연속시간 마코프 의사결정 과정에서 제어된 관측 최적화
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 연속시간 할인형 점프 마코프 의사결정 과정(MDP)에서 관측 시점을 제어 변수로 포함시켜, 관측 시점 선택과 행동 제어를 동시에 최적화하는 이론적 프레임워크를 제시한다. 게이트형 대기열과 포아송 도착 재고관리 두 사례를 통해 최적 관측 정책과 최적 제어 정책을 분석·수치화한다.
상세 분석
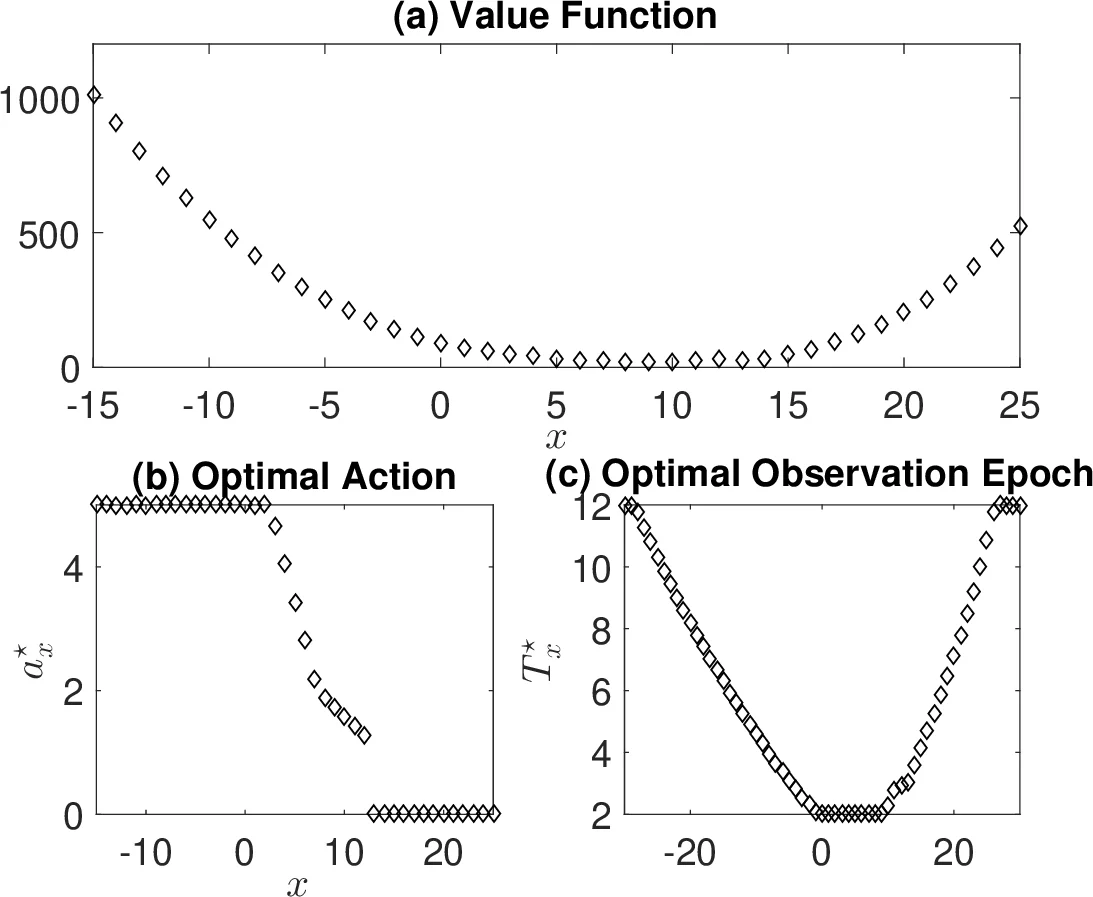
이 연구는 기존 MDP가 연속적인 상태 관측을 전제로 하는 한계를 넘어, 관측 자체가 비용을 발생시키는 상황을 모델링한다는 점에서 혁신적이다. 저자들은 연속시간 점프 마코프 과정에 대해 상태 전이율 λₓ와 전이 확률 q(x′|x,a)를 정의하고, 관측 간격 Tₓ를 제어 변수로 두어 “관측-제어” 쌍 (aₓ(·), Tₓ) 를 정책의 기본 단위로 설정한다. 이렇게 하면 각 관측 구간은 하나의 “통합 유틸리티” (\bar r(x,a(·),T)) 로 요약될 수 있으며, 할인 인자 β와 관측 비용 g(T)를 포함한 총 비용은 이산시간 MDP 형태로 전환된다. 핵심은 동적계획 방정식
\
댓글 및 학술 토론
Loading comments...
의견 남기기