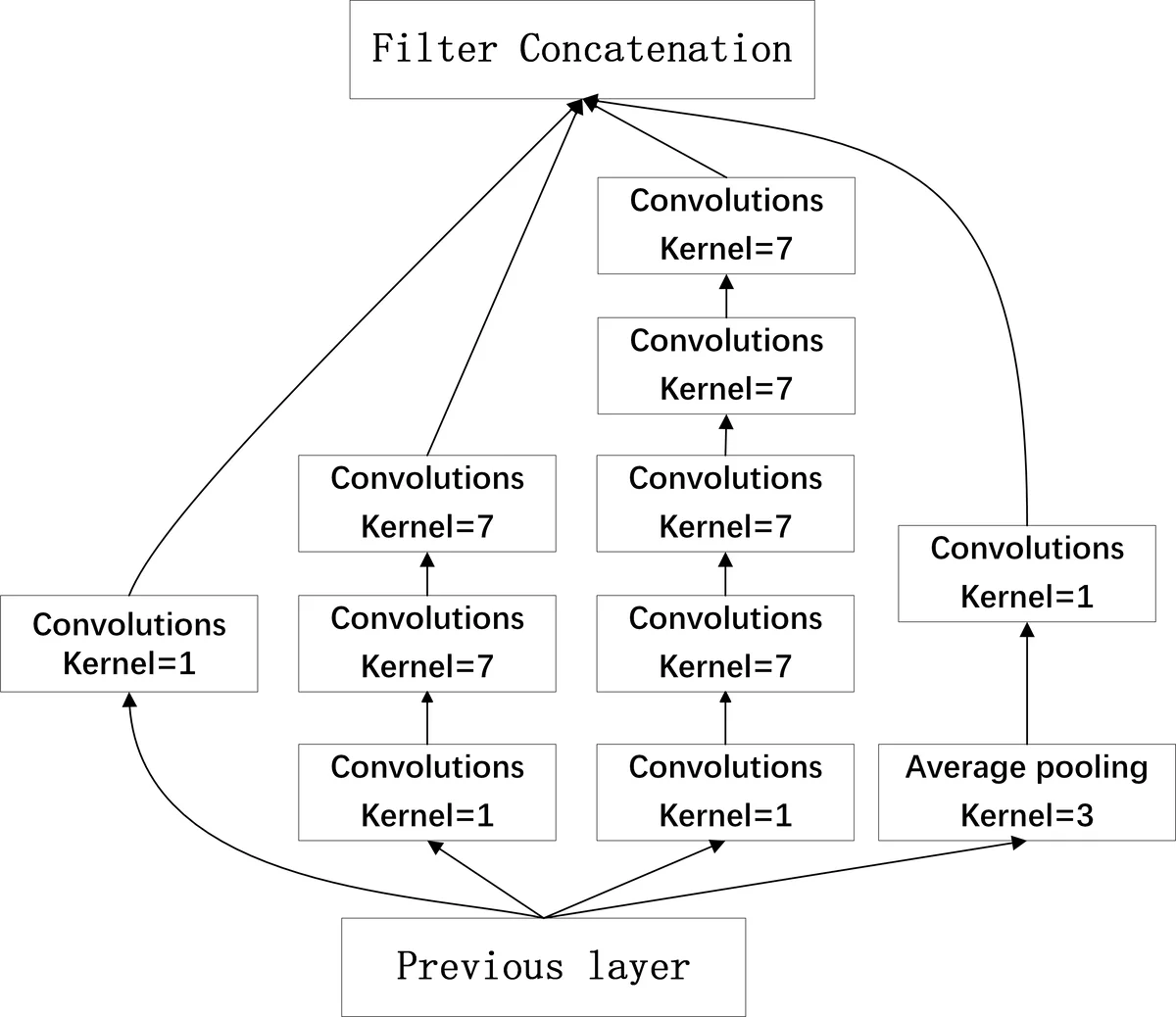
두 번째는 두 종류의 입력 특징과 네트워크 구조이다. 멜 필터뱅크(FBank)는 2‑D 형태의 스펙트로그램에 VGG‑스타일 10계층 컨볼루션을 적용한 FCNN으로 처리한다. 이때 배치 정규화·드롭아웃·ReLU를 적절히 배치해 과적합을 방지하고, 최종 1×1 컨볼루션과 글로벌 평균 풀링으로 10‑클래스 소프트맥스를 구현한다. 반면 스칼로그램은 웨이브렛 기반 시간‑주파수 변환으로 얻어지며, 1‑D 컨볼루션을 중심으로 설계된 DCNN에 전결합 레이어를 연결한다. 스칼로그램은 시간 왜곡에 강인하고 지역적 이동 불변성을 갖기 때문에, 특히 장면 간 미세한 음향 차이를 포착하는 데 유리하다.
세 번째는 부가적인 적응 및 시간 모듈이다. 도시 적응(adversarial city adaptation)은 그래디언트 역전 레이어와 2‑계층 도시 분류기를 삽입해, 컨볼루션 특징이 도시 도메인에 무관하도록 학습한다. 이는 훈련 데이터에 포함되지 않은 새로운 도시에서의 성능 저하를 완화한다. 또한 DCT 기반 시간 모듈은 프레임‑와이즈 출력에 주파수‑도메인 가중치를 부여해 장기적 패턴을 보강한다. 이때 가중치는 어텐션 메커니즘으로 학습되어, 중요한 DCT 계수를 강조하고 불필요한 잡음은 억제한다.
네 번째는 하이브리드 인셉션 구조와 순환 레이어의 결합이다. 인셉션 모듈 I·II를 기존 DCNN의 마지막 두 컨볼루션 층에 삽입해 폭넓은 receptive field를 확보하면서 파라미터 수는 크게 늘리지 않는다. 추가로 LSTM·GRU 병렬 채널을 도입해 시퀀스 정보를 직접 모델링함으로써, 순수 1‑D 컨볼루션이 놓칠 수 있는 장기 의존성을 보완한다. 그러나 실험 결과 하이브리드 모델은 기본 스칼로그램‑DCNN보다 큰 이득을 보이지 않았으며, 오히려 복잡도 증가로 인한 학습 불안정성이 관찰되었다.
앙상블 단계에서는 7~9개의 개별 모델을 평균 투표와 가중 투표 두 방식으로 결합했다. 가중치는 fold 1 검증 세트에서 최적화했으며, 가중 투표가 평균 투표보다 약 0.1 % 정도 높은 정확도를 기록했다. 최종 Fusion A‑D 시스템은 85.07 %~85.28 %의 정확도를 달성했으며, 이는 데이터 증강과 스칼로그램 기반 모델이 가장 큰 기여를 했음을 시사한다.
전체적으로 이 논문은 (1) 조건부 GAN을 이용한 효율적인 데이터 증강, (2) 멜‑필터뱅크와 스칼로그램이라는 상보적 특징 활용, (3) 도시 적응 및 DCT 시간 모듈을 통한 도메인 일반화, (4) 다중 모델 앙상블을 통한 성능 안정화라는 네 축을 체계적으로 결합함으로써, DCASE2019 ASC 과제에서 경쟁력 있는 결과를 얻었다는 점이 가장 큰 공헌이다.
댓글 및 학술 토론
Loading comments...
의견 남기기