음식 컴퓨팅 종합 조사
초록
본 논문은 급증하는 대규모 음식 데이터와 최신 인공지능 기술을 활용해 ‘음식 컴퓨팅’이라는 새로운 학문 영역을 정의하고, 데이터 수집·분석 방법, 주요 연구 과제(인식, 검색, 추천, 예측·모니터링) 및 응용 분야(건강, 문화, 농업, 의학)를 체계적으로 정리한다. 또한 현재 직면한 기술·데이터·윤리적 과제와 향후 연구 방향을 제시한다.
상세 분석
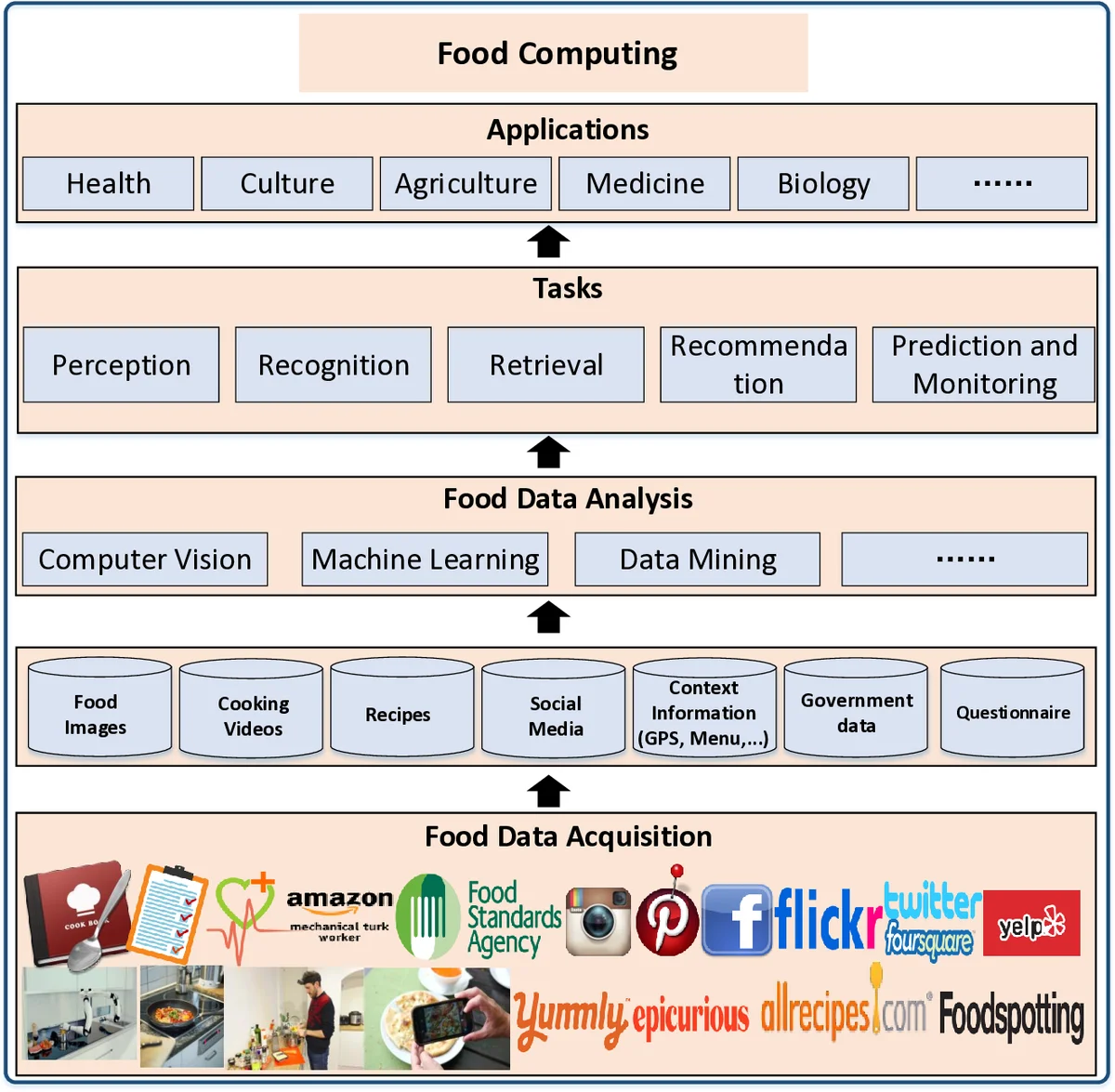
이 논문은 음식 컴퓨팅을 “이질적인 음식 데이터를 획득·분석하여 인간 중심의 서비스(건강 관리, 행동 유도, 문화 이해 등)를 제공하는 다학제적 분야”로 정의한다. 데이터 소스는 전통적인 기관·전문가, 레시피 공유 사이트, 소셜 미디어, IoT 센서, 크라우드소싱 등 다섯 가지로 구분되며, 각각의 특성(예: 이미지·텍스트·영양 정보·위치 데이터)과 수집·전처리 방법을 상세히 비교한다. 주요 연구 과제로는 (1) 음식 인식: 딥러닝 기반 이미지 분류·다중 라벨링, 재료 추출, 영양 성분 예측 등; (2) 음식 검색: 단일·다중 모달 검색, 이미지‑레시피 매핑, 교차 모달 임베딩; (3) 음식 추천: 개인화된 식단·레시피 추천, 건강 목표와 문화적 선호를 동시에 고려한 다목적 모델; (4) 예측·모니터링: 소셜 미디어 트렌드 분석을 통한 공중 보건 감시, 개인 식사 패턴 추적, 질병 위험 예측 등. 각 과제는 서로 연관되어 예를 들어 인식 결과가 검색·추천에 활용되고, 예측 모델이 추천 시스템의 피드백 루프를 형성한다. 기술적 도전으로는 데이터 라벨링 비용, 클래스 불균형, 멀티모달 정합성, 실시간 처리 요구, 프라이버시·윤리 문제 등을 꼽는다. 향후 연구는 (i) 대규모 고품질 라벨 데이터 구축, (ii) 멀티모달·멀티태스크 학습 프레임워크 개발, (iii) 도메인 적응 및 설명 가능한 AI 적용, (iv) 표준화된 평가 지표와 베이스라인 공유, (v) 정책·법적 프레임워크와 윤리 가이드라인 정립을 강조한다. 전체적으로 음식 컴퓨팅이 데이터 과학, 컴퓨터 비전, 자연어 처리, 인간 행동 과학을 융합해 식품 산업·보건·문화 전반에 혁신을 가져올 잠재력을 갖춘 신흥 분야임을 설득력 있게 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기